The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
作者: Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, Mehrdad Farajtabar
分类: cs.AI, cs.CL, cs.LG
发布日期: 2025-06-07 (更新: 2025-11-20)
备注: NeurIPS 2025. camera-ready version + additional discussion in the appendix
💡 一句话要点
通过问题复杂度分析,揭示推理模型的能力边界与局限性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 大型推理模型 问题复杂度 推理过程分析 可控环境 能力边界
📋 核心要点
- 现有推理模型评估侧重于最终答案准确性,忽略了推理过程,且易受数据污染,难以深入理解模型能力。
- 论文提出利用可控的谜题环境,通过操纵问题复杂度,分析推理过程,从而更全面地评估大型推理模型。
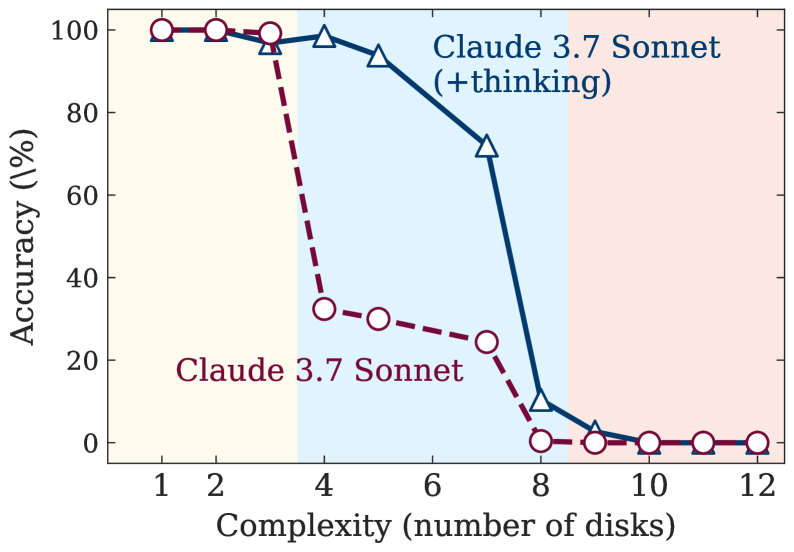
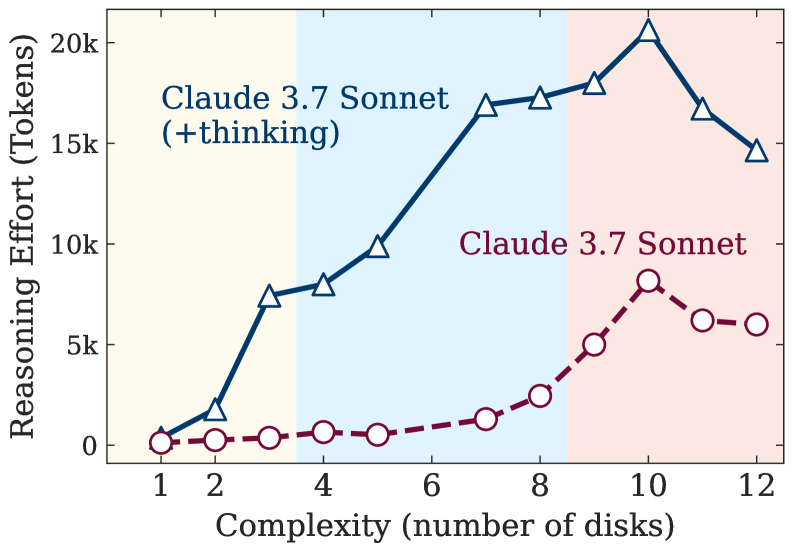
- 实验表明,大型推理模型在特定复杂度后性能崩溃,且推理努力与问题复杂度并非线性相关,存在缩放限制。
📝 摘要(中文)
最新一代的语言模型引入了大型推理模型(LRM),它们在给出答案之前会生成详细的思考过程。尽管这些模型在推理基准测试中表现出改进的性能,但其基本能力、扩展属性和局限性仍未得到充分理解。目前的评估主要集中在已建立的数学和编码基准上,强调最终答案的准确性。然而,这种评估范式通常受到污染,并且不能提供对推理过程的深入了解。在这项工作中,我们借助可控的谜题环境系统地研究了这些差距,这些环境允许精确地操纵复杂性,同时保持一致的逻辑结构。这种设置不仅可以分析最终答案,还可以分析内部推理过程,从而深入了解LRM的思考方式。通过大量的实验,我们表明LRM在超过一定复杂性后会面临完全的准确性崩溃。此外,它们表现出一种违反直觉的缩放限制:它们的推理工作随着问题复杂性的增加而增加,直到某个点,然后下降,尽管有剩余的token预算。通过在相同的推理计算下将LRM与其标准LLM对应物进行比较,我们确定了三种性能状态:(1)标准模型优于LRM的低复杂性任务,(2)LRM表现出优势的中等复杂性任务,以及(3)两种模型都面临完全崩溃的高复杂性任务。我们发现LRM在精确计算方面存在局限性:它们无法使用显式算法,并且在不同尺度上推理不一致。我们还更深入地研究了推理过程,研究了探索的解决方案的模式,并分析了模型的计算行为,从而揭示了它们的优势、局限性,并提出了关于其推理能力的问题。
🔬 方法详解
问题定义:现有的大型推理模型(LRM)在复杂推理任务中表现出一定的能力,但对其内在机制和局限性的理解不足。现有的评估方法主要依赖于最终答案的准确性,忽略了推理过程,并且容易受到训练数据污染的影响。因此,难以准确评估LRM的真实推理能力,并发现其潜在的瓶颈。
核心思路:论文的核心思路是通过构建可控的谜题环境,精确地控制问题的复杂度,并同时分析模型的推理过程和最终答案。这种方法可以避免数据污染,并提供对模型推理过程的更深入的理解。通过系统地改变问题复杂度,可以观察模型在不同难度下的表现,从而揭示其能力边界和局限性。
技术框架:论文的技术框架主要包括以下几个部分:1) 构建可控的谜题环境,该环境允许精确地控制问题的复杂度,同时保持逻辑结构的一致性。2) 使用大型推理模型(LRM)和标准语言模型(LLM)解决这些谜题。3) 分析模型的推理过程,包括探索的解决方案的模式和计算行为。4) 比较LRM和LLM在不同复杂度下的性能,从而确定它们的优势和局限性。
关键创新:论文的关键创新在于使用可控的谜题环境来评估大型推理模型。这种方法可以避免数据污染,并提供对模型推理过程的更深入的理解。此外,论文还发现LRM在精确计算方面存在局限性,并且在不同尺度上推理不一致。
关键设计:论文的关键设计包括:1) 谜题环境的设计,需要保证问题复杂度可控,逻辑结构一致。2) 推理过程的分析方法,需要能够捕捉模型探索解决方案的模式和计算行为。3) LRM和LLM的对比实验,需要在相同的计算资源下进行,以保证公平性。论文中具体使用的模型架构、损失函数等技术细节未知。
🖼️ 关键图片
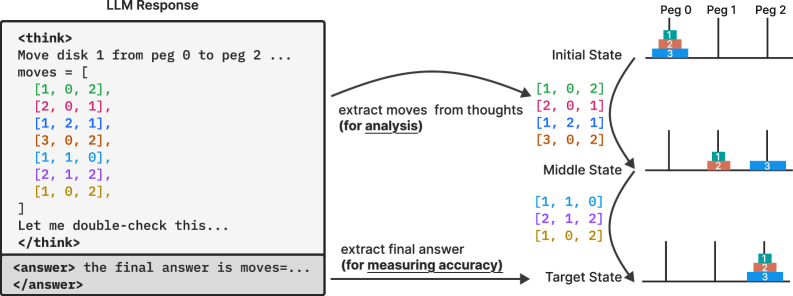
📊 实验亮点
