Behavioral Augmentation of UML Class Diagrams: An Empirical Study of Large Language Models for Method Generation
作者: Djaber Rouabhia, Ismail Hadjadj
分类: cs.SE, cs.AI
发布日期: 2025-06-01
💡 一句话要点
利用大型语言模型自动生成UML类图方法,加速软件设计迭代
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: UML类图 大型语言模型 方法生成 软件设计自动化 自然语言处理
📋 核心要点
- 现有方法难以从自然语言用例中自动生成UML类图的行为方法,导致软件设计效率低下。
- 该研究利用大型语言模型(LLM)理解用例描述,并自动生成UML类图中类的方法定义,实现行为建模的自动化。
- 实验结果表明,LLM能够生成结构良好且命名一致的方法,但注释和签名方面仍需改进,人工监督至关重要。
📝 摘要(中文)
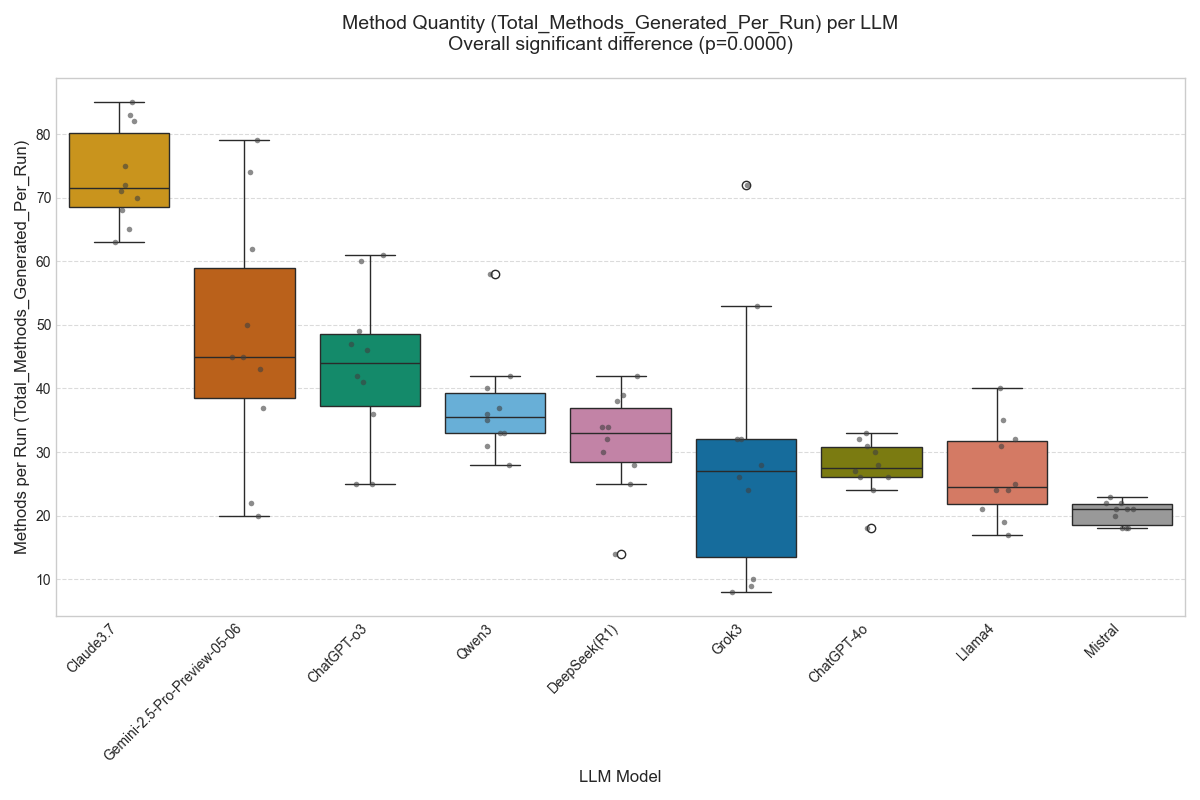
本研究评估了九个大型语言模型(LLM)在增强无方法UML类图方面的能力。研究使用21个结构化的废物管理用例,对包含21个类和17个关系的UML图进行方法自动生成。总共评估了90个图(3,373个方法),并采用了六个指标:方法数量、签名丰富度(可见性、名称、参数、返回类型)、注释完整性(与用例/动作的链接)、结构保真度、语法正确性(PlantUML编译)和命名收敛性(跨模型)。所有LLM都生成了符合UML规范的有效PlantUML图。一些模型在方法覆盖率和注释准确性方面表现出色,而另一些模型则表现出更丰富的参数化但可追溯性较弱。结果表明,LLM可以生成具有一致命名的良好结构化方法,从而推进自动化行为建模。注释和签名方面的不一致表明需要改进提示工程和模型选择。快速生成这些方法通过加速设计迭代来支持敏捷实践。尽管LLM具有强大的功能,但人工监督对于确保准确性、适当性和语义对齐至关重要。这使得LLM成为软件设计中的协作伙伴。所有实验工件(.puml,.png,.csv)均公开提供,以确保可重复性。
🔬 方法详解
问题定义:论文旨在解决从自然语言用例描述中自动生成UML类图方法的问题。现有方法通常依赖于手动建模或基于规则的系统,这些方法耗时且容易出错,难以适应复杂或不断变化的用例。因此,如何利用自然语言处理技术自动生成准确、完整的UML类图方法是本研究要解决的核心问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大自然语言理解和生成能力,将自然语言描述的用例转化为UML类图中的方法定义。通过训练LLM理解UML建模规范和软件设计原则,使其能够自动推断出类的方法名、参数、返回类型等信息,从而实现UML类图的自动增强。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 准备阶段:收集和整理包含自然语言用例描述的软件项目,并将其转化为结构化的数据格式。2) 模型训练阶段:使用收集到的数据对LLM进行微调,使其能够理解用例描述并生成相应的UML方法定义。3) 方法生成阶段:将无方法的UML类图和对应的用例描述输入到训练好的LLM中,LLM自动生成类的方法定义。4) 评估阶段:使用一系列指标(如方法数量、签名丰富度、注释完整性等)对生成的UML类图进行评估。
关键创新:该研究的关键创新在于将大型语言模型应用于UML类图的自动增强。与传统的基于规则或模板的方法相比,LLM能够更好地理解自然语言描述的语义信息,并生成更准确、更完整的UML方法定义。此外,该研究还提出了一系列评估指标,用于全面评估LLM生成的UML类图的质量。
关键设计:研究中使用了九个不同的LLM,并针对UML方法生成的任务进行了微调。在提示工程方面,研究人员设计了特定的提示模板,以指导LLM生成符合UML规范的方法定义。在评估指标方面,研究人员考虑了方法数量、签名丰富度、注释完整性、结构保真度、语法正确性和命名收敛性等多个方面,以全面评估LLM的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所有LLM都能够生成有效的PlantUML图,且符合UML规范。部分模型在方法覆盖率和注释准确性方面表现出色,而另一些模型则在参数化方面更具优势。例如,某些模型能够生成具有丰富参数的方法签名,但其与用例的关联性较弱。总体而言,LLM在生成结构良好且命名一致的方法方面表现出潜力,但注释和签名方面仍有改进空间。
