A Reward-driven Automated Webshell Malicious-code Generator for Red-teaming
作者: Yizhong Ding
分类: cs.CR, cs.AI
发布日期: 2025-05-30
💡 一句话要点
提出RAWG,一种奖励驱动的自动化Webshell恶意代码生成器,用于红队演练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Webshell 恶意代码生成 红队演练 大型语言模型 强化学习
📋 核心要点
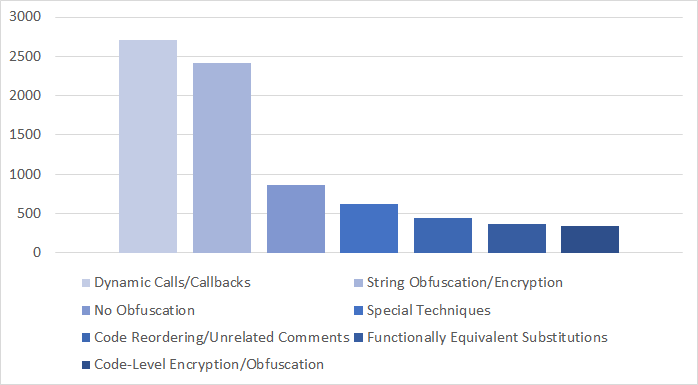
- 现有Webshell恶意代码生成方法依赖提示工程,存在有效载荷多样性不足和冗余度高等问题。
- RAWG通过对Webshell样本进行分类和标准化,并结合监督微调和强化学习,生成多样且高混淆的恶意代码。
- 实验表明,RAWG在有效载荷多样性和逃逸有效性方面显著优于现有方法,提升了红队演练的效率。
📝 摘要(中文)
频繁的网络攻击使得WebShell的利用和防御成为网络安全领域重要的研究课题。然而,目前公开的、按混淆方法良好分类的恶意代码数据集仍然严重不足。现有的恶意代码生成方法主要依赖于提示工程,其生成的有效载荷通常存在多样性有限和冗余度高等问题。为了解决这些局限性,我们提出了一种奖励驱动的自动化Webshell恶意代码生成器RAWG,专为红队应用设计。我们的方法首先将常见数据集中的webshell样本分为七种不同的混淆类型。然后,我们使用大型语言模型(LLM)从每个样本中提取和标准化关键token,从而创建一个标准化的、高质量的语料库。使用这个精心策划的数据集,我们对一个开源的大型模型进行监督微调(SFT),以实现生成多样化的、高度混淆的webshell恶意有效载荷。为了进一步提高生成质量,我们应用近端策略优化(PPO),在强化学习期间将恶意代码样本视为“选择”数据,将良性代码视为“拒绝”数据。大量的实验表明,RAWG在有效载荷多样性和逃逸有效性方面都显著优于当前最先进的方法。
🔬 方法详解
问题定义:该论文旨在解决Webshell恶意代码生成中数据集不足、现有方法生成代码多样性差和冗余度高的问题。现有方法主要依赖提示工程,难以生成高质量、多样化的恶意代码,这限制了红队演练的效果。
核心思路:论文的核心思路是利用大型语言模型(LLM)和强化学习,通过奖励机制驱动生成器生成更有效、更具多样性的Webshell恶意代码。通过对Webshell样本进行分类、提取关键token并进行标准化,构建高质量的训练数据集,从而提升生成器的性能。
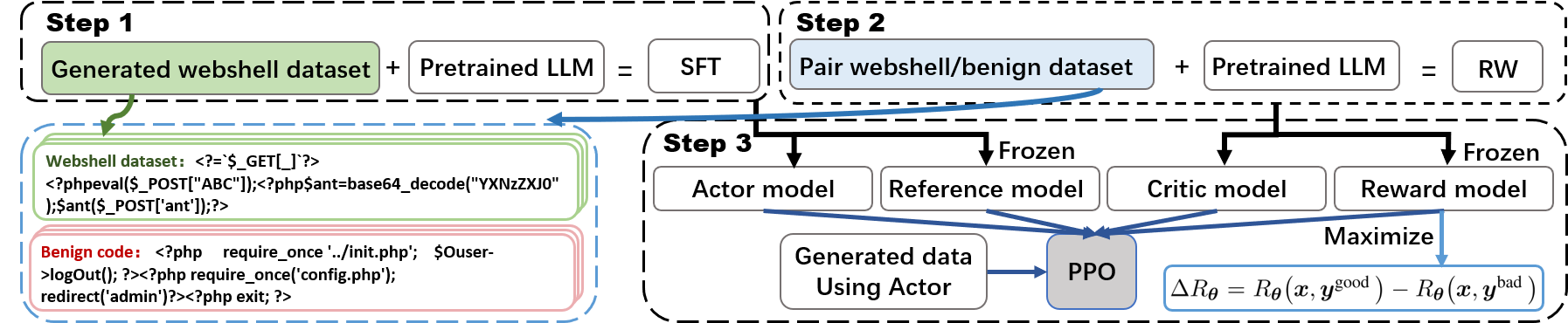
技术框架:RAWG的整体框架包括以下几个主要阶段:1) Webshell样本分类:将Webshell样本按照混淆类型进行分类;2) 关键Token提取与标准化:使用LLM从样本中提取关键token,并进行标准化处理,构建高质量语料库;3) 监督微调(SFT):利用构建的语料库对开源LLM进行监督微调,使其具备生成Webshell恶意代码的能力;4) 强化学习(PPO):使用近端策略优化算法,通过奖励机制进一步优化生成器,提高生成代码的质量和多样性。
关键创新:该论文的关键创新在于结合了监督微调和强化学习,并引入了奖励机制来指导Webshell恶意代码的生成。与传统的基于提示工程的方法相比,RAWG能够生成更具多样性和逃逸能力的恶意代码。此外,对Webshell样本进行分类和标准化,构建高质量的训练数据集也是一个重要的创新点。
关键设计:在监督微调阶段,使用了开源LLM作为基础模型,并利用构建的Webshell语料库进行微调。在强化学习阶段,使用了近端策略优化(PPO)算法,将恶意代码样本视为“选择”数据,将良性代码视为“拒绝”数据,通过奖励函数来引导生成器生成更符合要求的恶意代码。奖励函数的具体设计未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RAWG在有效载荷多样性和逃逸有效性方面显著优于当前最先进的方法。具体的性能数据和提升幅度在摘要中有所提及,但未给出具体数值。该研究验证了基于奖励驱动的自动化Webshell恶意代码生成方法的可行性和有效性。
