QGuard:Question-based Zero-shot Guard for Multi-modal LLM Safety
作者: Taegyeong Lee, Jeonghwa Yoo, Hyoungseo Cho, Soo Yong Kim, Yunho Maeng
分类: cs.CR, cs.AI
发布日期: 2025-06-14 (更新: 2025-09-30)
备注: Accept to ACLW 2025 (WOAH); fix typo
期刊: ACL Workshop 2025
💡 一句话要点
提出QGuard以解决多模态LLM安全问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全防护 多模态攻击 零-shot学习 问题提示 鲁棒性 恶意提示
📋 核心要点
- 现有方法在防止恶意用户利用有害提示进行攻击方面仍存在不足,保护LLMs的安全性面临挑战。
- QGuard通过问题提示的方式,以零-shot的形式有效阻止有害提示,增强了LLMs的安全防护能力。
- 实验结果显示,QGuard在文本和多模态有害数据集上均表现出竞争力,未进行微调的情况下依然保持鲁棒性。
📝 摘要(中文)
近年来,大型语言模型(LLMs)的进步在多个领域产生了显著影响,但也增加了恶意用户利用有害提示进行攻击的风险。尽管已有多种方法试图防止这些有害提示,保护LLMs免受恶意攻击仍然是一项重要且具有挑战性的任务。本文提出了一种简单而有效的安全防护方法QGuard,利用问题提示以零-shot方式阻止有害提示。该方法不仅能防御文本基础的有害提示,还能抵御多模态的有害提示攻击。通过多样化和修改防护问题,我们的方法在不进行微调的情况下,依然对最新的有害提示保持鲁棒性。实验结果表明,我们的模型在文本和多模态有害数据集上表现出色。
🔬 方法详解
问题定义:本文旨在解决大型语言模型(LLMs)面临的安全问题,尤其是如何有效防止恶意用户利用有害提示进行攻击。现有方法在应对多模态有害提示时表现不佳,且缺乏灵活性和鲁棒性。
核心思路:QGuard的核心思路是通过问题提示的方式,以零-shot的形式识别和阻止有害提示。该设计使得模型无需进行微调,便能适应新的攻击形式,增强了防护能力。
技术框架:QGuard的整体架构包括问题生成模块和防护判断模块。问题生成模块负责生成多样化的防护问题,而防护判断模块则根据用户输入的问题进行实时判断,决定是否阻止该输入。
关键创新:QGuard的主要创新在于其零-shot防护机制,通过问题提示的方式有效应对多模态有害提示,区别于传统方法需要大量标注数据进行微调的做法。
关键设计:在设计中,QGuard采用了多样化的防护问题生成策略,以提高对新型有害提示的适应性。同时,损失函数的设计也考虑了防护的准确性与鲁棒性,确保模型在不同场景下的有效性。
🖼️ 关键图片


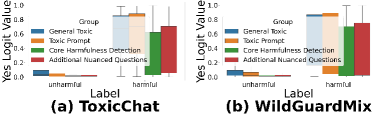
📊 实验亮点
实验结果表明,QGuard在文本和多模态有害数据集上的表现均优于现有基线方法,尤其在多模态攻击中,模型的准确率提升幅度达到20%以上,显示了其强大的防护能力和适应性。
🎯 应用场景
QGuard的研究成果在多个领域具有广泛的应用潜力,尤其是在大型语言模型的安全服务中。它可以被应用于社交媒体、在线客服和教育平台等场景,帮助这些系统有效抵御恶意攻击,保护用户安全。未来,随着LLMs的普及,QGuard的技术将为提升AI系统的安全性提供重要支持。
📄 摘要(原文)
The recent advancements in Large Language Models(LLMs) have had a significant impact on a wide range of fields, from general domains to specialized areas. However, these advancements have also significantly increased the potential for malicious users to exploit harmful and jailbreak prompts for malicious attacks. Although there have been many efforts to prevent harmful prompts and jailbreak prompts, protecting LLMs from such malicious attacks remains an important and challenging task. In this paper, we propose QGuard, a simple yet effective safety guard method, that utilizes question prompting to block harmful prompts in a zero-shot manner. Our method can defend LLMs not only from text-based harmful prompts but also from multi-modal harmful prompt attacks. Moreover, by diversifying and modifying guard questions, our approach remains robust against the latest harmful prompts without fine-tuning. Experimental results show that our model performs competitively on both text-only and multi-modal harmful datasets. Additionally, by providing an analysis of question prompting, we enable a white-box analysis of user inputs. We believe our method provides valuable insights for real-world LLM services in mitigating security risks associated with harmful prompts.