Towards Safety Reasoning in LLMs: AI-agentic Deliberation for Policy-embedded CoT Data Creation
作者: Tharindu Kumarage, Ninareh Mehrabi, Anil Ramakrishna, Xinyan Zhao, Richard Zemel, Kai-Wei Chang, Aram Galstyan, Rahul Gupta, Charith Peris
分类: cs.AI, cs.CL
发布日期: 2025-05-27
备注: Accepted to ACL 2025 (Findings)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出AIDSAFE,通过多智能体迭代审议生成策略嵌入的CoT数据,提升LLM安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 安全推理 LLM安全 思维链 多智能体系统 数据生成 越狱防御 策略对齐 信念增强
📋 核心要点
- 现有LLM安全措施存在过度拒绝和越狱漏洞,安全推理范式旨在通过策略推理缓解这些问题,但高质量策略嵌入CoT数据生成成本高昂。
- AIDSAFE利用多智能体审议迭代扩展安全策略推理,并通过数据提炼消除冗余和欺骗性思维,生成高质量CoT数据。
- 实验表明,基于AIDSAFE生成的CoT微调LLM,能显著提升安全泛化能力和越狱鲁棒性,同时保持良好的效用和避免过度拒绝。
📝 摘要(中文)
安全推理是一种新兴范式,其中LLM在生成响应之前对安全策略进行推理,从而缓解现有安全措施(如过度拒绝和越狱漏洞)的局限性。然而,由于创建高质量策略嵌入的思维链(CoT)数据集的过程资源密集,同时要确保推理保持准确且没有幻觉或策略冲突,因此实施这种范式具有挑战性。为了解决这个问题,我们提出了AIDSAFE:用于安全推理的智能体迭代审议,这是一种新颖的数据生成方法,它利用多智能体审议来迭代扩展对安全策略的推理。AIDSAFE中的数据提炼阶段通过消除重复、冗余和欺骗性思维来确保高质量的输出。AIDSAFE生成的CoT为基于监督微调(SFT)的安全训练提供了坚实的基础。此外,为了满足对齐阶段(如DPO训练)中对偏好数据的需求,我们引入了一种补充方法,该方法使用信念增强来创建不同的选择和拒绝的CoT样本。我们的评估表明,AIDSAFE生成的CoT实现了卓越的策略遵守和推理质量。因此,我们表明,在这些CoT上微调开源LLM可以显著提高安全泛化和越狱鲁棒性,同时保持可接受的效用和过度拒绝准确性。AIDSAFE生成的CoT数据集可以在https://huggingface.co/datasets/AmazonScience/AIDSAFE找到。
🔬 方法详解
问题定义:论文旨在解决LLM安全推理中高质量策略嵌入CoT数据生成困难的问题。现有方法要么成本高昂,要么无法保证推理的准确性和避免幻觉或策略冲突,导致模型容易出现越狱漏洞和过度拒绝等问题。
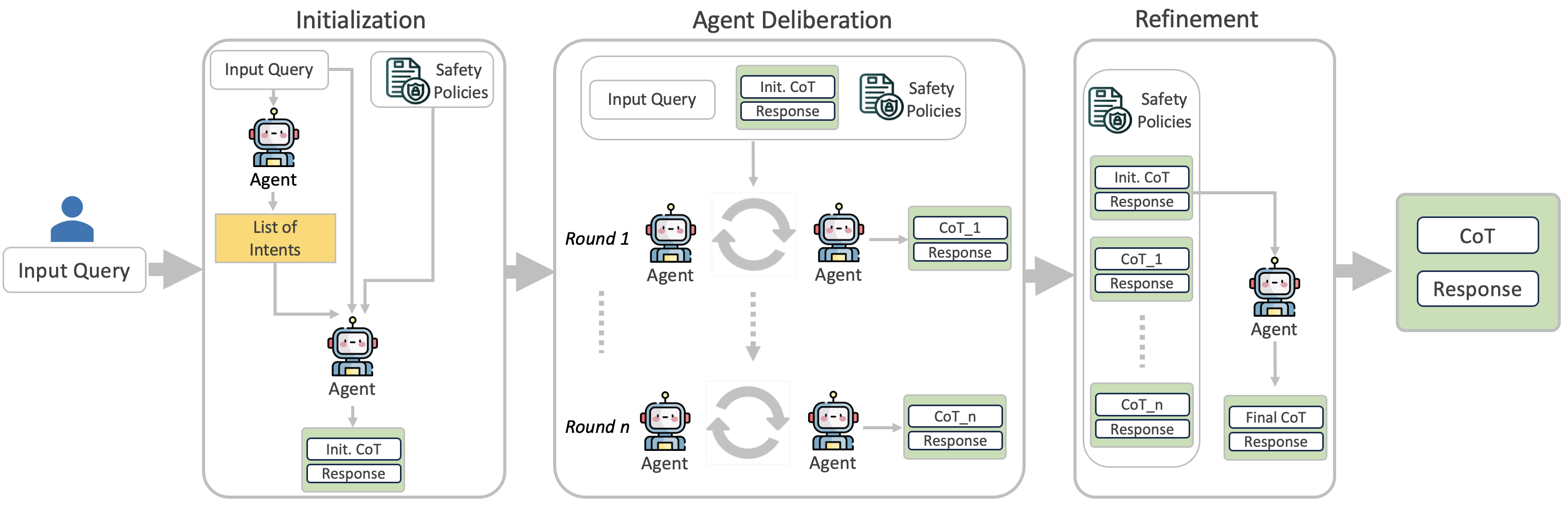
核心思路:论文的核心思路是利用多智能体审议(Multi-agent Deliberation)来迭代地扩展对安全策略的推理。通过多个智能体之间的讨论和辩论,可以更全面地覆盖各种安全场景和策略,从而生成更丰富、更准确的CoT数据。此外,引入数据提炼阶段,过滤掉重复、冗余和欺骗性的思维,确保数据的质量。
技术框架:AIDSAFE包含两个主要阶段:智能体迭代审议和数据提炼。在智能体迭代审议阶段,多个智能体针对给定的安全问题进行讨论,每个智能体负责从不同的角度或策略出发进行推理。通过多轮迭代,逐步完善推理过程,生成CoT数据。在数据提炼阶段,使用一系列规则和算法,对生成的CoT数据进行清洗和过滤,去除低质量的数据,保留高质量的推理链。此外,论文还提出了一个补充方法,使用信念增强来创建用于偏好学习(如DPO)的选定和拒绝的CoT样本。
关键创新:AIDSAFE的关键创新在于其多智能体审议的数据生成方法。与传统的单智能体生成CoT数据相比,多智能体审议可以更全面地覆盖各种安全场景和策略,从而生成更丰富、更准确的CoT数据。此外,数据提炼阶段可以有效提高数据的质量,避免模型学习到错误的或有害的信息。
