Improving LLM Agents with Reinforcement Learning on Cryptographic CTF Challenges
作者: Lajos Muzsai, David Imolai, András Lukács
分类: cs.CR, cs.AI
发布日期: 2025-06-01 (更新: 2025-08-17)
备注: 13 pages, 2 figures
💡 一句话要点
利用强化学习在密码学CTF挑战中提升LLM Agent性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 LLM Agent 密码学CTF 程序生成数据 群体相对策略优化
📋 核心要点
- 现有LLM Agent在密码学等安全领域面临挑战,缺乏有效训练数据和可靠的推理能力。
- 提出Random-Crypto数据集,结合强化学习,训练具备工具使用和程序推理能力的LLM Agent。
- 实验表明,该方法在密码学CTF挑战中显著提升Agent性能,并泛化到其他安全基准。
📝 摘要(中文)
本文提出了'Random-Crypto',一个程序生成的密码学夺旗(CTF)数据集,旨在释放强化学习(RL)在基于LLM的agent在安全敏感领域中的潜力。密码学推理提供了一个理想的RL试验台:它结合了精确的验证、结构化的多步骤推理以及对可靠计算工具使用的依赖。利用这些特性,我们在安全执行环境中通过群体相对策略优化(GRPO)微调了一个Python工具增强的Llama-3.1-8B。由此产生的agent在先前未见过的挑战中实现了Pass@8的显著提升。此外,这些改进推广到两个外部基准:'picoCTF',涵盖密码学和非密码学任务,以及'AICrypto MCQ',一个包含135个密码学问题的多项选择基准。消融研究将收益归因于增强的工具使用和程序推理。这些发现将'Random-Crypto'定位为构建能够处理复杂网络安全任务的智能、适应性强的LLM agent的丰富训练场。
🔬 方法详解
问题定义:现有LLM Agent在解决密码学CTF挑战时,面临着缺乏高质量训练数据、难以进行多步骤推理以及无法有效利用外部工具等问题。传统的训练方法难以使Agent具备足够的密码学知识和解决复杂问题的能力。
