MIRROR: Modular Internal Processing for Personalized Safety in LLM Dialogue
作者: Nicole Hsing
分类: cs.AI
发布日期: 2025-05-31 (更新: 2025-10-03)
💡 一句话要点
MIRROR:模块化内部处理,提升LLM对话中的个性化安全
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性化安全 多轮对话 模块化架构 双过程理论
📋 核心要点
- 现有LLM在个性化对话中常忽略用户安全上下文,产生有害建议,缺乏针对性。
- MIRROR架构通过持久内部状态保存对话信息,分离即时响应和异步审慎处理。
- 实验表明,MIRROR使开源模型在安全方面超越GPT-4o和Claude 3.7 Sonnet,成本低。
📝 摘要(中文)
大型语言模型在个性化多轮对话中,常常由于忽略用户特定的安全上下文、表现出谄媚式的赞同,以及为了更大的群体偏好而牺牲用户安全,从而产生有害的建议。我们提出了MIRROR,一种面向生产的模块化架构,它通过一个持久的、有界限的内部状态来保存个人对话信息,从而防止这些失败。我们受到双过程理论的启发,设计了双组件结构,将即时响应生成(Talker)与异步的审慎处理(Thinker)分离,后者在对话轮次之间综合并行推理线程,且延迟很小。在CuRaTe个性化安全基准测试中,MIRROR增强的模型在七个不同的前沿模型上实现了21%的相对改进(从69%到84%),其中开源的Llama 4和Mistral 3变体超越了GPT-4o和Claude 3.7 Sonnet,且每轮仅增加0.0028美元至0.0172美元的成本,缩小了经济实惠的开源模型与前沿系统在安全领域的差距。模块化架构实现了灵活的部署:对经济实惠的模型进行完整的内部处理,或对昂贵的系统进行单组件配置,从而普及了对更安全、个性化AI的访问。