From Alignment to Advancement: Bootstrapping Audio-Language Alignment with Synthetic Data
作者: Chun-Yi Kuan, Hung-yi Lee
分类: eess.AS, cs.AI, cs.CL, cs.LG, cs.SD
发布日期: 2025-05-26 (更新: 2026-01-10)
备注: Published in IEEE Transactions on Audio, Speech, and Language Processing (TASLP). Project Website: https://kuan2jiu99.github.io/Balsa
期刊: IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 4604-4619, 2025
DOI: 10.1109/TASLPRO.2025.3626233
💡 一句话要点
BALSa:利用合成数据引导音频-语言对齐,提升ALLM性能并缓解幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频语言模型 多模态学习 合成数据 对比学习 音频幻觉 指令遵循 音频理解 大语言模型
📋 核心要点
- 音频感知大语言模型在训练中易发生灾难性遗忘,损失文本能力,甚至产生音频幻觉,影响模型可靠性。
- BALSa框架利用LLM合成对比式数据,增强ALLM区分音频中存在与不存在声音的能力,并扩展到多音频场景。
- 实验表明,BALSa有效缓解音频幻觉,保持音频理解和推理能力,并提升指令遵循能力。
📝 摘要(中文)
本文提出了一种名为BALSa(bootstrapping audio-language alignment via synthetic data generation from backbone LLMs)的框架,旨在解决音频感知大语言模型(ALLMs)在音频数据训练中出现的灾难性遗忘和音频幻觉问题。BALSa通过利用文本大语言模型(LLMs)合成对比式训练数据,增强ALLMs区分音频中存在和不存在声音的能力。该方法进一步扩展到多音频场景,使模型能够解释音频输入之间的差异或生成统一的描述性字幕,从而提升音频-语言对齐效果。实验结果表明,BALSa能够有效缓解音频幻觉,同时保持ALLMs在音频理解、推理和指令遵循方面的强大性能。此外,多音频训练进一步增强了模型的理解和推理能力。BALSa为开发ALLMs提供了一种高效且可扩展的方法。
