The World As Large Language Models See It: Exploring the reliability of LLMs in representing geographical features
作者: Omid Reza Abbasi, Franz Welscher, Georg Weinberger, Johannes Scholz
分类: cs.CY, cs.AI, cs.IR
发布日期: 2025-05-30
备注: 9 pages, 4 figures, 2 tables
💡 一句话要点
评估大语言模型地理信息表示能力:GPT-4o和Gemini 2.0在地理空间任务中的可靠性分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 地理信息系统 地理编码 高程估计 逆地理编码 地理信息学 GPT-4o Gemini 2.0 Flash
📋 核心要点
- 大型语言模型在地理信息表示方面存在准确性和可靠性问题,这限制了其在地理空间领域的应用。
- 该研究通过地理编码、高程估计和逆地理编码三个任务,评估GPT-4o和Gemini 2.0 Flash的地理信息表示能力。
- 实验结果表明,两种模型在地理空间任务中均存在误差,需要使用地理信息进行微调以提高其准确性和可靠性。
📝 摘要(中文)
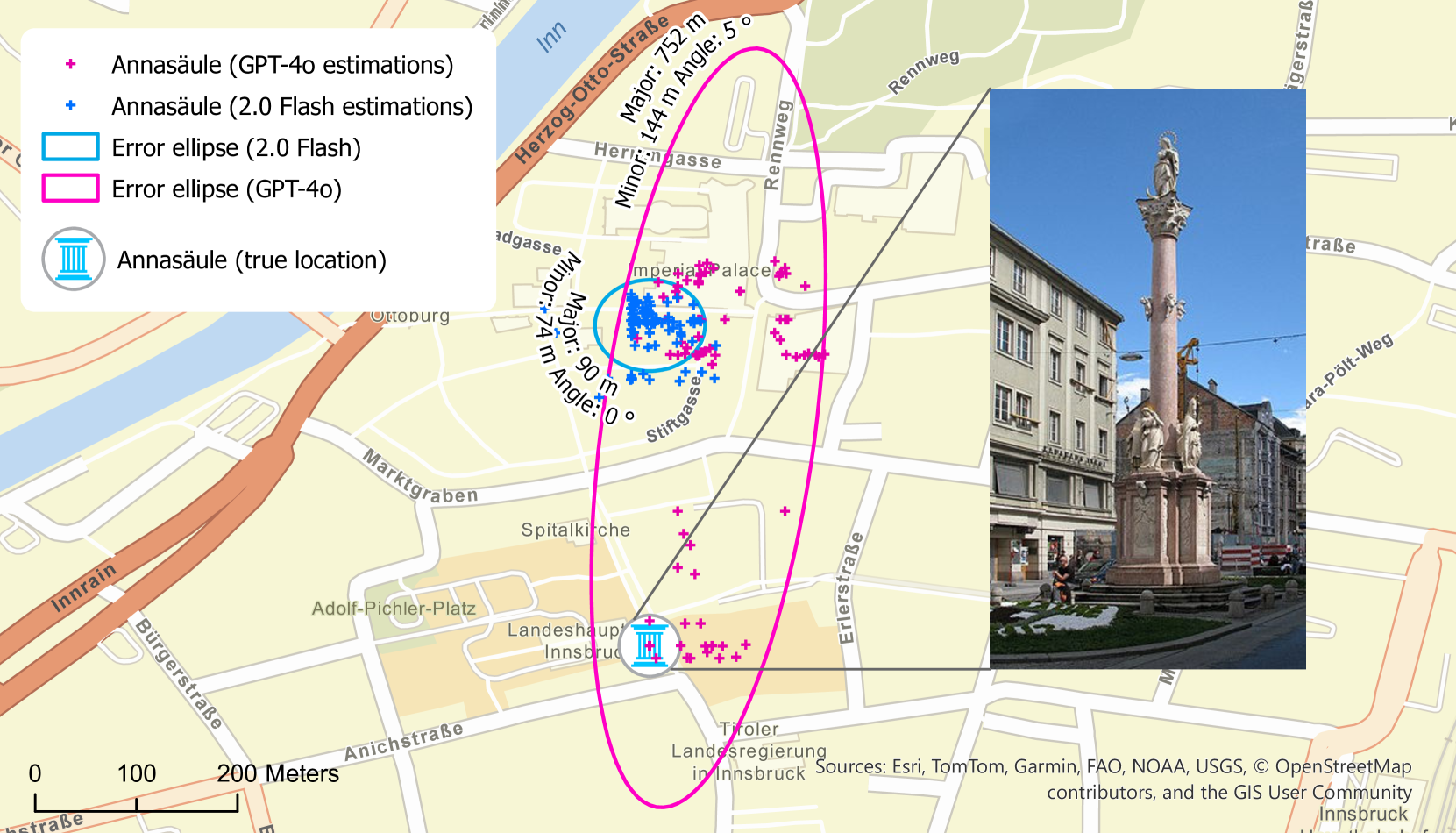
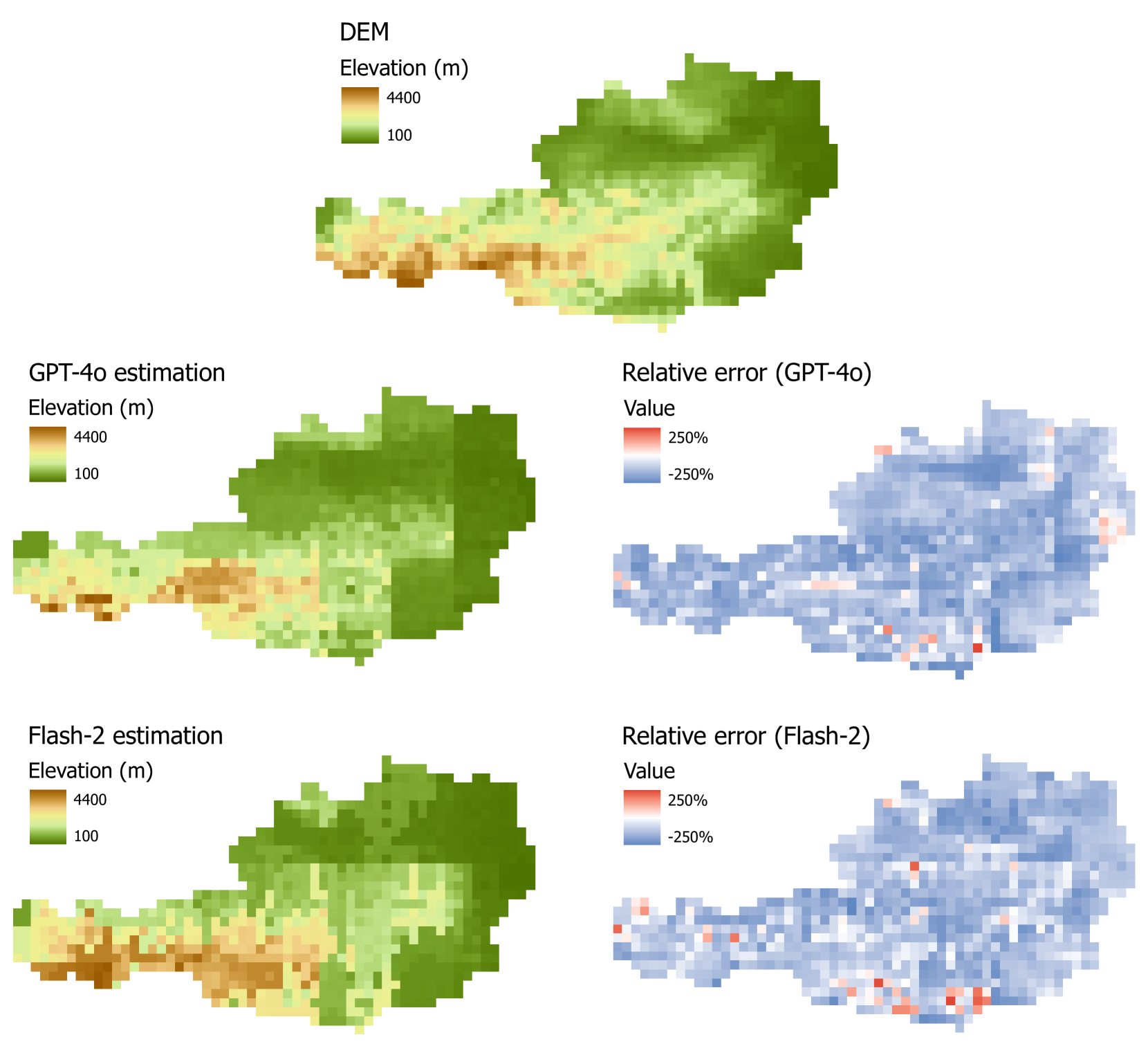
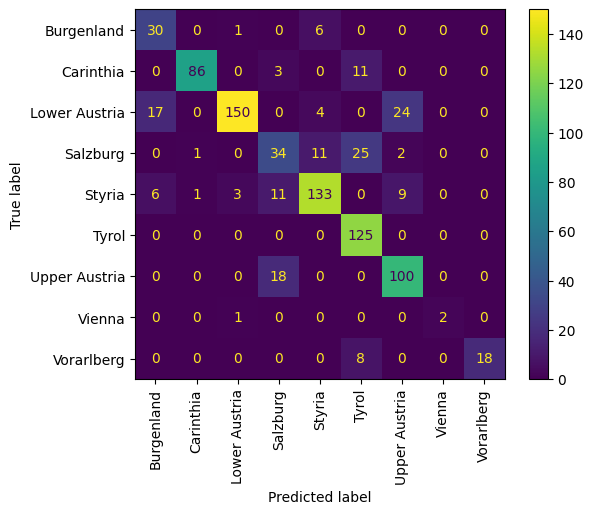
随着大型语言模型(LLMs)的不断发展,其在提供事实信息方面的可信度问题日益重要。这种担忧也适用于它们准确表示地理世界的能力。鉴于该领域的最新进展,评估LLMs对地理世界的表示在何种程度上值得信赖具有重要意义。本研究评估了GPT-4o和Gemini 2.0 Flash在三个关键地理空间任务中的表现:地理编码、高程估计和逆地理编码。在地理编码任务中,两种模型在估计奥地利因斯布鲁克圣安妮专栏的坐标时都表现出系统性和随机误差,其中GPT-4o的偏差更大,Gemini 2.0 Flash的精度更高但存在显著的系统性偏移。对于高程估计,两种模型都倾向于低估奥地利各地的高程,但它们捕捉到了整体地形趋势,Gemini 2.0 Flash在东部地区表现更好。