MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning
作者: Jingyan Shen, Jiarui Yao, Rui Yang, Yifan Sun, Feng Luo, Rui Pan, Tong Zhang, Han Zhao
分类: cs.AI, cs.CL
发布日期: 2025-05-30 (更新: 2025-09-22)
💡 一句话要点
MiCRo:混合建模与上下文感知路由,用于个性化偏好学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化偏好学习 奖励建模 混合模型 上下文感知 在线路由
📋 核心要点
- 现有基于Bradley-Terry模型的奖励建模方法无法捕捉人类偏好的多样性和异质性,限制了个性化和多元化对齐。
- MiCRo框架通过上下文感知的混合建模和在线路由策略,利用大规模二元偏好数据学习个性化偏好,无需细粒度标注。
- 实验结果表明,MiCRo能够有效捕捉人类偏好,并显著提升下游个性化任务的性能。
📝 摘要(中文)
在将人类反馈强化学习(RLHF)应用于对齐大型语言模型(LLM)时,奖励建模是构建安全基础模型的关键步骤。然而,基于Bradley-Terry(BT)模型的奖励建模假设存在一个全局奖励函数,无法捕捉人类偏好中固有的多样性和异质性。这种过度简化限制了LLM支持个性化和多元化对齐的能力。理论上,我们证明当人类偏好遵循不同子群体的混合分布时,单个BT模型存在不可约的误差。现有的解决方案,如使用细粒度标注进行多目标学习,有助于解决这个问题,但它们成本高昂,并受到预定义属性的约束,无法完全捕捉人类价值观的丰富性。在这项工作中,我们提出了MiCRo,一个两阶段框架,通过利用大规模二元偏好数据集,无需显式的细粒度标注,来增强个性化偏好学习。在第一阶段,MiCRo引入了上下文感知的混合建模方法来捕捉多样化的人类偏好。在第二阶段,MiCRo集成了一种在线路由策略,该策略基于特定上下文动态调整混合权重以解决歧义,从而以最小的额外监督实现高效且可扩展的偏好适应。在多个偏好数据集上的实验表明,MiCRo有效地捕捉了多样化的人类偏好,并显著提高了下游个性化。
🔬 方法详解
问题定义:现有奖励模型通常假设单一的全局偏好,无法有效处理人类偏好中存在的显著差异。这种假设导致模型在面对不同用户或不同情境时表现不佳,阻碍了个性化语言模型的发展。现有方法,如多目标学习,需要昂贵的细粒度标注,且受限于预定义的属性,难以捕捉人类偏好的全部复杂性。
核心思路:MiCRo的核心思想是将人类偏好建模为一个混合分布,每个成分代表一种不同的偏好子群体。通过上下文感知的混合建模,MiCRo能够学习到这些子群体的特征。此外,MiCRo采用在线路由策略,根据输入上下文动态调整混合权重,从而在推理时选择最合适的偏好组合。这种设计允许模型在无需显式标注的情况下,适应不同的用户和情境。