🎯 应用场景
RAWG可应用于红队演练、渗透测试和网络安全防御等领域。通过自动化生成多样化的Webshell恶意代码,可以帮助安全人员更好地评估和提升系统的安全性,发现潜在的安全漏洞,并提高防御能力。该研究还有助于构建更完善的恶意代码数据集,促进网络安全研究的发展。
📄 摘要(原文)
Frequent cyber-attacks have elevated WebShell exploitation and defense to a critical research focus within network security. However, there remains a significant shortage of publicly available, well-categorized malicious-code datasets organized by obfuscation method. Existing malicious-code generation methods, which primarily rely on prompt engineering, often suffer from limited diversity and high redundancy in the payloads they produce. To address these limitations, we propose \textbf{RAWG}, a \textbf{R}eward-driven \textbf{A}utomated \textbf{W}ebshell Malicious-code \textbf{G}enerator designed for red-teaming applications. Our approach begins by categorizing webshell samples from common datasets into seven distinct types of obfuscation. We then employ a large language model (LLM) to extract and normalize key tokens from each sample, creating a standardized, high-quality corpus. Using this curated dataset, we perform supervised fine-tuning (SFT) on an open-source large model to enable the generation of diverse, highly obfuscated webshell malicious payloads. To further enhance generation quality, we apply Proximal Policy Optimization (PPO), treating malicious-code samples as "chosen" data and benign code as "rejected" data during reinforcement learning. Extensive experiments demonstrate that RAWG significantly outperforms current state-of-the-art methods in both payload diversity and escape effectiveness.