Text-Queried Audio Source Separation via Hierarchical Modeling
作者: Xinlei Yin, Xiulian Peng, Xue Jiang, Zhiwei Xiong, Yan Lu
分类: cs.SD, cs.AI, cs.LG, eess.AS
发布日期: 2025-05-27 (更新: 2025-12-02)
备注: Accepted by TASLP
💡 一句话要点
提出HSM-TSS,通过分层建模实现文本查询的音频源分离,提升语义一致性和数据效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 音频源分离 文本查询 分层建模 跨模态学习 语义引导 声学重建 Q-Audio AudioMAE
📋 核心要点
- 现有文本查询音频源分离方法难以有效联合建模声学-文本对齐和语义感知分离,依赖大量标注数据。
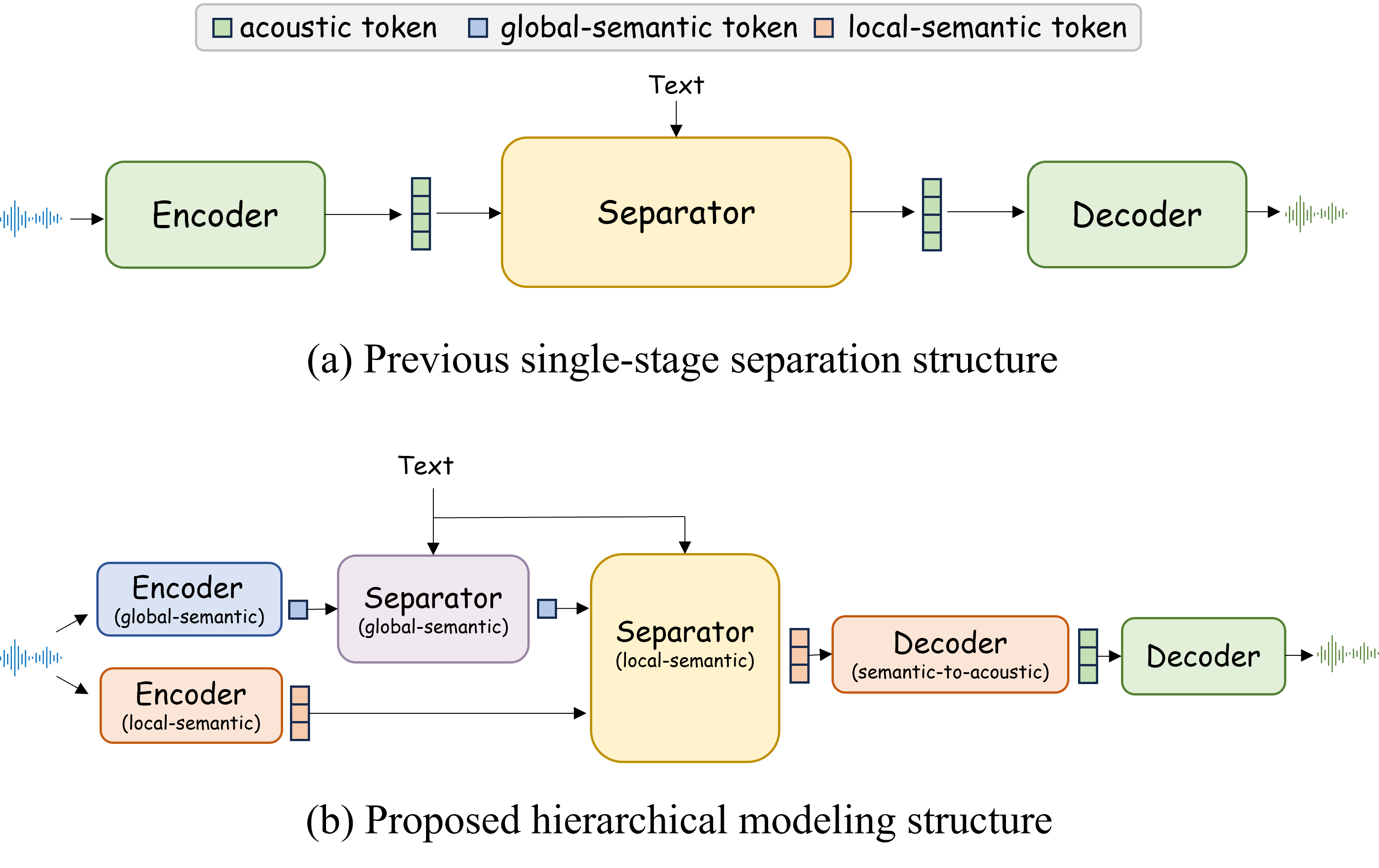
- 提出HSM-TSS框架,解耦任务为全局-局部语义引导的特征分离和结构保持的声学重建,实现更高效的跨模态学习。
- 实验表明,该方法在分离性能上达到SOTA,同时保持了与文本查询的语义一致性,并具有数据高效性。
📝 摘要(中文)
本文提出了一种用于文本查询音频源分离的分层分解框架HSM-TSS,旨在解决现有方法在声学-文本对齐联合建模和语义感知分离方面的困难,以及对大规模精确标注数据的依赖。该框架将任务解耦为全局-局部语义引导的特征分离和结构保持的声学重建。通过双阶段机制在全局和局部语义特征空间上进行语义分离。首先,通过与文本查询对齐的全局语义特征空间进行全局语义分离,利用Q-Audio架构作为预训练的全局语义编码器。然后,在预测的全局特征的条件下,对保留时频结构的AudioMAE特征进行第二阶段的局部语义分离,并进行声学重建。此外,还提出了一个指令处理流程,将任意文本查询解析为结构化操作(提取或移除)以及音频描述,从而实现灵活的声音操作。该方法在复杂听觉场景中实现了最先进的分离性能,并具有数据高效的训练,同时保持了与查询的卓越语义一致性。
🔬 方法详解
问题定义:现有基于文本查询的音频源分离方法面临两个主要痛点:一是难以在单一架构中同时建模声学-文本对齐和语义感知的音频分离;二是需要依赖大规模精确标注的数据来弥补跨模态学习和分离的低效性。这些方法通常无法很好地处理复杂场景下的音频分离任务,并且对训练数据的需求量大。
核心思路:本文的核心思路是将音频源分离任务分解为两个层次:全局语义引导的特征分离和结构保持的声学重建。通过这种分层解耦的方式,可以分别优化语义理解和音频重建,从而提高分离的准确性和效率。此外,利用预训练模型(Q-Audio和AudioMAE)来提取全局和局部特征,减少对大规模标注数据的依赖。
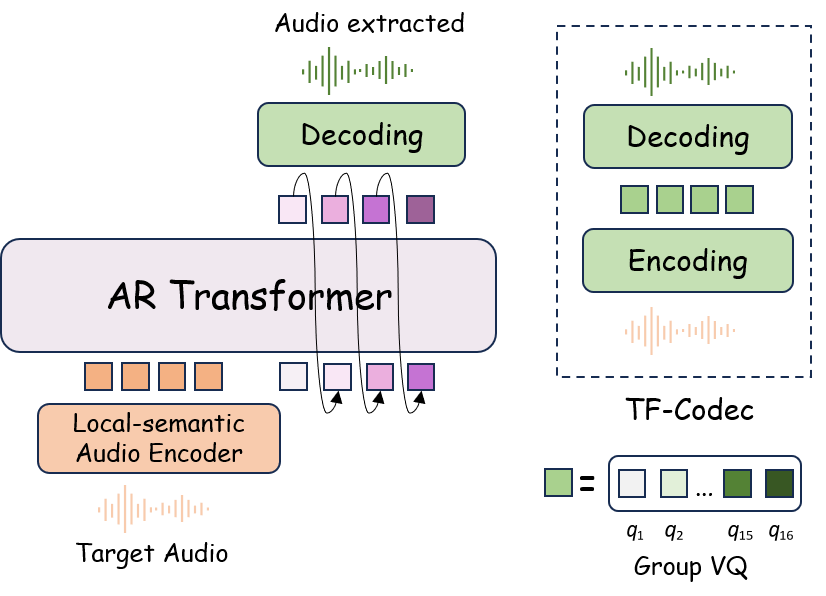
技术框架:HSM-TSS框架包含以下主要模块:1) 全局语义分离:使用Q-Audio架构对音频和文本进行编码,得到全局语义特征,并进行对齐。2) 局部语义分离:在全局语义特征的引导下,使用AudioMAE提取的局部时频结构特征进行分离。3) 声学重建:将分离后的局部特征重建为音频信号。4) 指令处理流程:将文本查询解析为结构化的提取或移除操作,以及音频描述。
关键创新:该方法最重要的创新点在于其分层解耦的框架,将音频源分离任务分解为全局-局部语义引导的特征分离和结构保持的声学重建。这种分解方式使得模型能够更好地理解文本查询的语义,并将其应用于音频分离任务中。此外,指令处理流程的引入使得模型能够处理更复杂的文本查询,实现更灵活的声音操作。
关键设计:1) 使用预训练的Q-Audio模型作为全局语义编码器,以提高声学-文本对齐的效率。2) 使用AudioMAE模型提取局部时频结构特征,以保留音频的细节信息。3) 设计了双阶段的语义分离机制,分别在全局和局部语义特征空间上进行分离。4) 提出了指令处理流程,将文本查询解析为结构化的操作,以实现灵活的声音操作。具体的损失函数和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
该方法在文本查询音频源分离任务上取得了SOTA性能,并在数据效率方面表现出色。相比于现有方法,HSM-TSS在复杂听觉场景中实现了更高的分离精度和更好的语义一致性。具体的性能数据和对比基线在论文中有详细描述(未知),但摘要强调了其优越性。