核心思路:本文的核心思路是利用程序生成的密码学CTF数据集(Random-Crypto)作为强化学习的训练环境,通过奖励Agent成功解决挑战的行为,使其学习密码学知识、推理能力和工具使用技巧。这种方法能够有效地解决数据稀缺问题,并引导Agent学习解决复杂问题的策略。
技术框架:整体框架包括三个主要部分:Random-Crypto数据集生成器、LLM Agent(Llama-3.1-8B)和强化学习训练环境。Random-Crypto生成器负责创建各种密码学挑战;LLM Agent作为解题者,接收挑战描述并生成Python代码进行求解;强化学习训练环境则根据Agent的解题结果给予奖励或惩罚,并使用群体相对策略优化(GRPO)算法更新Agent的策略。
关键创新:本文的关键创新在于将程序生成的密码学CTF数据集与强化学习相结合,用于训练LLM Agent。与传统的监督学习方法相比,强化学习能够更好地引导Agent学习解决复杂问题的策略,并提高其泛化能力。此外,使用GRPO算法能够有效地稳定训练过程,并提高Agent的性能。
关键设计:Random-Crypto数据集包含多种密码学挑战类型,例如对称加密、非对称加密、哈希函数等。Agent使用Llama-3.1-8B模型,并配备Python工具,用于执行密码学操作。奖励函数根据Agent是否成功解决挑战进行设计,成功解决则获得正向奖励,否则获得负向奖励。GRPO算法使用相对策略梯度进行更新,以提高训练的稳定性。
🖼️ 关键图片
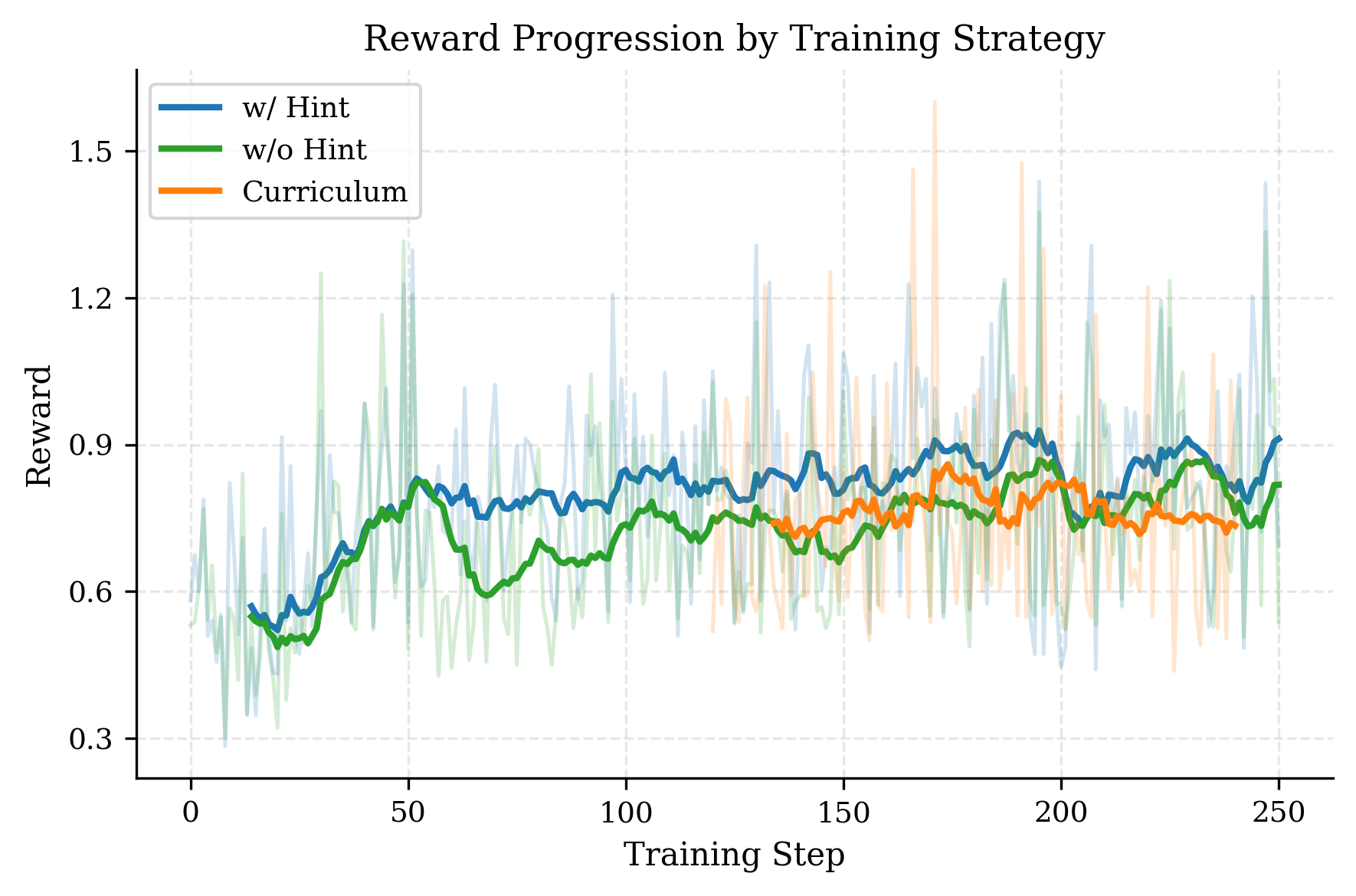
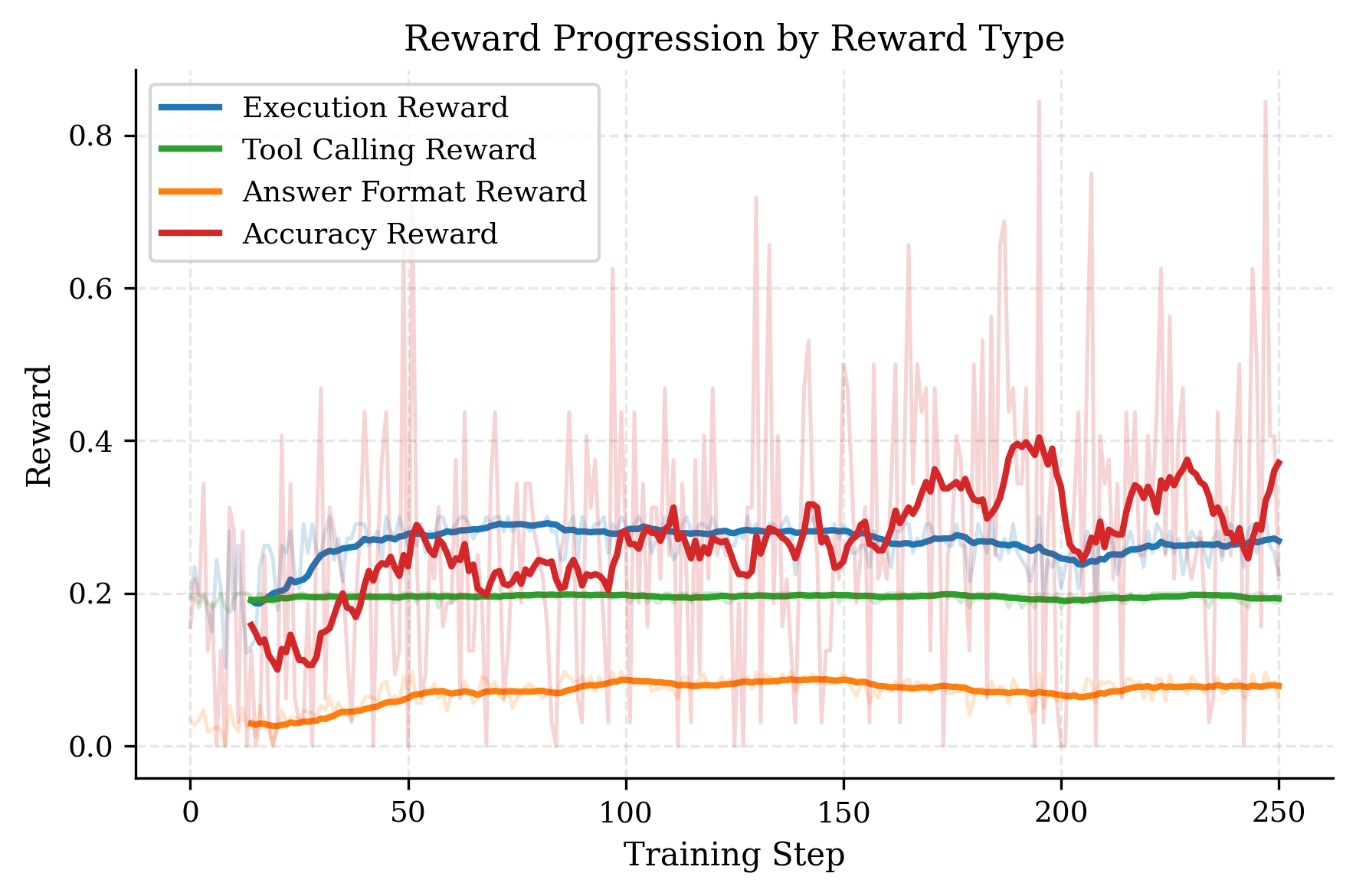
📊 实验亮点
实验结果表明,经过Random-Crypto数据集训练的LLM Agent在密码学CTF挑战中取得了显著的性能提升,Pass@8指标提升明显。此外,该Agent在picoCTF和AICrypto MCQ等外部基准测试中也表现出良好的泛化能力,证明了该方法的有效性。消融实验表明,工具使用和程序推理能力的提升是性能提升的关键因素。
🎯 应用场景
该研究成果可应用于自动化安全分析、漏洞挖掘、渗透测试等领域。训练后的LLM Agent能够辅助安全工程师进行密码学分析,快速识别潜在的安全风险,并提供相应的解决方案。此外,该方法还可以推广到其他安全领域,例如恶意代码分析、网络入侵检测等,构建更智能、更高效的安全防御体系。
📄 摘要(原文)
We present 'Random-Crypto', a procedurally generated cryptographic Capture The Flag (CTF) dataset designed to unlock the potential of Reinforcement Learning (RL) for LLM-based agents in security-sensitive domains. Cryptographic reasoning offers an ideal RL testbed: it combines precise validation, structured multi-step inference, and reliance on reliable computational tool use. Leveraging these properties, we fine-tune a Python tool-augmented Llama-3.1-8B via Group Relative Policy Optimization (GRPO) in a secure execution environment. The resulting agent achieves a significant improvement in Pass@8 on previously unseen challenges. Moreover, the improvements generalize to two external benchmarks: 'picoCTF', spanning both crypto and non-crypto tasks, and 'AICrypto MCQ', a multiple-choice benchmark of 135 cryptography questions. Ablation studies attribute the gains to enhanced tool usage and procedural reasoning. These findings position 'Random-Crypto' as a rich training ground for building intelligent, adaptable LLM agents capable of handling complex cybersecurity tasks.