技术框架:MiCRo框架包含两个主要阶段:1) 上下文感知的混合建模:利用大规模二元偏好数据集,学习不同偏好子群体的表示。该阶段的目标是识别并建模不同的偏好模式。2) 在线路由策略:根据输入上下文,动态调整混合模型的权重。该阶段的目标是根据当前情境选择最合适的偏好组合,从而实现个性化偏好预测。
关键创新:MiCRo的关键创新在于其结合了混合建模和上下文感知路由。传统的混合模型通常需要预先定义好的类别或聚类,而MiCRo通过上下文信息动态地学习和调整混合权重,从而更好地适应人类偏好的复杂性和多样性。此外,MiCRo无需细粒度标注,降低了数据收集和标注的成本。
关键设计:在混合建模阶段,可以使用不同的模型结构来表示偏好子群体,例如神经网络或决策树。上下文信息可以通过嵌入层进行编码。在线路由策略可以使用不同的算法,例如梯度下降或强化学习,来动态调整混合权重。损失函数可以设计为最大化观测到的偏好数据的似然性,并加入正则化项以防止过拟合。
🖼️ 关键图片

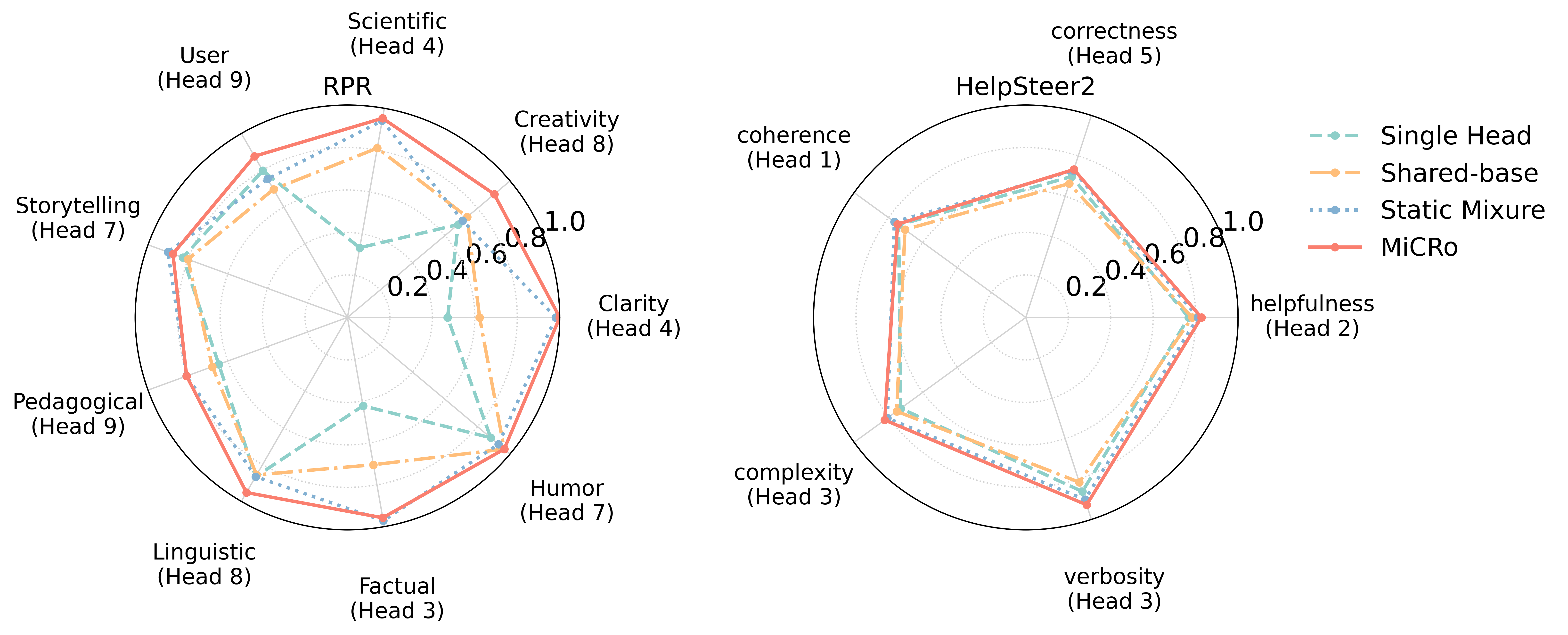
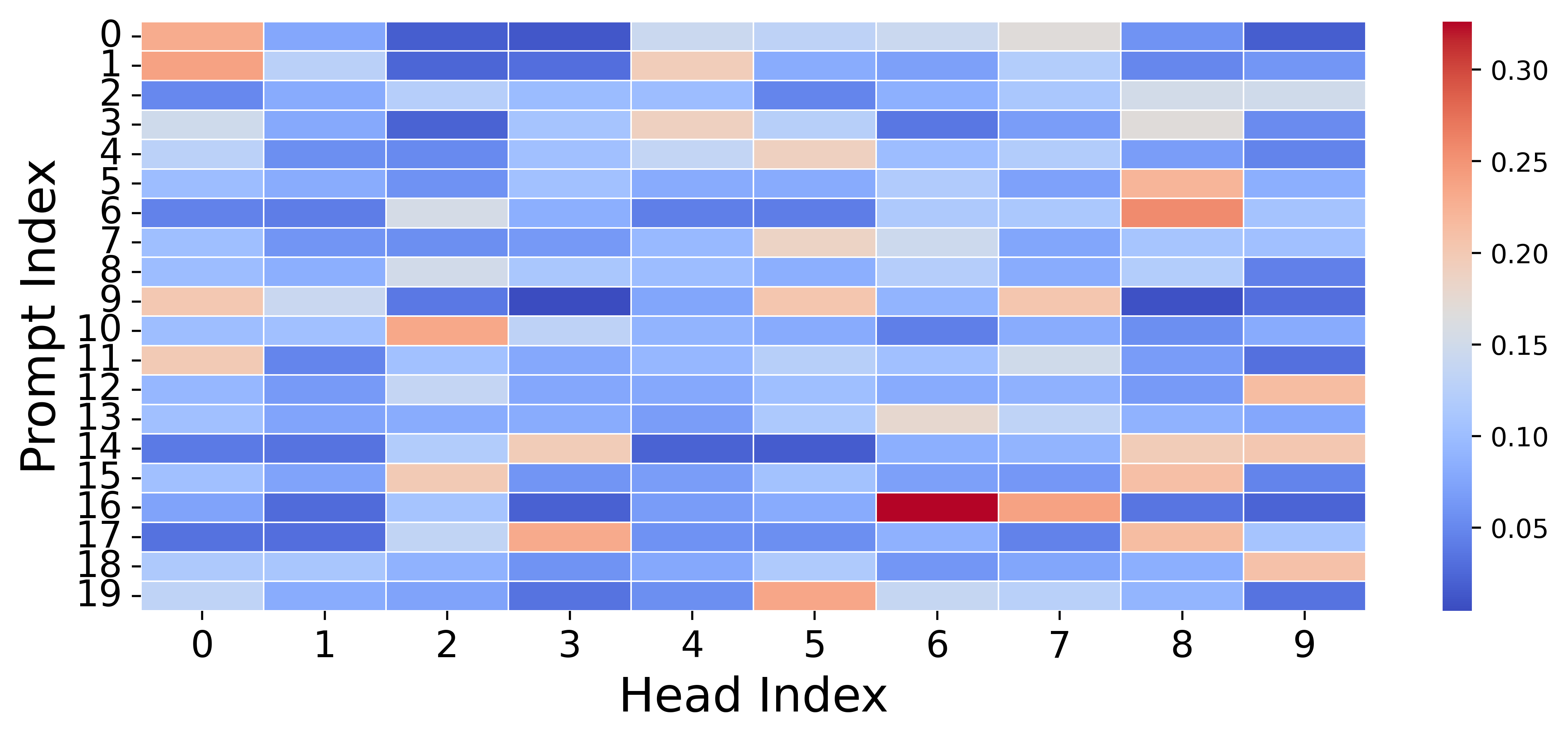
📊 实验亮点
MiCRo在多个偏好数据集上进行了实验,结果表明,MiCRo能够有效捕捉多样化的人类偏好,并显著提高了下游个性化任务的性能。具体而言,MiCRo在偏好预测准确率方面优于现有的基线方法,并且能够生成更符合用户个性化偏好的内容。实验结果验证了MiCRo框架的有效性和优越性。
🎯 应用场景
MiCRo框架可应用于各种需要个性化偏好学习的场景,例如:个性化推荐系统、对话系统、内容生成等。通过学习和适应用户的个性化偏好,MiCRo可以提升用户体验,提高系统的效率和准确性。该研究对于构建更加智能和人性化的AI系统具有重要意义,并有望推动人机交互领域的发展。
📄 摘要(原文)
Reward modeling is a key step in building safe foundation models when applying reinforcement learning from human feedback (RLHF) to align Large Language Models (LLMs). However, reward modeling based on the Bradley-Terry (BT) model assumes a global reward function, failing to capture the inherently diverse and heterogeneous human preferences. Hence, such oversimplification limits LLMs from supporting personalization and pluralistic alignment. Theoretically, we show that when human preferences follow a mixture distribution of diverse subgroups, a single BT model has an irreducible error. While existing solutions, such as multi-objective learning with fine-grained annotations, help address this issue, they are costly and constrained by predefined attributes, failing to fully capture the richness of human values. In this work, we introduce MiCRo, a two-stage framework that enhances personalized preference learning by leveraging large-scale binary preference datasets without requiring explicit fine-grained annotations. In the first stage, MiCRo introduces context-aware mixture modeling approach to capture diverse human preferences. In the second stage, MiCRo integrates an online routing strategy that dynamically adapts mixture weights based on specific context to resolve ambiguity, allowing for efficient and scalable preference adaptation with minimal additional supervision. Experiments on multiple preference datasets demonstrate that MiCRo effectively captures diverse human preferences and significantly improves downstream personalization.