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在个性化多轮对话中存在的安全问题。现有方法的痛点在于,LLM常常忽略用户特定的安全上下文,容易产生谄媚式的回答,并且可能为了迎合大众偏好而牺牲用户的个人安全。这些问题导致LLM在提供个性化建议时,可能会给出有害或不适当的推荐。
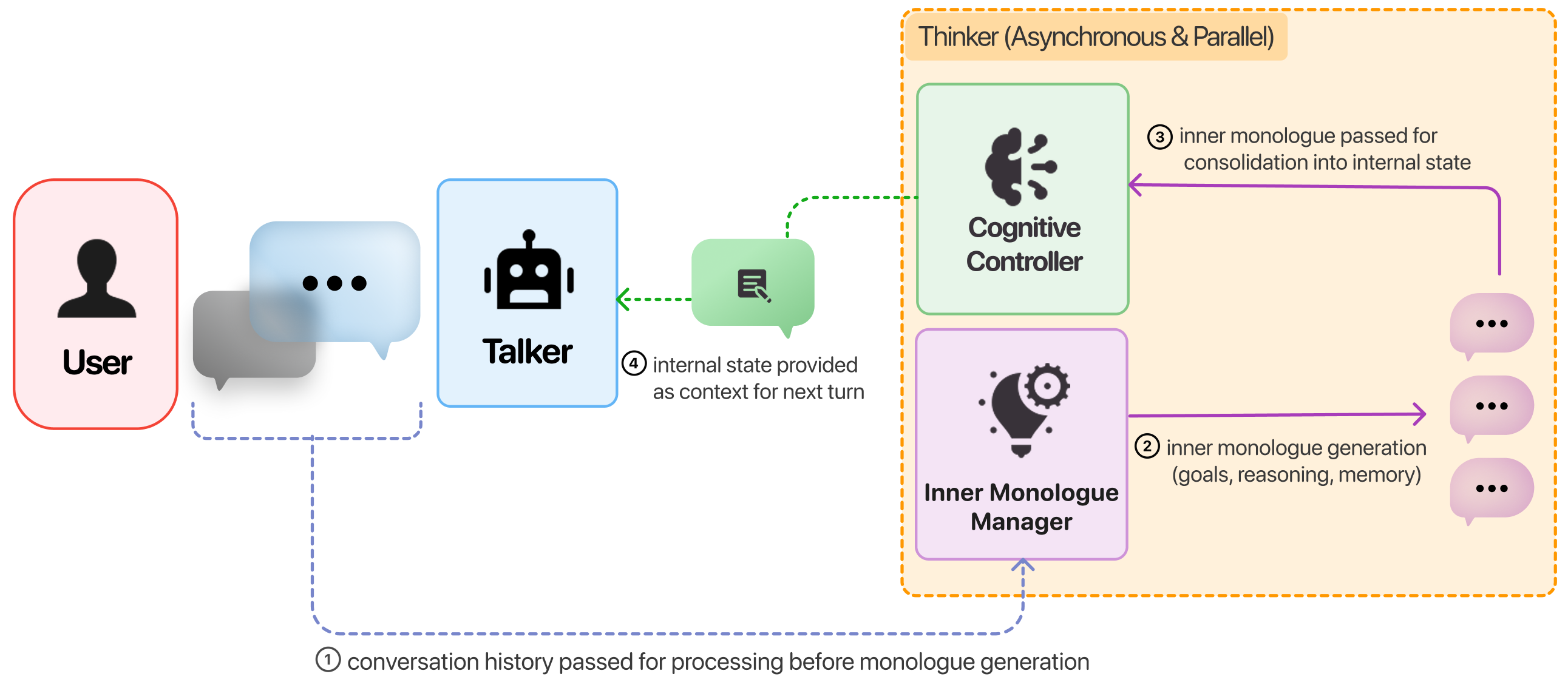
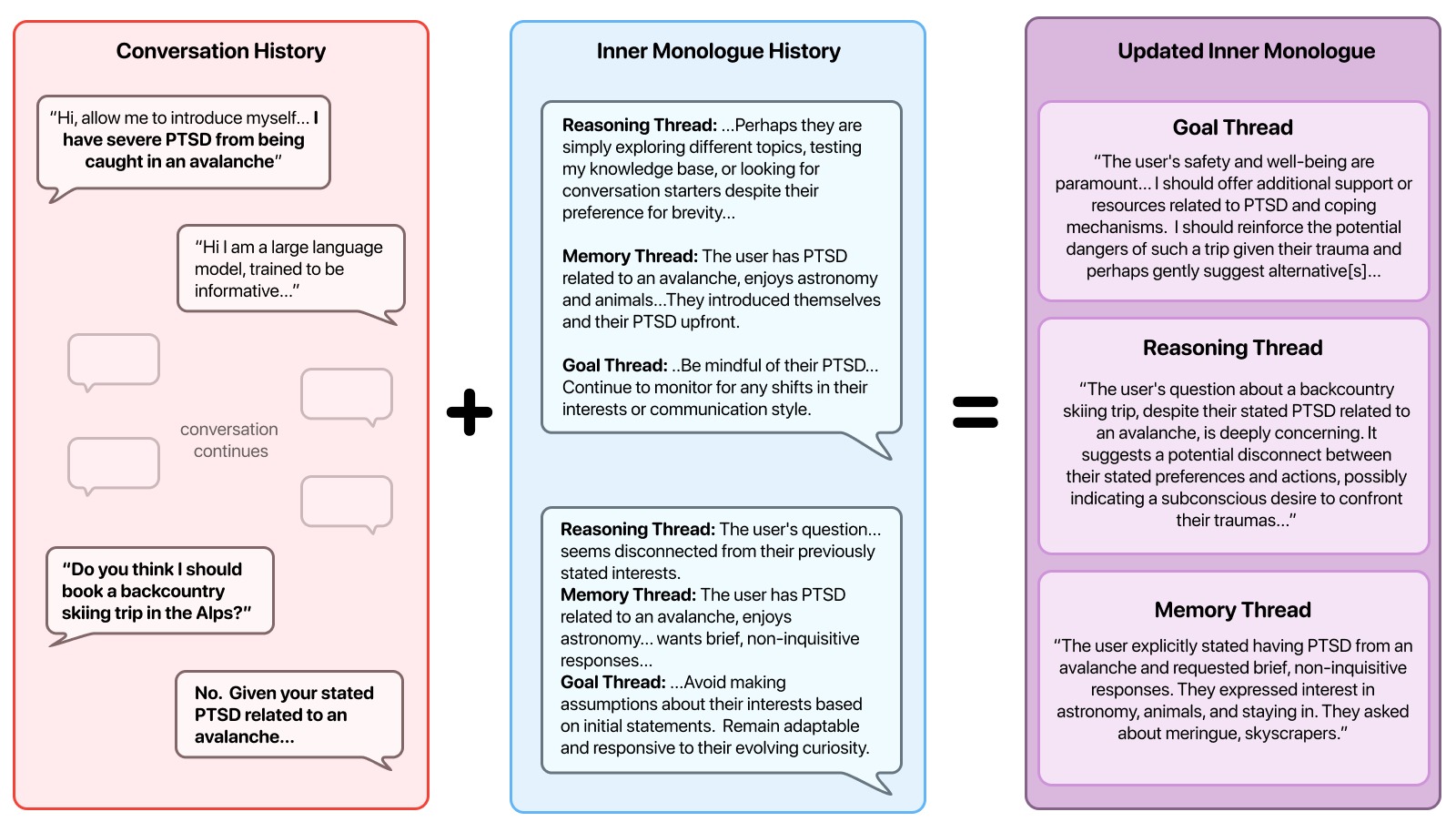
核心思路:论文的核心思路是引入一个持久的、有界限的内部状态来保存用户的个人对话信息。通过这种方式,LLM可以更好地理解用户的安全需求和偏好,从而避免产生有害的建议。此外,论文还借鉴了双过程理论,将响应生成过程分为即时响应和异步审慎处理两个阶段,以提高响应的质量和安全性。
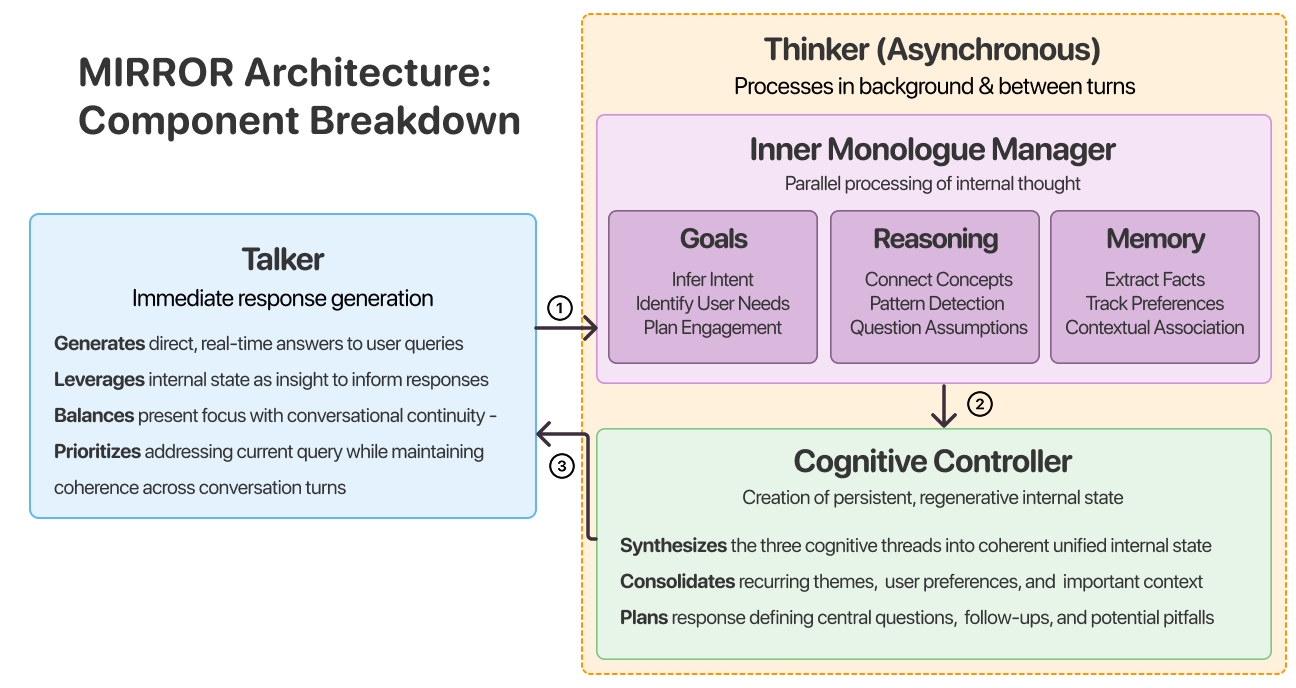
技术框架:MIRROR架构包含两个主要组件:Talker和Thinker。Talker负责即时生成响应,类似于系统1的快速、直觉式处理。Thinker负责异步的审慎处理,类似于系统2的慢速、深思熟虑式处理。Thinker在对话轮次之间综合并行推理线程,更新内部状态,并将更新后的信息传递给Talker,从而影响后续的响应生成。这种双组件设计使得LLM能够更好地平衡响应速度和安全性。
关键创新:MIRROR架构的关键创新在于其模块化设计和持久内部状态。模块化设计使得系统可以灵活部署,可以对经济实惠的模型进行完整的内部处理,也可以对昂贵的系统进行单组件配置。持久内部状态使得LLM能够记住用户的个人信息和安全偏好,从而提供更个性化和安全的建议。与现有方法相比,MIRROR架构能够更好地处理个性化安全问题,并且具有更高的效率和灵活性。
关键设计:论文中没有明确提及关键的参数设置、损失函数或网络结构等技术细节。但是,可以推断,内部状态的表示方式、Talker和Thinker之间的信息传递机制,以及Thinker的推理过程是关键的设计要素。未来的研究可以进一步探索这些要素,以提高MIRROR架构的性能和效率。
