Extracting Research Instruments from Educational Literature Using LLMs
作者: Jiseung Yoo, Curran Mahowald, Meiyu Li, Wei Ai
分类: cs.IR, cs.AI
发布日期: 2025-05-28
💡 一句话要点
利用大型语言模型从教育文献中提取研究工具信息
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息提取 教育文献 研究工具 多步提示
📋 核心要点
- 现有方法难以有效提取教育文献中研究工具的详细信息,阻碍了教育研究的知识管理和决策。
- 该研究提出一种基于大型语言模型的多步提示系统,利用领域特定数据模式提取结构化研究工具信息。
- 实验结果表明,该系统在识别研究工具名称和详细信息方面显著优于其他方法,提升了信息提取的准确性。
📝 摘要(中文)
大型语言模型(LLMs)正在变革学术文献的信息提取方式,为知识管理提供了新的可能性。本研究提出了一种基于LLM的系统,旨在提取教育领域研究工具的详细信息,包括工具名称、类型、目标受访者、测量结构和结果。该系统采用多步提示和领域特定的数据模式,生成针对教育研究优化的结构化输出。评估结果表明,该系统显著优于其他方法,尤其是在识别工具名称和详细信息方面。这证明了LLM驱动的信息提取在教育领域的潜力,提供了一种系统化的方式来组织研究工具信息。大规模聚合此类信息的能力增强了研究人员和教育领导者的可访问性,从而促进了教育研究和政策中的知情决策。
🔬 方法详解
问题定义:本论文旨在解决教育文献中研究工具信息提取的问题。现有方法,例如传统的信息提取技术,在处理非结构化文本时效率低下,难以准确识别和提取研究工具的名称、类型、目标受访者、测量结构和结果等详细信息。这使得研究人员难以系统地组织和利用这些信息,从而影响了教育研究和政策的制定。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的自然语言理解和生成能力,通过设计合适的多步提示策略和领域特定的数据模式,引导LLM从教育文献中提取结构化的研究工具信息。这种方法旨在克服传统信息提取技术的局限性,提高信息提取的准确性和效率。
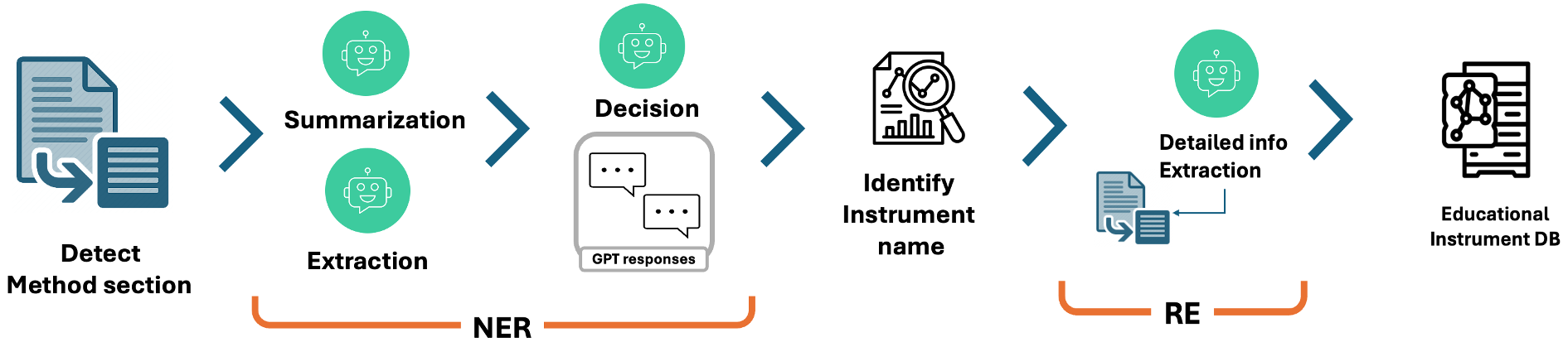
技术框架:该系统的整体框架包括以下几个主要阶段:1) 文献输入:输入教育领域的学术文献。2) 多步提示:设计一系列提示,引导LLM逐步提取研究工具的各个方面的信息,例如名称、类型、目标受访者等。3) 数据模式定义:定义领域特定的数据模式,用于规范化LLM的输出,确保输出信息的结构化和一致性。4) LLM推理:使用LLM对文献进行推理,根据提示和数据模式提取信息。5) 结构化输出:生成结构化的研究工具信息,例如JSON格式的数据。
关键创新:该研究的关键创新在于将大型语言模型应用于教育文献的研究工具信息提取,并设计了多步提示策略和领域特定的数据模式。与传统的信息提取方法相比,该方法能够更准确、更全面地提取研究工具的详细信息,并且能够生成结构化的输出,方便研究人员使用。
关键设计:多步提示策略的设计是关键。例如,可以先提示LLM识别文献中使用的研究工具的名称,然后再提示LLM提取该工具的类型、目标受访者等信息。领域特定的数据模式也至关重要,它定义了输出信息的结构和格式,确保输出信息的规范化和一致性。具体的参数设置和网络结构取决于所使用的LLM,例如可以使用GPT-3或类似的预训练语言模型,并根据具体任务进行微调。
🖼️ 关键图片

📊 实验亮点
该研究表明,基于LLM的系统在提取研究工具信息方面显著优于其他方法。尤其是在识别工具名称和详细信息方面,该系统表现出更高的准确率和召回率。具体的性能数据在论文中进行了详细的展示,与其他基线方法进行了对比,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于教育研究领域,帮助研究人员快速检索和分析已有的研究工具,从而提高研究效率和质量。此外,教育领导者可以利用该系统获取关于研究工具的全面信息,为教育政策的制定提供依据。未来,该技术可扩展到其他领域,例如医学、社会科学等,促进跨领域知识共享和创新。
📄 摘要(原文)
Large Language Models (LLMs) are transforming information extraction from academic literature, offering new possibilities for knowledge management. This study presents an LLM-based system designed to extract detailed information about research instruments used in the education field, including their names, types, target respondents, measured constructs, and outcomes. Using multi-step prompting and a domain-specific data schema, it generates structured outputs optimized for educational research. Our evaluation shows that this system significantly outperforms other approaches, particularly in identifying instrument names and detailed information. This demonstrates the potential of LLM-powered information extraction in educational contexts, offering a systematic way to organize research instrument information. The ability to aggregate such information at scale enhances accessibility for researchers and education leaders, facilitating informed decision-making in educational research and policy.