VisioMath: Benchmarking Figure-based Mathematical Reasoning in LMMs
作者: Can Li, Ying Liu, Ting Zhang, Mei Wang, Hua Huang
分类: cs.AI, cs.CV
发布日期: 2025-06-07 (更新: 2025-10-07)
💡 一句话要点
VisioMath:提出用于评估LMMs在图表数学推理能力上的基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 图表推理 数学问题 基准测试 视觉相似性
📋 核心要点
- 现有LMMs在处理视觉上相似的图表推理方面存在不足,尤其是在需要细粒度比较的数学问题中。
- VisioMath基准测试通过提供包含细微视觉差异的图表数学问题,来评估和提升LMMs的推理能力。
- 实验表明,现有LMMs在VisioMath上表现不佳,主要原因是图像-文本未对齐,通过对齐策略可显著提升准确性。
📝 摘要(中文)
大型多模态模型在整合视觉和语言方面取得了显著进展,在感知、推理和特定领域任务中表现出强大的性能。然而,它们对多个视觉上相似的输入进行推理的能力仍未得到充分探索。这种细粒度的比较推理对于现实世界的任务至关重要,尤其是在数学和教育领域,学习者经常需要区分几乎相同的图表以识别正确的解决方案。为了解决这一差距,我们提出了VisioMath,这是一个精心策划的包含1800个高质量K-12数学问题的基准,其中所有候选答案都是具有细微视觉相似性的图表。对最先进的LMM的全面评估,涵盖了领先的闭源系统和广泛采用的开源模型,揭示了随着图像间相似性的增加,准确性持续下降。分析表明,主要的失败模式源于图像-文本未对齐:模型通常采用浅层的位置启发式方法,而不是将推理建立在文本线索上,从而导致系统性错误。我们进一步探索了三种面向对齐的策略,包括免训练方法和微调,并实现了显著的准确性提升。我们希望VisioMath将成为一个严格的基准和催化剂,用于开发LMM,使其能够更深入地理解图表、进行精确的比较推理以及进行基于基础的多图像-文本集成。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMMs)在基于图表的数学推理任务中,特别是当候选答案是视觉上高度相似的图表时,表现不佳的问题。现有方法往往无法进行细粒度的比较推理,容易受到图像-文本未对齐的影响,导致系统性错误。
核心思路:论文的核心思路是构建一个专门的基准测试数据集VisioMath,该数据集包含大量具有挑战性的K-12数学问题,这些问题的答案选项都是视觉上相似的图表。通过在这个数据集上评估LMMs的性能,可以更准确地衡量它们在图表推理方面的能力,并促进相关算法的改进。
技术框架:VisioMath基准测试包含1800个K-12数学问题,每个问题都包含一个问题描述和多个视觉上相似的图表作为候选答案。论文使用该数据集评估了多个最先进的LMMs,包括闭源模型和开源模型。此外,论文还探索了三种对齐策略,包括免训练方法和微调方法,以提高LMMs在VisioMath上的性能。
关键创新:VisioMath基准测试的主要创新在于其专注于评估LMMs在细粒度比较推理方面的能力,特别是当候选答案是视觉上高度相似的图表时。与现有的多模态基准测试相比,VisioMath更强调图像-文本对齐的重要性,并提供了一个更具挑战性的评估环境。
关键设计:VisioMath数据集中的问题涵盖了K-12数学的各个领域,并经过精心设计,以确保候选答案之间存在细微的视觉差异。论文探索的三种对齐策略包括:(1) 训练自由方法,例如提示工程;(2) 微调方法,使用VisioMath数据进行模型微调;(3) 结合图像和文本信息的更复杂的对齐模型。具体的参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
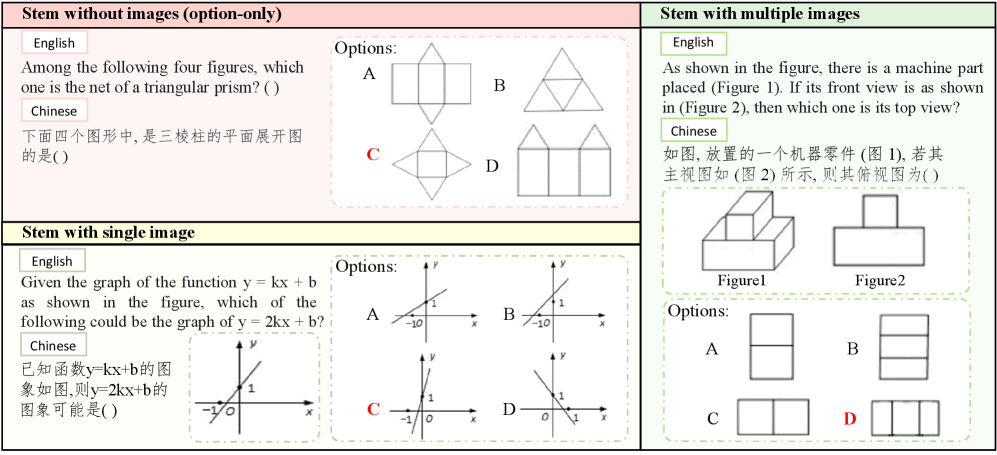

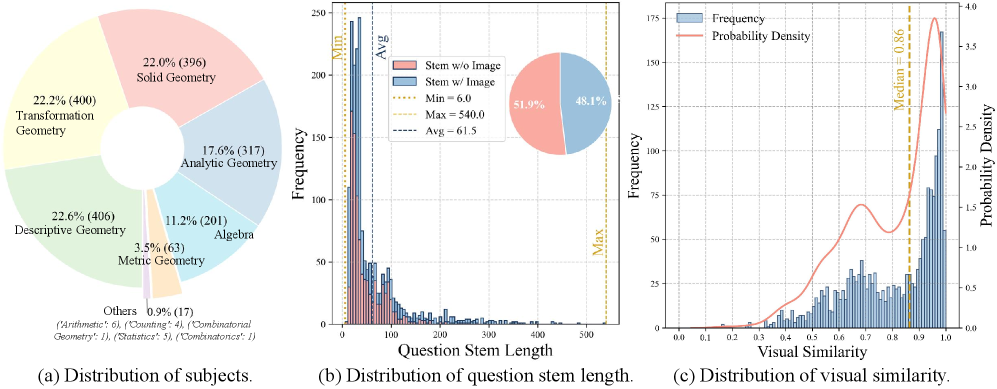