逆地理编码任务(涉及从坐标识别奥地利联邦州)显示,Gemini 2.0 Flash在总体准确性和F1分数方面优于GPT-4o,表明其在各个区域之间具有更好的一致性。尽管有这些发现,但两种模型都未能准确重建奥地利的联邦州,突出了持续存在的错误分类。研究结论是,虽然LLMs可以近似地理信息,但它们的准确性和可靠性不一致,这突显了需要使用地理信息进行微调,以增强它们在GIScience和地理信息学中的效用。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在地理信息表示方面的能力,具体考察它们在地理编码、高程估计和逆地理编码三个任务中的表现。现有方法,即直接使用LLMs进行地理空间推理,其痛点在于LLMs缺乏针对地理信息的专门训练,导致其输出的地理信息不准确、不可靠。
核心思路:论文的核心思路是通过设计一系列地理空间任务,直接测试LLMs在这些任务上的表现,从而量化LLMs在地理信息表示方面的能力。通过对比不同LLMs的表现,可以了解不同模型在地理信息处理方面的优劣。这种直接评估的方法能够揭示LLMs在地理信息处理方面的局限性,为后续的改进提供依据。
技术框架:该研究的技术框架主要包括以下几个阶段: 1. 数据准备:收集奥地利地理信息数据,包括地标坐标、高程数据和联邦州边界数据。 2. 任务设计:设计地理编码、高程估计和逆地理编码三个任务,用于评估LLMs的地理信息表示能力。 3. 模型评估:使用GPT-4o和Gemini 2.0 Flash两种LLMs完成上述任务,并记录其输出结果。 4. 结果分析:对比LLMs的输出结果与真实值,计算误差指标(如坐标偏差、高程误差、分类准确率),评估LLMs的性能。
关键创新:该研究的关键创新在于系统性地评估了当前主流LLMs在地理空间任务中的表现。以往的研究可能侧重于LLMs在文本生成或知识问答方面的能力,而该研究则专注于LLMs在地理信息处理方面的能力。通过设计具体的地理空间任务,该研究能够更准确地评估LLMs在地理信息表示方面的优劣,为后续的研究提供参考。与现有方法的本质区别在于,该研究并非简单地将LLMs应用于地理空间问题,而是深入分析了LLMs在地理信息处理方面的内在局限性。