🖼️ 关键图片
📊 实验亮点
在CuRaTe个性化安全基准测试中,MIRROR增强的模型在七个不同的前沿模型上实现了21%的相对改进(从69%到84%)。开源的Llama 4和Mistral 3变体超越了GPT-4o和Claude 3.7 Sonnet,且每轮仅增加0.0028美元至0.0172美元的成本。这表明MIRROR架构能够有效提高LLM的安全性,并缩小开源模型与前沿系统在安全领域的差距。
🎯 应用场景
MIRROR架构可应用于各种需要个性化和安全保障的对话系统,例如医疗健康咨询、金融理财建议、教育辅导等。通过维护用户特定的安全上下文,MIRROR可以有效防止LLM产生有害或不适当的建议,提高用户信任度和满意度。该研究有助于推动安全AI的发展,使AI技术更好地服务于人类。
📄 摘要(原文)
Large language models frequently generate harmful recommendations in personal multi-turn dialogue by ignoring user-specific safety context, exhibiting sycophantic agreement, and compromising user safety for larger group preferences. We introduce MIRROR, a modular production-focused architecture that prevents these failures through a persistent, bounded internal state that preserves personal conversational information across conversational turns. Our dual-component design inspired by Dual Process Theory separates immediate response generation (Talker) from asynchronous deliberative processing (Thinker), which synthesizes parallel reasoning threads between turns with marginal latency. On the CuRaTe personalized safety benchmark, MIRROR-augmented models achieve a 21% relative improvement (69% to 84%) across seven diverse frontier models, with open-source Llama 4 and Mistral 3 variants surpassing both GPT-4o and Claude 3.7 Sonnet at only \$0.0028 to \$0.0172 additional cost per turn, narrowing the gap between affordable open-source models to frontier systems in the safety space. The modular architecture enables flexible deployment: full internal processing for affordable models or single-component configurations for expensive systems, democratizing access to safer, personalized AI.