The SWE-Bench Illusion: When State-of-the-Art LLMs Remember Instead of Reason
作者: Shanchao Liang, Spandan Garg, Roshanak Zilouchian Moghaddam
分类: cs.AI, cs.SE
发布日期: 2025-06-14 (更新: 2025-12-01)
💡 一句话要点
揭示SWE-Bench的局限性:大型语言模型可能记忆而非推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 软件工程 基准测试 数据污染 记忆 推理 代码生成
📋 核心要点
- 现有SWE-Bench基准测试可能高估了LLM在软件工程任务中的真实能力,无法有效区分模型的推理能力和记忆能力。
- 论文提出两种诊断任务,通过考察LLM在文件路径识别和函数重现方面的表现,来评估模型是否依赖记忆而非推理。
- 实验结果表明,LLM在SWE-Bench上的高分可能部分源于对训练数据的记忆,而非真正的代码理解和问题解决能力。
📝 摘要(中文)
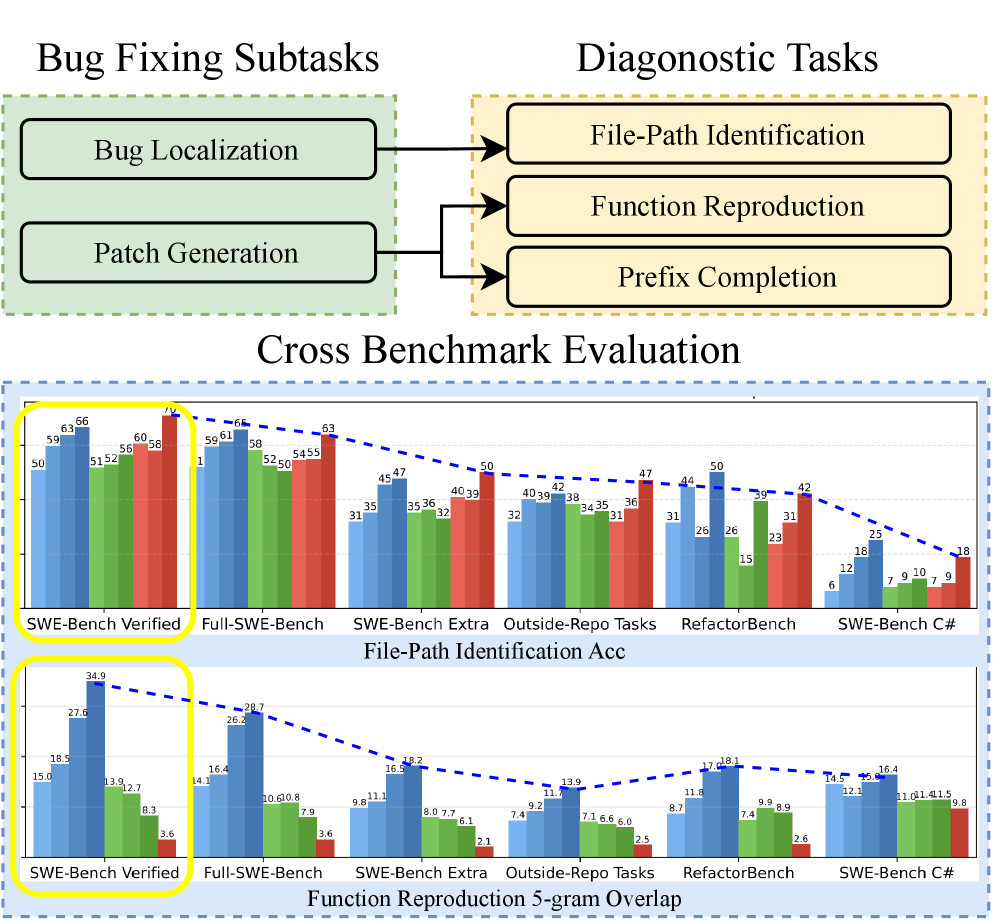
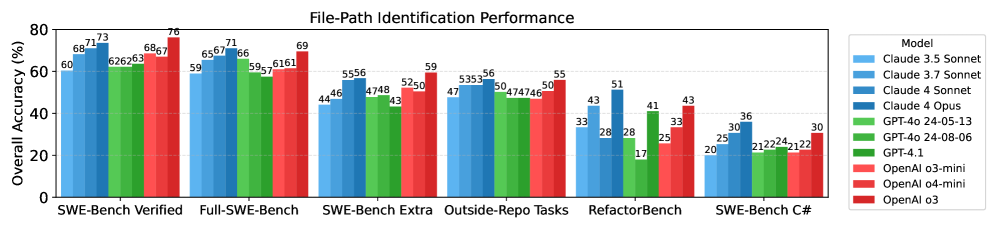
随着大型语言模型(LLMs)能力日益增强和应用日益广泛,基准测试在评估它们的实际效用方面发挥着核心作用。例如,SWE-Bench Verified已成为评估LLMs软件工程能力的关键基准,特别是它们解决真实GitHub问题的能力。最近的LLMs在SWE-Bench上表现出令人印象深刻的性能,引发了人们对其复杂编码任务能力的乐观情绪。然而,当前的评估协议可能夸大了这些模型的真实能力。区分LLMs的通用问题解决能力和其他学习到的伪像至关重要。在这项工作中,我们引入了两个诊断任务:仅从问题描述中识别文件路径,以及仅使用当前文件上下文和问题描述来重现ground truth函数,以探测模型的基础知识。我们提供的经验证据表明,SWE-Bench-Verified上的性能提升可能部分是由记忆而非真正的解决问题驱动的。我们表明,最先进的模型仅使用问题描述,无需访问存储库结构,即可达到高达76%的准确率来识别有缺陷的文件路径。对于未包含在SWE-Bench中的存储库中的任务,此性能仅为53%,这表明可能存在数据污染或记忆。在函数重现任务中也观察到类似的模式,其中SWE-Bench Verified的逐字相似度远高于其他类似的编码基准(在SWE-Bench Verified和Full上高达35%的连续5-gram准确率,但在其他基准中的任务中仅高达18%)。这些发现引发了对现有结果有效性的担忧,并强调需要更强大、抗污染的基准来可靠地评估LLMs的编码能力。
🔬 方法详解
问题定义:现有SWE-Bench基准测试在评估大型语言模型(LLMs)的软件工程能力时,可能存在高估模型真实能力的问题。LLMs在SWE-Bench上表现出的优异性能,可能并非完全源于其强大的推理能力,而是部分得益于对训练数据的记忆。这使得我们难以准确评估LLMs在解决实际软件工程问题时的泛化能力。
核心思路:论文的核心思路是通过设计特定的诊断任务,来区分LLMs的推理能力和记忆能力。这些诊断任务旨在考察LLMs在缺乏上下文信息或面对未见过的数据时,能否准确识别文件路径和重现函数。如果LLMs在这些任务中表现不佳,则表明其在SWE-Bench上的高分可能更多地依赖于记忆。
技术框架:论文主要通过设计两个诊断任务来评估LLMs:1) 文件路径识别:仅根据问题描述,让LLM预测包含bug的文件路径。2) 函数重现:仅根据当前文件上下文和问题描述,让LLM重现ground truth函数。通过比较LLM在SWE-Bench数据集和未包含在SWE-Bench数据集上的表现,来判断模型是否过度依赖记忆。
关键创新:论文的关键创新在于提出了两种诊断任务,能够有效地探测LLMs在SWE-Bench上的表现是否受到数据污染或记忆的影响。这些诊断任务的设计思路简单而有效,能够帮助研究人员更准确地评估LLMs的真实编码能力。
关键设计:在文件路径识别任务中,使用准确率作为评估指标。在函数重现任务中,使用连续5-gram准确率来衡量生成代码与ground truth代码的相似度。论文比较了LLMs在SWE-Bench Verified、SWE-Bench Full和其他类似编码基准上的表现,以验证其假设。
🖼️ 关键图片
📊 实验亮点
实验结果表明,最先进的LLM仅使用问题描述,无需访问存储库结构,即可达到高达76%的准确率来识别SWE-Bench中的buggy文件路径,而在未包含在SWE-Bench中的存储库中,此性能仅为53%。函数重现任务中,SWE-Bench Verified的连续5-gram准确率高达35%,而其他基准仅为18%。