🎯 应用场景
该研究成果可应用于语音助手、智能音箱等智能设备中,实现更精准的语音指令识别和音频内容提取。例如,用户可以通过自然语言指令从复杂的背景音乐中提取特定乐器的声音。此外,该技术还可应用于音频编辑、音乐创作等领域,为专业人士提供更便捷的音频处理工具。未来,该技术有望在虚拟现实、游戏等领域发挥更大的作用。
📄 摘要(原文)
Target audio source separation with natural language queries presents a promising paradigm for extracting arbitrary audio events through arbitrary text descriptions. Existing methods mainly face two challenges, the difficulty in jointly modeling acoustic-textual alignment and semantic-aware separation within a blindly-learned single-stage architecture, and the reliance on large-scale accurately-labeled training data to compensate for inefficient cross-modal learning and separation. To address these challenges, we propose a hierarchical decomposition framework, HSM-TSS, that decouples the task into global-local semantic-guided feature separation and structure-preserving acoustic reconstruction. Our approach introduces a dual-stage mechanism for semantic separation, operating on distinct global and local semantic feature spaces. We first perform global-semantic separation through a global semantic feature space aligned with text queries. A Q-Audio architecture is employed to align audio and text modalities, serving as pretrained global-semantic encoders. Conditioned on the predicted global feature, we then perform the second-stage local-semantic separation on AudioMAE features that preserve time-frequency structures, followed by acoustic reconstruction. We also propose an instruction processing pipeline to parse arbitrary text queries into structured operations, extraction or removal, coupled with audio descriptions, enabling flexible sound manipulation. Our method achieves state-of-the-art separation performance with data-efficient training while maintaining superior semantic consistency with queries in complex auditory scenes.