Control-R: Towards controllable test-time scaling
作者: Di Zhang, Weida Wang, Junxian Li, Xunzhi Wang, Jiatong Li, Jianbo Wu, Jingdi Lei, Haonan He, Peng Ye, Shufei Zhang, Wanli Ouyang, Yuqiang Li, Dongzhan Zhou
分类: cs.AI, cs.CL
发布日期: 2025-05-30
💡 一句话要点
提出Control-R,通过可控推理控制解决大语言模型长链推理中的欠思考和过度思考问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长链推理 可控推理 推理控制场 条件蒸馏 大型语言模型 测试时缩放 知识推理
📋 核心要点
- 长链思考推理中,大型推理模型面临欠思考导致推理不充分,以及过度思考导致资源浪费的问题。
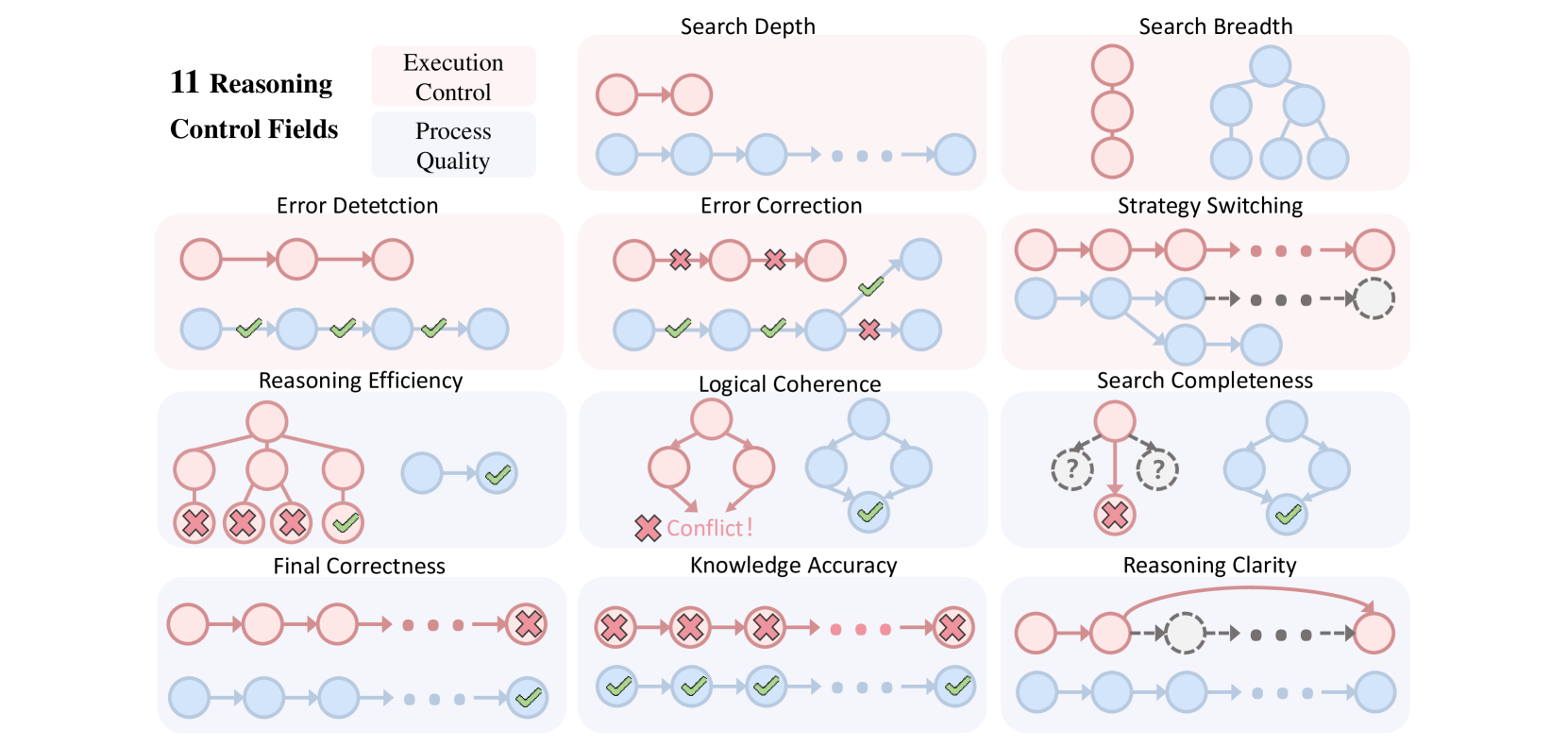
- 论文提出推理控制场(RCF)方法,通过结构化控制信号引导推理过程,实现推理力度的动态调整。
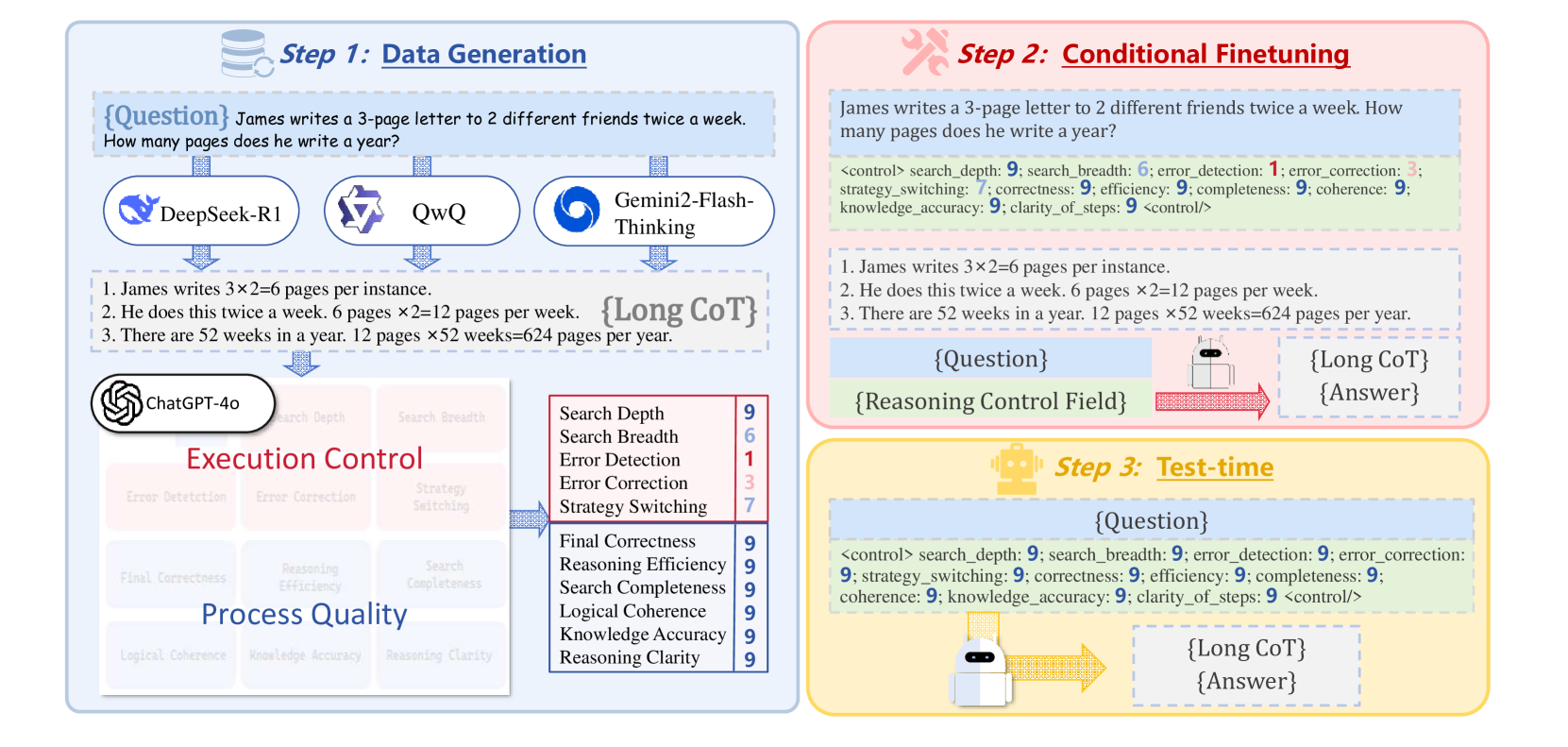
- 通过条件蒸馏微调(CDF)训练Control-R-32B模型,并在AIME2024和MATH500等基准测试上取得了SOTA性能。
📝 摘要(中文)
本文旨在解决大型推理模型(LRM)在长链思考(CoT)推理中存在的欠思考和过度思考问题。为此,我们引入了推理控制场(RCF),这是一种新颖的测试时方法,通过注入结构化的控制信号,从树搜索的角度指导推理。RCF使模型能够在解决复杂任务时,根据给定的控制条件调整推理力度。此外,我们提出了Control-R-4K数据集,其中包含具有详细推理过程和相应控制场的具有挑战性的问题。为了进一步增强推理控制,我们提出了一种条件蒸馏微调(CDF)方法,该方法训练模型(特别是Control-R-32B)在测试时有效地调整推理力度。在AIME2024和MATH500等基准测试上的实验结果表明,我们的方法在32B规模上实现了最先进的性能,同时实现了可控的长CoT推理(L-CoT)。总而言之,这项工作为可控的测试时缩放推理引入了一种有效的范例。
🔬 方法详解
问题定义:大型推理模型在执行长链思考(CoT)推理时,经常面临欠思考和过度思考的问题。欠思考指的是模型推理深度不足,无法充分挖掘问题信息,导致错误答案。过度思考则指的是模型进行了不必要的推理步骤,浪费计算资源,且可能引入噪声干扰。