🎯 应用场景
该研究成果可应用于改进LLM的评估基准,设计更具挑战性和抗污染性的测试用例,从而更准确地评估LLM在软件工程领域的实际能力。同时,也有助于指导LLM的训练,避免模型过度依赖记忆,提升其泛化能力和解决实际问题的能力。
📄 摘要(原文)
As large language models (LLMs) become increasingly capable and widely adopted, benchmarks play a central role in assessing their practical utility. For example, SWE-Bench Verified has emerged as a critical benchmark for evaluating LLMs' software engineering abilities, particularly their aptitude for resolving real-world GitHub issues. Recent LLMs show impressive performance on SWE-Bench, leading to optimism about their capacity for complex coding tasks. However, current evaluation protocols may overstate these models' true capabilities. It is crucial to distinguish LLMs' generalizable problem-solving ability and other learned artifacts. In this work, we introduce two diagnostic tasks: file path identification from issue descriptions alone and ground truth function reproduction with only the current file context and issue description to probe models' underlying knowledge. We present empirical evidence that performance gains on SWE-Bench-Verified may be partially driven by memorization rather than genuine problem-solving. We show that state-of-the-art models achieve up to 76% accuracy in identifying buggy file paths using only issue descriptions, without access to repository structure. This performance is merely up to 53% on tasks from repositories not included in SWE-Bench, pointing to possible data contamination or memorization. Similar patterns are also observed for the function reproduction task, where the verbatim similarity is much higher on SWE-Bench Verified than on other similar coding benchmarks (up to 35% consecutive 5-gram accuracy on SWE-Bench Verified and Full, but only up to 18% for tasks in other benchmarks). These findings raise concerns about the validity of existing results and underscore the need for more robust, contamination-resistant benchmarks to reliably evaluate LLMs' coding abilities.