Policy Induction: Predicting Startup Success via Explainable Memory-Augmented In-Context Learning
作者: Xianling Mu, Joseph Ternasky, Fuat Alican, Yigit Ihlamur
分类: cs.AI, cs.LG
发布日期: 2025-05-27 (更新: 2025-06-04)
💡 一句话要点
提出基于可解释记忆增强上下文学习的策略归纳方法,预测初创公司成功率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 大型语言模型 初创公司投资 策略归纳 可解释性 少样本学习 风险投资 记忆增强
📋 核心要点
- 现有机器学习方法在初创公司投资预测中面临数据稀缺、模型不透明和难以解释改进的挑战。
- 论文提出一种基于记忆增强LLM的上下文学习框架,通过嵌入自然语言策略实现透明决策。
- 实验表明,该系统在预测初创公司成功率方面显著优于现有基准,精度远超随机机会和顶级风投。
📝 摘要(中文)
早期初创公司投资是高风险行为,数据稀缺且结果不确定。传统机器学习方法通常需要大量标注数据和广泛的微调,但对于领域专家来说,其过程不透明且难以解释或改进。本文提出了一种透明且数据高效的投资决策框架,该框架由使用上下文学习(ICL)的记忆增强大型语言模型(LLM)提供支持。该方法的核心是将自然语言策略直接嵌入到LLM提示中,使模型能够应用显式推理模式,并允许人类专家轻松地解释、审计和迭代地改进逻辑。我们引入了一个轻量级的训练过程,该过程将少样本学习与上下文学习循环相结合,使LLM能够根据结构化反馈迭代地更新其决策策略。仅需最少的监督且无需基于梯度的优化,我们的系统预测初创公司成功的准确率远高于现有基准。其精度是随机机会(成功率为1.9%)的20倍以上,也是顶级风险投资(VC)公司典型成功率(5.6%)的7.1倍。
🔬 方法详解
问题定义:论文旨在解决早期初创公司投资决策中数据稀缺、模型不透明以及难以解释和改进的问题。现有机器学习方法需要大量标注数据,且模型决策过程难以理解,阻碍了领域专家的参与和优化。
核心思路:论文的核心思路是利用大型语言模型(LLM)的上下文学习能力,通过在LLM提示中嵌入自然语言策略,使模型能够进行显式推理,从而实现透明、可解释的投资决策。这种方法允许人类专家直接理解和改进模型的决策逻辑。
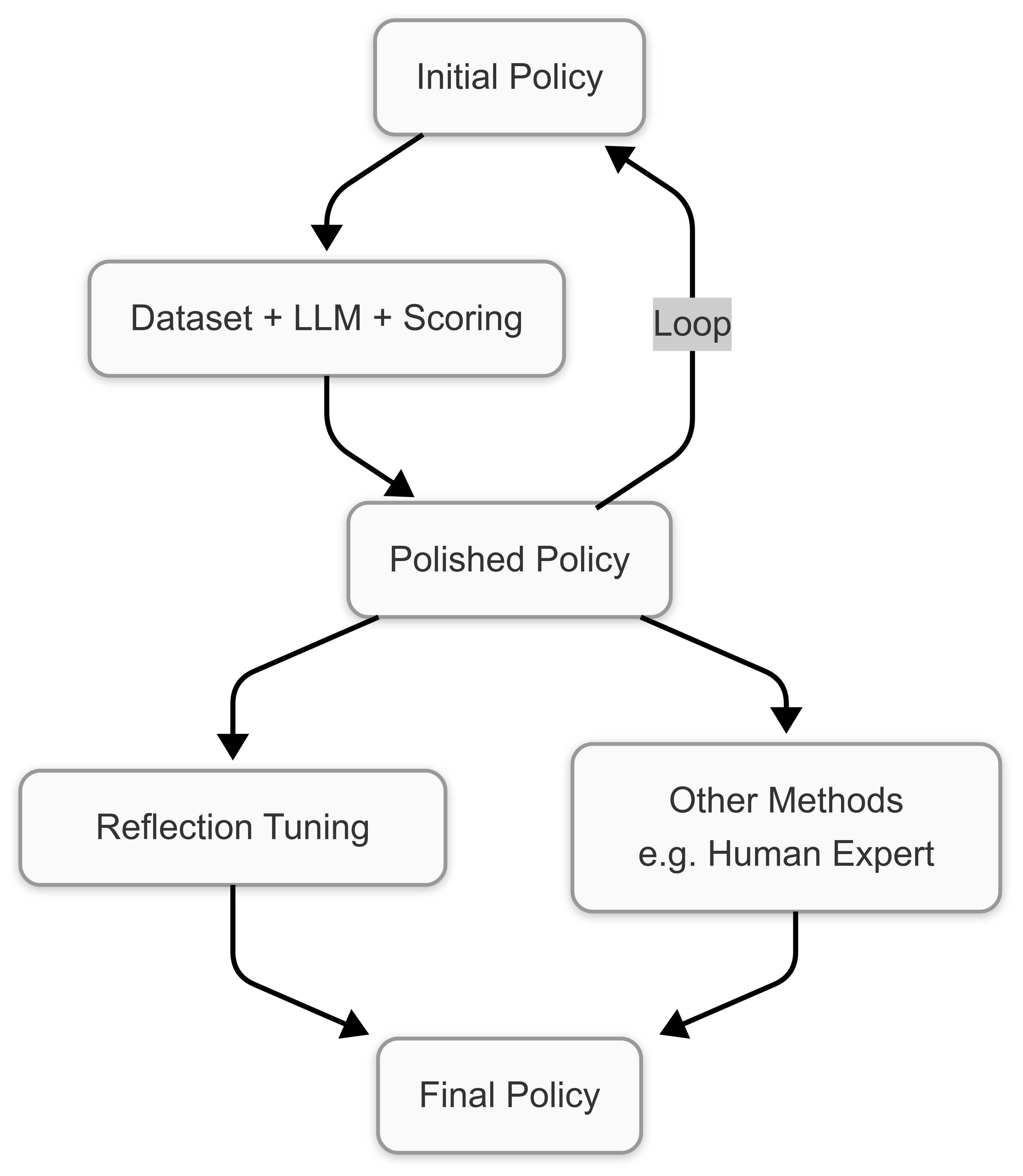
技术框架:该框架包含以下主要步骤:1) 构建包含初创公司信息的记忆库;2) 将自然语言形式的投资策略嵌入到LLM的提示中;3) 利用上下文学习,让LLM根据提示和记忆库中的信息进行投资决策;4) 引入一个轻量级的训练过程,结合少样本学习和上下文学习循环,根据结构化反馈迭代更新LLM的决策策略。
关键创新:最重要的技术创新点在于将自然语言策略直接嵌入到LLM的提示中,从而实现了可解释的投资决策。与传统的黑盒机器学习模型不同,该方法允许用户直接理解和修改模型的决策逻辑,提高了模型的可信度和可控性。
关键设计:论文采用少样本学习,仅需少量标注数据即可训练模型。通过上下文学习循环,模型可以根据结构化反馈迭代更新其决策策略,无需进行梯度优化。具体的参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该系统在预测初创公司成功率方面显著优于现有基准。其精度是随机机会(1.9%)的20倍以上,也是顶级风险投资(VC)公司典型成功率(5.6%)的7.1倍。这些结果表明,该方法在数据稀缺的情况下也能实现高精度的预测。