关键设计:在智能体迭代审议阶段,需要设计合适的智能体角色和交互机制。例如,可以设置一个“策略专家”智能体,负责提供安全策略的指导;一个“用户模拟”智能体,负责模拟用户的行为;一个“安全评估”智能体,负责评估推理过程的安全性。在数据提炼阶段,需要设计有效的规则和算法,用于识别和过滤低质量的CoT数据。例如,可以使用重复度检测算法,去除重复的推理步骤;可以使用语义相似度算法,去除冗余的推理步骤;可以使用安全策略冲突检测算法,去除违反安全策略的推理步骤。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用AIDSAFE生成的CoT数据微调的LLM,在安全泛化能力和越狱鲁棒性方面均有显著提升。具体而言,模型在多个安全测试集上的表现优于基线模型,并且能够有效抵抗各种越狱攻击。同时,模型在保持良好效用的前提下,降低了过度拒绝的概率。
🎯 应用场景
AIDSAFE可应用于各种需要安全保障的LLM应用场景,如智能客服、内容生成、代码生成等。通过提升LLM的安全性和鲁棒性,可以减少有害信息传播、防止模型被恶意利用,并提高用户对LLM的信任度。该研究成果有助于推动LLM在安全敏感领域的广泛应用。
📄 摘要(原文)
Safety reasoning is a recent paradigm where LLMs reason over safety policies before generating responses, thereby mitigating limitations in existing safety measures such as over-refusal and jailbreak vulnerabilities. However, implementing this paradigm is challenging due to the resource-intensive process of creating high-quality policy-embedded chain-of-thought (CoT) datasets while ensuring reasoning remains accurate and free from hallucinations or policy conflicts. To tackle this, we propose AIDSAFE: Agentic Iterative Deliberation for Safety Reasoning, a novel data generation recipe that leverages multi-agent deliberation to iteratively expand reasoning on safety policies. A data refiner stage in AIDSAFE ensures high-quality outputs by eliminating repetitive, redundant, and deceptive thoughts. AIDSAFE-generated CoTs provide a strong foundation for supervised fine-tuning (SFT)-based safety training. Additionally, to address the need of preference data in alignment stages, such as DPO training, we introduce a supplemental recipe that uses belief augmentation to create distinct selected and rejected CoT samples. Our evaluations demonstrate that AIDSAFE-generated CoTs achieve superior policy adherence and reasoning quality. Consequently, we show that fine-tuning open-source LLMs on these CoTs can significantly improve safety generalization and jailbreak robustness while maintaining acceptable utility and over-refusal accuracy. AIDSAFE-generated CoT datasets can be found here: https://huggingface.co/datasets/AmazonScience/AIDSAFE