Optimizing RAG Pipelines for Arabic: A Systematic Analysis of Core Components
作者: Jumana Alsubhi, Mohammad D. Alahmadi, Ahmed Alhusayni, Ibrahim Aldailami, Israa Hamdine, Ahmad Shabana, Yazeed Iskandar, Suhayb Khayyat
分类: cs.IR, cs.AI, cs.CL
发布日期: 2025-06-01
💡 一句话要点
针对阿拉伯语,系统分析RAG Pipeline核心组件并优化性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RAG Pipeline 阿拉伯语 信息检索 语言模型 嵌入模型 重排序 RAGAS框架
📋 核心要点
- 现有RAG方法在阿拉伯语上的优化不足,面临分块、嵌入、重排序和生成等组件选择的挑战。
- 该研究系统评估了各种RAG组件在阿拉伯语数据集上的性能,旨在找到最佳组件组合。
- 实验结果表明,句子感知分块、BGE-M3/Multilingual-E5-large嵌入模型和bge-reranker-v2-m3重排序器能有效提升阿拉伯语RAG性能。
📝 摘要(中文)
检索增强生成(RAG)已成为结合检索系统精度与大型语言模型流畅性的强大架构。虽然已有研究探索了高资源语言的RAG Pipeline,但针对阿拉伯语的RAG组件优化仍未得到充分研究。本研究对最先进的RAG组件(包括分块策略、嵌入模型、重排序器和语言模型)进行了全面的实证评估,涵盖了多样化的阿拉伯语数据集。使用RAGAS框架,我们系统地比较了四个核心指标的性能:上下文精确度、上下文召回率、答案忠实度和答案相关性。实验表明,句子感知分块优于所有其他分割方法,而BGE-M3和Multilingual-E5-large是最有效的嵌入模型。包含重排序器(bge-reranker-v2-m3)显著提高了复杂数据集中答案的忠实度,并且Aya-8B在生成质量上超过了StableLM。这些发现为构建高质量的阿拉伯语RAG Pipeline提供了关键见解,并为跨不同文档类型选择最佳组件提供了实用指南。
🔬 方法详解
问题定义:论文旨在解决阿拉伯语RAG Pipeline中组件选择和优化的问题。现有方法在高资源语言上表现良好,但直接应用于阿拉伯语时效果不佳,原因在于阿拉伯语的语言特性以及缺乏针对阿拉伯语的RAG组件优化研究。因此,需要系统地评估各种RAG组件在阿拉伯语上的性能,并找到最佳组合。
核心思路:论文的核心思路是通过全面的实证评估,比较不同分块策略、嵌入模型、重排序器和语言模型在阿拉伯语数据集上的性能。通过RAGAS框架的四个核心指标(上下文精确度、上下文召回率、答案忠实度和答案相关性)来量化评估结果,从而为构建高质量的阿拉伯语RAG Pipeline提供指导。
技术框架:该研究采用标准的RAG Pipeline架构,主要包含以下几个阶段:1) 文档分块:使用不同的分块策略将文档分割成块。2) 嵌入:使用不同的嵌入模型将文本块转换为向量表示。3) 检索:根据用户查询,检索与查询相关的文本块。4) 重排序:使用重排序器对检索到的文本块进行排序,提高相关性。5) 生成:使用语言模型根据检索到的文本块生成答案。
关键创新:该研究最重要的创新点在于针对阿拉伯语RAG Pipeline的系统性评估。之前的研究主要集中在高资源语言上,而该研究首次全面地评估了各种RAG组件在阿拉伯语上的性能,并提供了针对阿拉伯语的优化建议。此外,该研究还发现了一些针对阿拉伯语的特定优化策略,例如句子感知分块的有效性。
关键设计:在实验设计方面,论文选择了多样化的阿拉伯语数据集,并使用RAGAS框架进行评估。RAGAS框架提供了四个核心指标,可以全面地评估RAG Pipeline的性能。在组件选择方面,论文考虑了各种主流的分块策略、嵌入模型、重排序器和语言模型。此外,论文还对不同的组件组合进行了评估,以找到最佳的RAG Pipeline配置。
