Scientific Paper Retrieval with LLM-Guided Semantic-Based Ranking
作者: Yunyi Zhang, Ruozhen Yang, Siqi Jiao, SeongKu Kang, Jiawei Han
分类: cs.IR, cs.AI, cs.CL
发布日期: 2025-05-27 (更新: 2025-10-06)
备注: Accepted to EMNLP 2025 Findings
💡 一句话要点
SemRank:利用LLM引导的语义排序进行科学论文检索
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学论文检索 大型语言模型 语义索引 查询理解 概念提取
📋 核心要点
- 现有稠密检索方法难以捕捉科学查询中细粒度的科学概念,影响检索准确性。
- SemRank框架结合LLM引导的查询理解和基于概念的语义索引,提升检索性能。
- 实验结果表明,SemRank优于现有LLM基线,并能有效提升多种基础检索器的性能。
📝 摘要(中文)
科学论文检索对于文献发现和研究至关重要。虽然稠密检索方法在通用任务中表现出有效性,但它们通常无法捕捉到细粒度的科学概念,而这些概念对于准确理解科学查询至关重要。最近的研究也使用大型语言模型(LLM)进行查询理解;然而,这些方法通常缺乏对特定语料库知识的 grounding,并可能生成不可靠或不忠实的内容。为了克服这些限制,我们提出了一种有效且高效的论文检索框架SemRank,该框架将LLM引导的查询理解与基于概念的语义索引相结合。每篇论文都使用多粒度的科学概念进行索引,包括一般研究主题和详细的关键短语。在查询时,LLM识别源自语料库的核心概念,以明确捕捉查询的信息需求。这些识别出的概念能够实现精确的语义匹配,从而显著提高检索准确性。实验表明,SemRank始终如一地提高了各种基础检索器的性能,超过了现有的强大的基于LLM的基线,并且保持了高效性。
🔬 方法详解
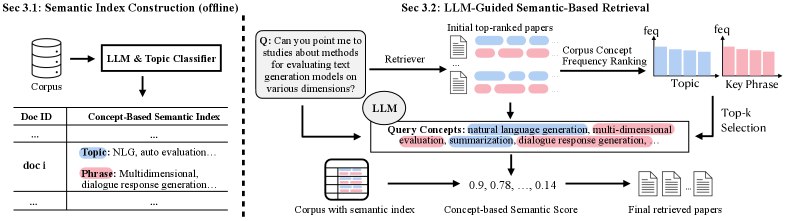
问题定义:科学论文检索面临的挑战是如何准确理解科学查询中蕴含的细粒度语义信息。现有的稠密检索方法虽然在通用领域表现良好,但在科学领域,由于专业术语和复杂概念的存在,难以有效捕捉查询的真实意图。此外,直接使用LLM进行查询理解的方法,缺乏对特定领域知识的 grounding,可能产生不准确或不相关的结果。
核心思路:SemRank的核心思路是利用LLM从语料库中提取关键概念,并将其作为桥梁,连接查询和文档。通过将查询和文档都表示为概念的集合,可以实现更精确的语义匹配,从而提高检索准确性。这种方法既利用了LLM的强大理解能力,又避免了其在领域知识方面的不足。
技术框架:SemRank框架主要包含两个阶段:索引阶段和检索阶段。在索引阶段,首先对每篇论文进行分析,提取多粒度的科学概念,包括一般研究主题和详细的关键短语。然后,利用这些概念构建语义索引。在检索阶段,首先使用LLM识别查询中的核心概念,这些概念来源于已索引的语料库。然后,利用这些概念在语义索引中进行匹配,检索与查询相关的论文。
关键创新:SemRank的关键创新在于将LLM的查询理解能力与基于概念的语义索引相结合。与直接使用LLM生成查询表示的方法不同,SemRank利用LLM从语料库中提取概念,并将其作为检索的依据。这种方法既能有效利用LLM的理解能力,又能避免其在领域知识方面的不足。此外,SemRank使用多粒度的科学概念进行索引,能够更全面地捕捉论文的语义信息。
关键设计:SemRank的关键设计包括:1) 如何利用LLM从语料库中提取高质量的概念;2) 如何构建有效的语义索引,以便快速检索与查询相关的论文;3) 如何平衡不同粒度概念的重要性,以实现最佳的检索效果。具体的技术细节,例如LLM的选择、概念提取的策略、索引结构的设计等,需要在实际应用中进行调整和优化。
🖼️ 关键图片

📊 实验亮点
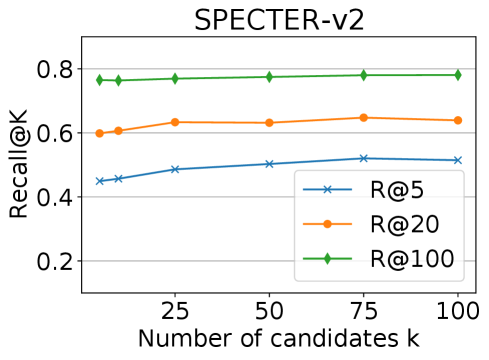
实验结果表明,SemRank在科学论文检索任务中取得了显著的性能提升。与现有的基于LLM的基线方法相比,SemRank在检索准确率方面有明显优势。此外,SemRank能够有效提升各种基础检索器的性能,表明其具有良好的通用性和可扩展性。具体性能数据在论文中进行了详细展示。
🎯 应用场景
SemRank可应用于各种科学研究领域,帮助研究人员快速准确地找到相关的文献资料。该方法能够提升文献综述的效率,加速科研创新过程。未来,SemRank可以扩展到其他专业领域,例如医学、工程等,为各领域的知识发现提供有力支持。此外,SemRank还可以应用于智能问答系统,为用户提供更准确的答案。
📄 摘要(原文)
Scientific paper retrieval is essential for supporting literature discovery and research. While dense retrieval methods demonstrate effectiveness in general-purpose tasks, they often fail to capture fine-grained scientific concepts that are essential for accurate understanding of scientific queries. Recent studies also use large language models (LLMs) for query understanding; however, these methods often lack grounding in corpus-specific knowledge and may generate unreliable or unfaithful content. To overcome these limitations, we propose SemRank, an effective and efficient paper retrieval framework that combines LLM-guided query understanding with a concept-based semantic index. Each paper is indexed using multi-granular scientific concepts, including general research topics and detailed key phrases. At query time, an LLM identifies core concepts derived from the corpus to explicitly capture the query's information need. These identified concepts enable precise semantic matching, significantly enhancing retrieval accuracy. Experiments show that SemRank consistently improves the performance of various base retrievers, surpasses strong existing LLM-based baselines, and remains highly efficient.