CodeSense: a Real-World Benchmark and Dataset for Code Semantic Reasoning
作者: Monoshi Kumar Roy, Simin Chen, Benjamin Steenhoek, Jinjun Peng, Gail Kaiser, Baishakhi Ray, Wei Le
分类: cs.SE, cs.AI
发布日期: 2025-05-31 (更新: 2025-10-02)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
CodeSense:提出一个真实世界代码语义推理的基准和数据集,用于评估和提升代码大模型在实际软件工程任务中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码语义推理 代码大模型 软件工程 基准数据集 执行跟踪
📋 核心要点
- 现有代码推理基准依赖合成数据或教育问题,缺乏对真实软件工程场景的细粒度语义推理能力的评估。
- CodeSense通过收集真实世界Python、C和Java项目,执行测试并收集执行轨迹,构建细粒度语义推理的ground truth数据集。
- 实验表明,现有LLM在CodeSense上处理细粒度推理任务时性能存在明显差距,提示技术虽有帮助但受限于模型本身的代码语义理解。
📝 摘要(中文)
为了提升代码大模型在解决真实软件工程(SE)任务中的能力,理解和推理代码语义至关重要。虽然已经存在一些代码推理基准,但它们大多依赖于合成数据集或教育性质的编程问题,并且侧重于粗粒度的推理任务,例如输入/输出预测,这限制了它们在评估LLM在实际SE环境中的有效性。为了弥合这一差距,我们提出了CodeSense,这是第一个提供一系列与真实世界代码的软件工程相关的细粒度代码推理任务的基准。我们从真实世界的代码仓库中收集了Python、C和Java软件项目。我们执行了这些仓库中的测试,收集了它们的执行跟踪,并构建了一个用于细粒度语义推理任务的ground truth数据集。然后,我们对最先进的LLM进行了全面的评估。我们的结果表明,模型在处理细粒度推理任务方面存在明显的性能差距。虽然诸如思维链和上下文学习等提示技术有所帮助,但LLM中缺乏代码语义从根本上限制了模型进行代码推理的能力。除了数据集、基准和评估之外,我们的工作还产生了一个执行跟踪框架和工具集,可以轻松地收集细粒度SE推理任务的ground truth,为未来的基准构建和模型后训练提供了坚实的基础。我们的代码和数据位于https://codesense-bench.github.io/。
🔬 方法详解
问题定义:现有代码推理基准主要存在两个痛点:一是数据集多为合成数据或教育性质的编程问题,与真实软件工程场景存在差距;二是推理任务多为粗粒度的输入/输出预测,无法有效评估模型在实际软件工程任务中的细粒度语义推理能力。因此,需要一个更贴近真实场景、包含细粒度推理任务的基准数据集,以促进代码大模型在软件工程领域的应用。
核心思路:CodeSense的核心思路是从真实世界的代码仓库中收集软件项目,通过执行这些项目的测试用例,并收集执行轨迹,从而构建一个包含细粒度代码语义信息的ground truth数据集。这种方法能够保证数据集的真实性和复杂性,同时能够提供足够的信息用于评估模型在细粒度推理任务上的表现。
技术框架:CodeSense的整体框架主要包含以下几个阶段:1) 从真实世界的代码仓库(如GitHub)中选择合适的Python、C和Java软件项目。2) 针对每个项目,执行其自带的测试用例。3) 在测试用例执行过程中,使用专门的执行跟踪框架和工具集收集执行轨迹,包括变量的值、函数调用关系等。4) 基于收集到的执行轨迹,构建用于细粒度语义推理任务的ground truth数据集。5) 使用该数据集评估现有代码大模型的性能。
关键创新:CodeSense最重要的技术创新点在于其数据集的构建方式。它不是基于人工合成或教育性质的编程问题,而是直接从真实世界的代码仓库中提取,并通过执行测试用例和收集执行轨迹的方式来构建ground truth。这种方法能够保证数据集的真实性和复杂性,更贴近实际软件工程场景。此外,该论文还提供了一个执行跟踪框架和工具集,方便后续研究者构建类似的基准数据集。
关键设计:CodeSense的关键设计在于如何有效地收集和处理执行轨迹。论文开发了一个专门的执行跟踪框架和工具集,能够自动地执行测试用例,并收集执行过程中产生的各种信息,例如变量的值、函数调用关系、代码覆盖率等。此外,论文还设计了一系列细粒度的语义推理任务,例如代码缺陷定位、代码补全、代码重构等,用于评估模型在不同方面的推理能力。
🖼️ 关键图片

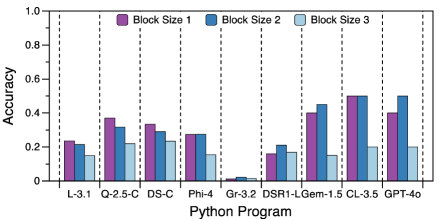

📊 实验亮点
CodeSense基准数据集的实验结果表明,现有最先进的LLM在处理细粒度代码推理任务时性能存在明显差距。例如,在代码缺陷定位任务上,模型的准确率远低于人类水平。虽然诸如思维链和上下文学习等提示技术能够带来一定的性能提升,但受限于模型本身的代码语义理解能力,提升幅度有限。这表明,需要进一步研究如何提升LLM的代码语义理解能力,才能更好地解决实际软件工程问题。
🎯 应用场景
CodeSense基准数据集可以广泛应用于代码大模型的评估和改进,尤其是在软件工程领域。它可以帮助研究人员更好地了解现有模型在处理真实世界代码时的能力瓶颈,并促进开发更强大的代码理解和生成模型。这些模型可以应用于自动化代码审查、智能代码补全、自动缺陷修复等任务,从而提高软件开发的效率和质量。
📄 摘要(原文)
Understanding and reasoning about code semantics is essential for enhancing code LLMs' abilities to solve real-world software engineering (SE) tasks. Although several code reasoning benchmarks exist, most rely on synthetic datasets or educational coding problems and focus on coarse-grained reasoning tasks such as input/output prediction, limiting their effectiveness in evaluating LLMs in practical SE contexts. To bridge this gap, we propose CodeSense, the first benchmark that makes available a spectrum of fine-grained code reasoning tasks concerned with the software engineering of real-world code. We collected Python, C and Java software projects from real-world repositories. We executed tests from these repositories, collected their execution traces, and constructed a ground truth dataset for fine-grained semantic reasoning tasks. We then performed comprehensive evaluations on state-of-the-art LLMs. Our results show a clear performance gap for the models to handle fine-grained reasoning tasks. Although prompting techniques such as chain-of-thought and in-context learning helped, the lack of code semantics in LLMs fundamentally limit models' capabilities of code reasoning. Besides dataset, benchmark and evaluation, our work produced an execution tracing framework and tool set that make it easy to collect ground truth for fine-grained SE reasoning tasks, offering a strong basis for future benchmark construction and model post training. Our code and data are located at https://codesense-bench.github.io/.