Reinforced Reasoning for Embodied Planning
作者: Di Wu, Jiaxin Fan, Junzhe Zang, Guanbo Wang, Wei Yin, Wenhao Li, Bo Jin
分类: cs.AI, cs.LG
发布日期: 2025-05-28 (更新: 2025-07-13)
💡 一句话要点
提出基于强化学习的推理框架,提升具身智能规划任务中的决策能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 强化学习 视觉-语言模型 规划 推理 模仿学习 偏好优化
📋 核心要点
- 现有视觉-语言模型在具身智能规划中,缺乏时间推理、空间理解和常识基础,难以进行有效决策。
- 论文提出一种强化微调框架,通过监督微调和强化偏好优化,提升模型在交互环境中的推理和规划能力。
- 实验表明,该方法在Embench基准测试中显著优于其他模型,并在未见过的环境中表现出良好的泛化能力。
📝 摘要(中文)
具身智能规划要求智能体基于动态视觉观察和自然语言目标做出连贯的多步决策。尽管最近的视觉-语言模型(VLMs)在静态感知任务中表现出色,但它们在交互环境中进行规划所需的时间推理、空间理解和常识基础方面存在困难。本文介绍了一种强化微调框架,将R1风格的推理增强引入到具身规划中。我们首先从一个强大的闭源模型中提炼出一个高质量的数据集,并执行监督微调(SFT)来使模型具备结构化的决策先验。然后,我们设计了一个针对多步动作质量的基于规则的奖励函数,并通过广义强化偏好优化(GRPO)来优化策略。我们的方法在Embench上进行了评估,Embench是最近的一个交互式具身任务基准,涵盖了领域内和领域外的场景。实验结果表明,我们的方法显著优于类似或更大规模的模型,包括GPT-4o-mini和70B+开源基线,并且对未见过的环境表现出强大的泛化能力。这项工作突出了强化驱动推理在推进具身AI中的长时程规划方面的潜力。
🔬 方法详解
问题定义:具身智能规划任务需要智能体在动态环境中,根据视觉信息和自然语言目标,做出连续的、合理的动作序列。现有方法,特别是依赖于大型视觉-语言模型的方法,在处理时间依赖关系、空间关系以及常识推理方面存在不足,导致规划效果不佳。这些模型难以有效地将视觉感知与长期决策相结合。
核心思路:论文的核心思路是利用强化学习来提升视觉-语言模型在具身智能规划中的推理能力。通过模仿学习(监督微调)赋予模型初步的决策能力,然后利用强化学习优化策略,使其能够更好地适应交互环境,并做出更合理的长期规划。这种方法结合了视觉-语言模型的感知能力和强化学习的决策优化能力。
技术框架:整体框架包含两个主要阶段:1) 监督微调(SFT):使用从一个强大的闭源模型蒸馏出的高质量数据集,对视觉-语言模型进行微调,使其具备结构化的决策先验知识。2) 强化学习优化:设计一个基于规则的奖励函数,该函数针对多步动作的质量进行评估。然后,使用广义强化偏好优化(GRPO)算法来优化策略,使其能够最大化累积奖励。
关键创新:该方法的关键创新在于将R1风格的推理增强引入到具身规划中,并利用强化学习来优化模型的长期决策能力。与传统的监督学习方法相比,强化学习能够更好地适应动态环境,并学习到更有效的策略。此外,使用GRPO算法能够更有效地利用奖励信号,从而提升模型的性能。
关键设计:奖励函数的设计是关键。论文设计了一个基于规则的奖励函数,用于评估多步动作的质量。具体细节未知,但可以推测其考虑了动作的合理性、效率以及是否能够达到目标。GRPO算法的具体参数设置未知,但需要根据具体任务进行调整。此外,数据集的质量对监督微调的效果至关重要,因此需要精心设计数据收集和清洗流程。
🖼️ 关键图片
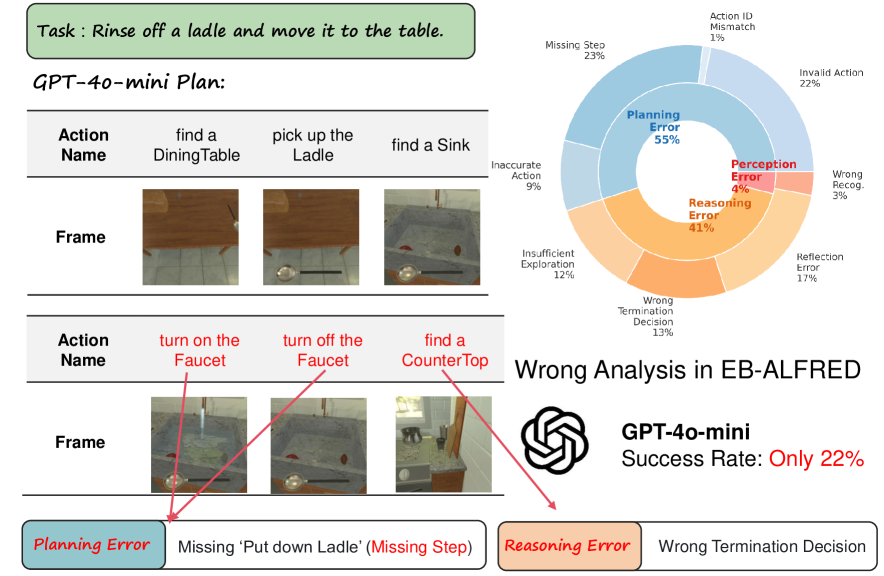