实验表明,LRM在超过一定复杂度后会面临完全的准确性崩溃。LRM的推理努力与问题复杂度并非线性相关,存在缩放限制,即推理工作量随复杂度增加到一定程度后反而下降。在低复杂度任务中,标准LLM甚至优于LRM,而在中等复杂度任务中,LRM才展现出优势。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的推理能力,指导模型设计和训练,并为开发更可靠、更高效的AI系统提供理论基础。此外,该研究方法也可推广到其他类型的推理任务和模型评估中。
📄 摘要(原文)
Recent generations of language models have introduced Large Reasoning Models (LRMs) that generate detailed thinking processes before providing answers. While these models demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scaling properties, and limitations remain insufficiently understood. Current evaluations primarily focus on established math and coding benchmarks, emphasizing final answer accuracy. However, this evaluation paradigm often suffers from contamination and does not provide insights into the reasoning traces. In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of complexity while maintaining consistent logical structures. This setup enables the analysis of not only final answers but also the internal reasoning traces, offering insights into how LRMs think. Through extensive experiments, we show that LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counterintuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having remaining token budget. By comparing LRMs with their standard LLM counterparts under same inference compute, we identify three performance regimes: (1) low-complexity tasks where standard models outperform LRMs, (2) medium-complexity tasks where LRMs demonstrates advantage, and (3) high-complexity tasks where both models face complete collapse. We found that LRMs have limitations in exact computation: they fail to use explicit algorithms and reason inconsistently across scales. We also investigate the reasoning traces in more depth, studying the patterns of explored solutions and analyzing the models' computational behavior, shedding light on their strengths, limitations, and raising questions about their reasoning capabilities.