关键设计:在地理编码任务中,研究人员选择了奥地利因斯布鲁克的圣安妮专栏作为测试对象,评估LLMs预测其坐标的准确性。在高程估计任务中,研究人员使用了奥地利各地的高程数据,评估LLMs预测高程的准确性。在逆地理编码任务中,研究人员使用了奥地利联邦州的边界数据,评估LLMs根据坐标识别联邦州的准确性。研究人员使用了多种误差指标来评估LLMs的性能,包括坐标偏差、高程误差、分类准确率和F1分数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-4o和Gemini 2.0 Flash在地理编码任务中存在系统性和随机误差,GPT-4o的偏差更大。在高程估计任务中,两种模型都倾向于低估高程。在逆地理编码任务中,Gemini 2.0 Flash在总体准确性和F1分数方面优于GPT-4o。尽管如此,两种模型都未能准确重建奥地利的联邦州,表明LLMs在地理信息处理方面仍有很大的提升空间。
🎯 应用场景
该研究成果可应用于改进地理信息系统(GIS)和地理信息学。通过了解LLMs在地理信息处理方面的局限性,可以开发更有效的地理信息处理方法,例如,利用LLMs进行初步的地理信息提取,然后通过专门的地理信息处理算法进行修正。此外,该研究还可以为LLMs的微调提供指导,使其更好地适应地理信息处理任务。
📄 摘要(原文)
As large language models (LLMs) continue to evolve, questions about their trustworthiness in delivering factual information have become increasingly important. This concern also applies to their ability to accurately represent the geographic world. With recent advancements in this field, it is relevant to consider whether and to what extent LLMs' representations of the geographical world can be trusted. This study evaluates the performance of GPT-4o and Gemini 2.0 Flash in three key geospatial tasks: geocoding, elevation estimation, and reverse geocoding. In the geocoding task, both models exhibited systematic and random errors in estimating the coordinates of St. Anne's Column in Innsbruck, Austria, with GPT-4o showing greater deviations and Gemini 2.0 Flash demonstrating more precision but a significant systematic offset. For elevation estimation, both models tended to underestimate elevations across Austria, though they captured overall topographical trends, and Gemini 2.0 Flash performed better in eastern regions. The reverse geocoding task, which involved identifying Austrian federal states from coordinates, revealed that Gemini 2.0 Flash outperformed GPT-4o in overall accuracy and F1-scores, demonstrating better consistency across regions. Despite these findings, neither model achieved an accurate reconstruction of Austria's federal states, highlighting persistent misclassifications. The study concludes that while LLMs can approximate geographic information, their accuracy and reliability are inconsistent, underscoring the need for fine-tuning with geographical information to enhance their utility in GIScience and Geoinformatics.