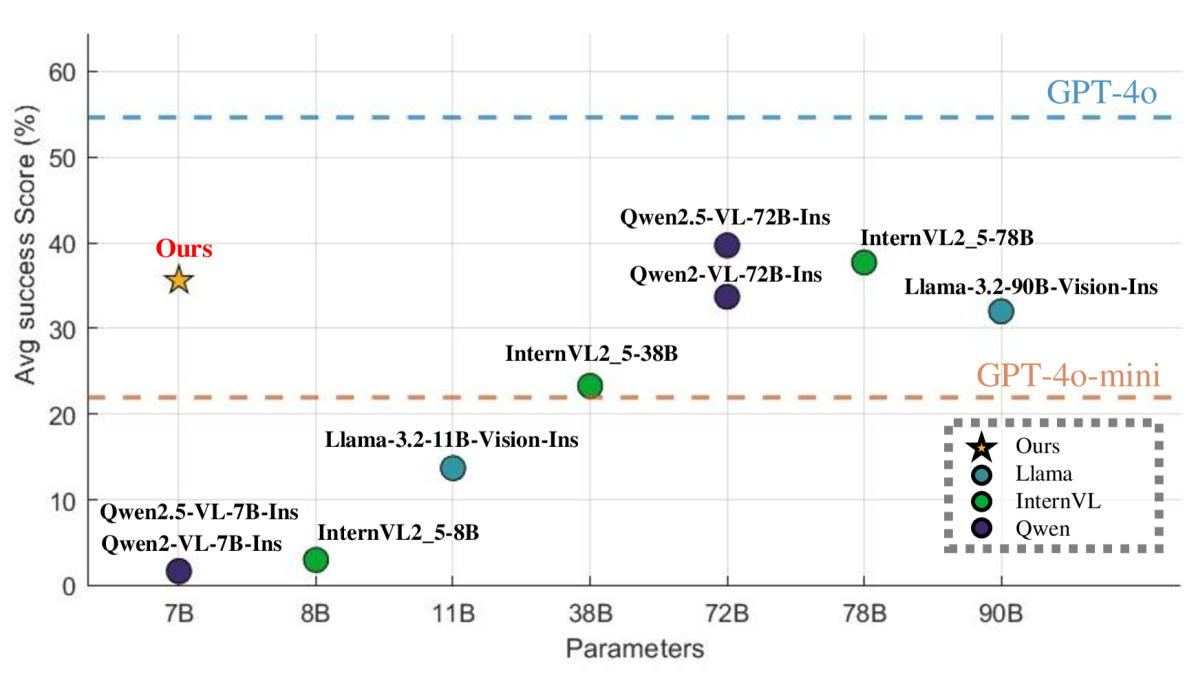
📊 实验亮点
实验结果表明,该方法在Embench基准测试中显著优于其他模型,包括GPT-4o-mini和70B+开源基线。该方法在领域内和领域外场景中均表现出良好的泛化能力,证明了强化驱动推理在提升具身智能规划能力方面的有效性。具体性能提升幅度未知,但摘要强调了“显著优于”这一结果。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、自动驾驶等领域。通过提升智能体在复杂环境中的规划和决策能力,可以实现更智能、更自主的机器人系统,从而提高生产效率、改善生活质量,并降低人工成本。未来,该技术有望应用于更广泛的具身智能任务中。
📄 摘要(原文)
Embodied planning requires agents to make coherent multi-step decisions based on dynamic visual observations and natural language goals. While recent vision-language models (VLMs) excel at static perception tasks, they struggle with the temporal reasoning, spatial understanding, and commonsense grounding needed for planning in interactive environments. In this work, we introduce a reinforcement fine-tuning framework that brings R1-style reasoning enhancement into embodied planning. We first distill a high-quality dataset from a powerful closed-source model and perform supervised fine-tuning (SFT) to equip the model with structured decision-making priors. We then design a rule-based reward function tailored to multi-step action quality and optimize the policy via Generalized Reinforced Preference Optimization (GRPO). Our approach is evaluated on Embench, a recent benchmark for interactive embodied tasks, covering both in-domain and out-of-domain scenarios. Experimental results show that our method significantly outperforms models of similar or larger scale, including GPT-4o-mini and 70B+ open-source baselines, and exhibits strong generalization to unseen environments. This work highlights the potential of reinforcement-driven reasoning to advance long-horizon planning in embodied AI.