核心思路:论文的核心思路是引入推理控制场(Reasoning Control Fields, RCF),通过在推理过程中注入结构化的控制信号,引导模型进行适当的推理。RCF可以看作是对推理过程的一种显式调控,使得模型能够根据任务的复杂度和控制信号,动态调整推理的深度和广度,从而避免欠思考和过度思考。
技术框架:整体框架包含以下几个关键部分:1) 推理控制场(RCF):定义了控制信号的结构和含义,用于指导推理过程。2) Control-R-4K数据集:包含带有详细推理过程和对应控制场的复杂问题,用于训练和评估模型。3) 条件蒸馏微调(CDF):一种训练方法,用于训练模型根据控制信号调整推理力度。在推理阶段,模型根据RCF提供的控制信号,逐步生成推理步骤,最终得到答案。
关键创新:论文的关键创新在于提出了推理控制场(RCF)的概念,并将其应用于长链思考推理中。与传统的CoT方法相比,RCF允许对推理过程进行更精细的控制,使得模型能够根据任务的需要,动态调整推理策略。此外,条件蒸馏微调(CDF)方法也为训练具有可控推理能力的模型提供了有效的手段。
关键设计:RCF的具体实现方式未知,但可以推测其可能包含以下设计:1) 控制信号的表示形式:例如,可以使用向量或离散符号来表示控制信号。2) 控制信号的注入方式:例如,可以将控制信号作为模型的输入,或者将其融入到模型的内部状态中。3) CDF的损失函数:可能包含模仿学习损失,用于让模型学习专家提供的控制信号,以及奖励塑造损失,用于鼓励模型生成更有效的推理路径。Control-R-4K数据集的构建细节未知,但可以推测其需要人工标注大量的推理过程和对应的控制信号。
🖼️ 关键图片

📊 实验亮点
Control-R在AIME2024和MATH500等基准测试上取得了state-of-the-art的性能,尤其是在32B规模的模型上。实验结果表明,该方法不仅提高了模型的准确率,还实现了对长链思考推理过程的可控性,能够根据需要调整推理的深度和广度。
🎯 应用场景
该研究成果可应用于需要复杂推理的领域,如数学问题求解、代码生成、知识图谱推理等。通过控制推理过程,可以提高模型的准确性和效率,降低计算成本。未来,该技术有望应用于智能客服、自动驾驶等领域,提升系统的智能化水平。
📄 摘要(原文)
This paper target in addressing the challenges of underthinking and overthinking in long chain-of-thought (CoT) reasoning for Large Reasoning Models (LRMs) by introducing Reasoning Control Fields (RCF)--a novel test-time approach that injects structured control signals to guide reasoning from a tree search perspective. RCF enables models to adjust reasoning effort according to given control conditions when solving complex tasks. Additionally, we present the Control-R-4K dataset, which consists of challenging problems annotated with detailed reasoning processes and corresponding control fields. To further enhance reasoning control, we propose a Conditional Distillation Finetuning (CDF) method, which trains model--particularly Control-R-32B--to effectively adjust reasoning effort during test time. Experimental results on benchmarks such as AIME2024 and MATH500 demonstrate that our approach achieves state-of-the-art performance at the 32B scale while enabling a controllable Long CoT reasoning process (L-CoT). Overall, this work introduces an effective paradigm for controllable test-time scaling reasoning.