📊 实验亮点
实验结果表明,现有LMMs在VisioMath基准测试上的表现远低于人类水平,表明它们在图表推理方面存在显著不足。随着图像间相似性的增加,LMMs的准确性持续下降。通过采用对齐策略,LMMs在VisioMath上的准确性得到了显著提升,证明了图像-文本对齐对于提高图表推理能力的重要性。具体提升幅度未知。
🎯 应用场景
VisioMath的研究成果可应用于教育领域,例如智能辅导系统、自动阅卷系统等,帮助学生更好地理解数学概念,提高学习效率。此外,该研究还可以促进LMMs在其他需要细粒度视觉推理的领域的应用,例如医学图像分析、工业检测等。
📄 摘要(原文)
Large Multimodal Models have achieved remarkable progress in integrating vision and language, enabling strong performance across perception, reasoning, and domain-specific tasks. However, their capacity to reason over multiple, visually similar inputs remains insufficiently explored. Such fine-grained comparative reasoning is central to real-world tasks, especially in mathematics and education, where learners must often distinguish between nearly identical diagrams to identify correct solutions. To address this gap, we present VisioMath, a curated benchmark of 1,800 high-quality K-12 mathematics problems in which all candidate answers are diagrams with subtle visual similarities. A comprehensive evaluation of state-of-the-art LMMs, covering both leading closed-source systems and widely adopted open-source models, reveals a consistent decline in accuracy as inter-image similarity increases. Analysis indicates that the dominant failure mode stems from image-text misalignment: rather than grounding reasoning in textual cues, models often resort to shallow positional heuristics, resulting in systematic errors. We further explore three alignment-oriented strategies, spanning training-free approaches and finetuning, and achieve substantial accuracy gains. We hope that VisioMath will serve as a rigorous benchmark and catalyst for developing LMMs toward deeper diagram understanding, precise comparative reasoning, and grounded multi-image-text integration.