🖼️ 关键图片
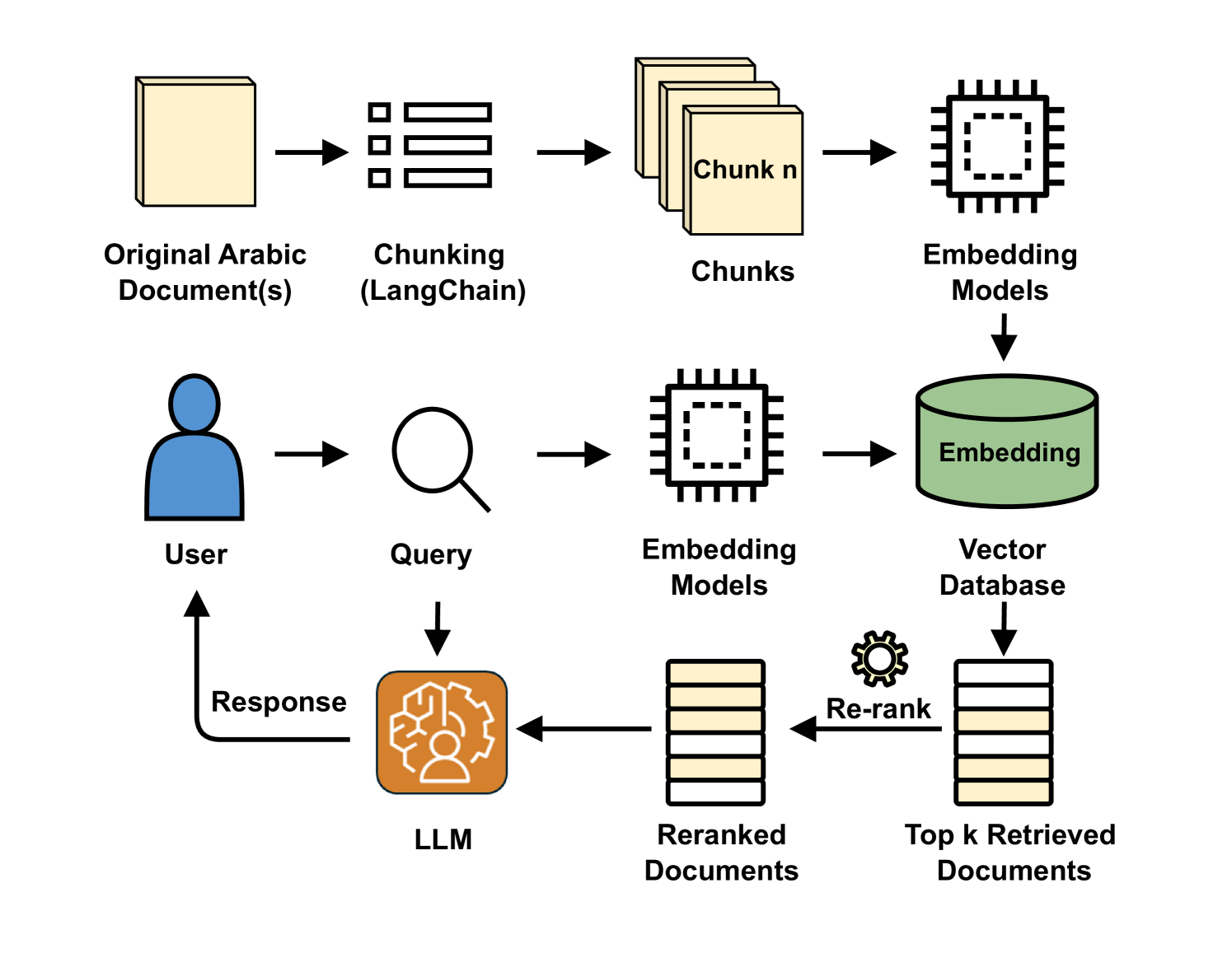
📊 实验亮点
实验结果表明,句子感知分块优于其他分块方法,BGE-M3和Multilingual-E5-large是最有效的嵌入模型。在复杂数据集中,使用bge-reranker-v2-m3重排序器能显著提高答案的忠实度。Aya-8B在生成质量上优于StableLM。这些发现为构建高性能的阿拉伯语RAG Pipeline提供了重要指导。
🎯 应用场景
该研究成果可应用于各种需要处理阿拉伯语文本的场景,例如智能客服、信息检索、文档摘要、机器翻译等。通过优化RAG Pipeline,可以提高这些应用在阿拉伯语上的性能,从而更好地服务于阿拉伯语用户。未来,该研究可以扩展到其他低资源语言,并探索更先进的RAG技术。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) has emerged as a powerful architecture for combining the precision of retrieval systems with the fluency of large language models. While several studies have investigated RAG pipelines for high-resource languages, the optimization of RAG components for Arabic remains underexplored. This study presents a comprehensive empirical evaluation of state-of-the-art RAG components-including chunking strategies, embedding models, rerankers, and language models-across a diverse set of Arabic datasets. Using the RAGAS framework, we systematically compare performance across four core metrics: context precision, context recall, answer faithfulness, and answer relevancy. Our experiments demonstrate that sentence-aware chunking outperforms all other segmentation methods, while BGE-M3 and Multilingual-E5-large emerge as the most effective embedding models. The inclusion of a reranker (bge-reranker-v2-m3) significantly boosts faithfulness in complex datasets, and Aya-8B surpasses StableLM in generation quality. These findings provide critical insights for building high-quality Arabic RAG pipelines and offer practical guidelines for selecting optimal components across different document types.