🎯 应用场景
该研究成果可应用于早期风险投资、创业孵化器、以及政府科技创新政策制定等领域。通过提供更准确、透明的初创公司成功率预测,可以帮助投资者做出更明智的决策,提高投资回报率,并促进创新生态系统的发展。该方法的可解释性也便于监管机构进行审计和风险评估。
📄 摘要(原文)
Early-stage startup investment is a high-risk endeavor characterized by scarce data and uncertain outcomes. Traditional machine learning approaches often require large, labeled datasets and extensive fine-tuning, yet remain opaque and difficult for domain experts to interpret or improve. In this paper, we propose a transparent and data-efficient investment decision framework powered by memory-augmented large language models (LLMs) using in-context learning (ICL). Central to our method is a natural language policy embedded directly into the LLM prompt, enabling the model to apply explicit reasoning patterns and allowing human experts to easily interpret, audit, and iteratively refine the logic. We introduce a lightweight training process that combines few-shot learning with an in-context learning loop, enabling the LLM to update its decision policy iteratively based on structured feedback. With only minimal supervision and no gradient-based optimization, our system predicts startup success far more accurately than existing benchmarks. It is over 20x more precise than random chance, which succeeds 1.9% of the time. It is also 7.1x more precise than the typical 5.6% success rate of top-tier venture capital (VC) firms.