🎯 应用场景
该研究成果可应用于软件开发的多个阶段,例如需求分析、系统设计和代码生成。通过自动生成UML类图方法,可以显著提高软件设计的效率和质量,缩短开发周期。此外,该技术还可以用于自动化测试和代码审查,从而进一步提高软件的可靠性和可维护性。未来,该技术有望与敏捷开发流程相结合,实现更加快速和灵活的软件开发。
📄 摘要(原文)
Automating the enrichment of UML class diagrams with behavioral methods from natural language use cases is a significant challenge. This study evaluates nine large language models (LLMs) in augmenting a methodless UML diagram (21 classes, 17 relationships) using 21 structured waste-management use cases. A total of 90 diagrams (3,373 methods) were assessed across six metrics: method quantity, signature richness (visibility, names, parameters, return types), annotation completeness (linking to use cases/actions), structural fidelity, syntactic correctness (PlantUML compilation), and naming convergence (across models). All LLMs produced valid PlantUML diagrams adhering to UML conventions. Some models excelled in method coverage and annotation accuracy, while others showed richer parameterization but weaker traceability. These results demonstrate that LLMs can generate well-structured methods with consistent naming, advancing automated behavioral modeling. However, inconsistencies in annotations and signatures highlight the need for improved prompt engineering and model selection. The rapid generation of these methods supports Agile practices by enabling faster design iterations. Despite their capabilities, human oversight is essential to ensure accuracy, appropriateness, and semantic alignment. This positions LLMs as collaborative partners in software design. All experimental artifacts (\texttt{.puml}, \texttt{.png}, \texttt{.csv}) are publicly available for reproducibility.