🔬 方法详解
问题定义:音频感知大语言模型(ALLMs)在通过音频数据进行训练时,容易出现灾难性遗忘现象,即在音频数据上训练后,模型会丢失原有的文本能力,例如指令遵循。此外,ALLMs还可能产生音频幻觉,即模型会识别出实际上不存在于输入音频中的声音。现有方法依赖于大量的任务特定问答对进行指令微调,成本高昂。
核心思路:本文的核心思路是利用预训练的文本大语言模型(LLMs)生成合成数据,以引导ALLMs进行音频-语言对齐。通过生成对比式数据,让ALLMs能够更好地区分音频中存在和不存在的声音,从而缓解音频幻觉问题。同时,利用LLM的强大生成能力,可以低成本地生成大量高质量的训练数据。
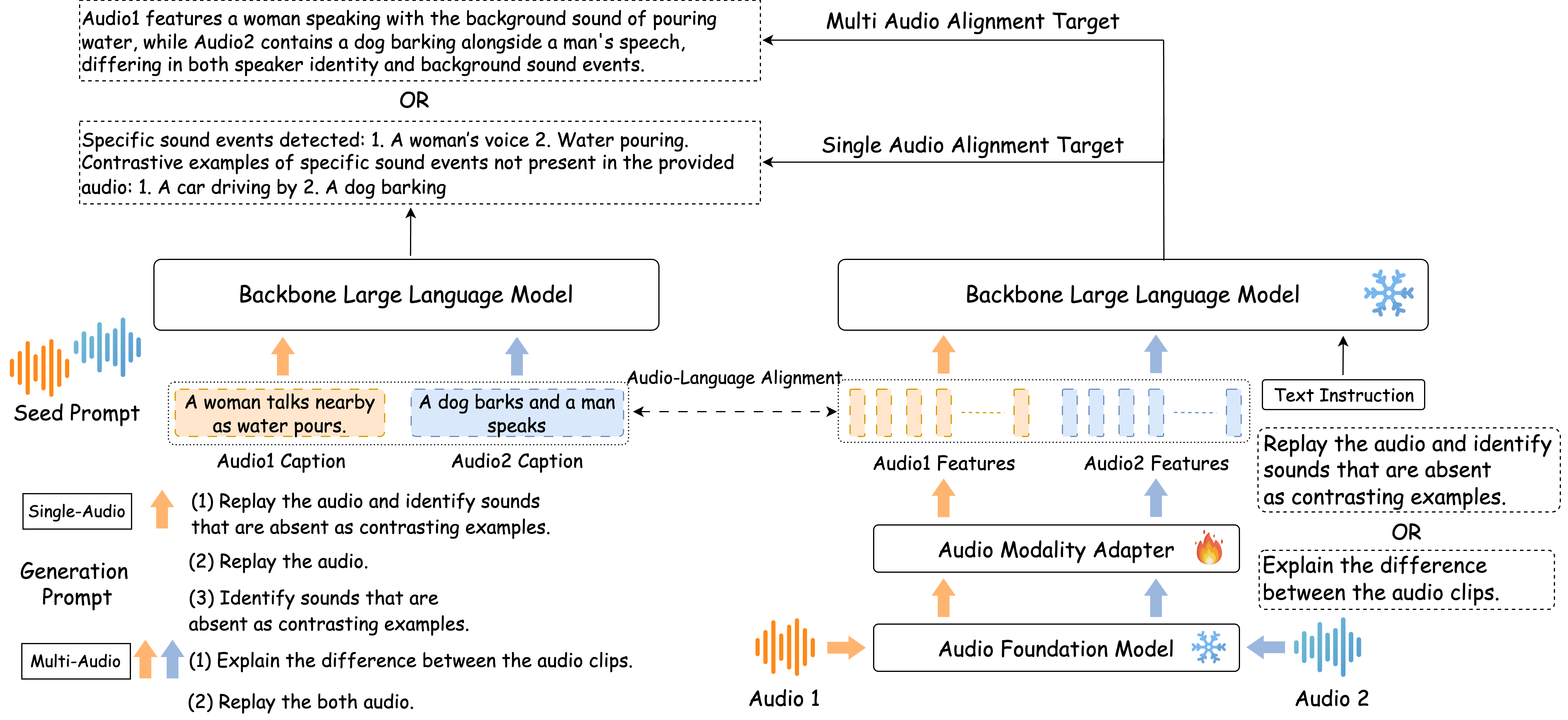
技术框架:BALSa框架主要包含以下几个阶段:1) 使用预训练的文本LLM生成音频描述文本;2) 基于生成的描述文本,构造对比式训练数据,包括正样本(音频和对应的描述)和负样本(音频和错误的描述);3) 使用生成的对比式数据训练ALLM,提升其音频-语言对齐能力和区分音频中存在与不存在声音的能力;4) 扩展到多音频场景,让模型能够解释音频输入之间的差异或生成统一的描述性字幕。
关键创新:BALSa的关键创新在于利用LLM生成对比式训练数据,从而有效地缓解了ALLMs的音频幻觉问题,并提升了其音频-语言对齐能力。与以往依赖于大量人工标注数据的做法不同,BALSa能够以较低的成本生成高质量的训练数据,具有更好的可扩展性。此外,BALSa还扩展到多音频场景,进一步提升了模型的理解和推理能力。
关键设计:在数据生成方面,采用了对比学习的思想,构造正负样本对。正样本是音频及其对应的正确描述,负样本是音频和错误的描述。错误的描述可以通过随机替换或修改正确描述中的关键词来生成。在多音频训练中,设计了两种训练目标:一种是解释不同音频之间的差异,另一种是生成统一的描述性字幕。损失函数方面,可以使用对比损失或交叉熵损失等。
🖼️ 关键图片
📊 实验亮点
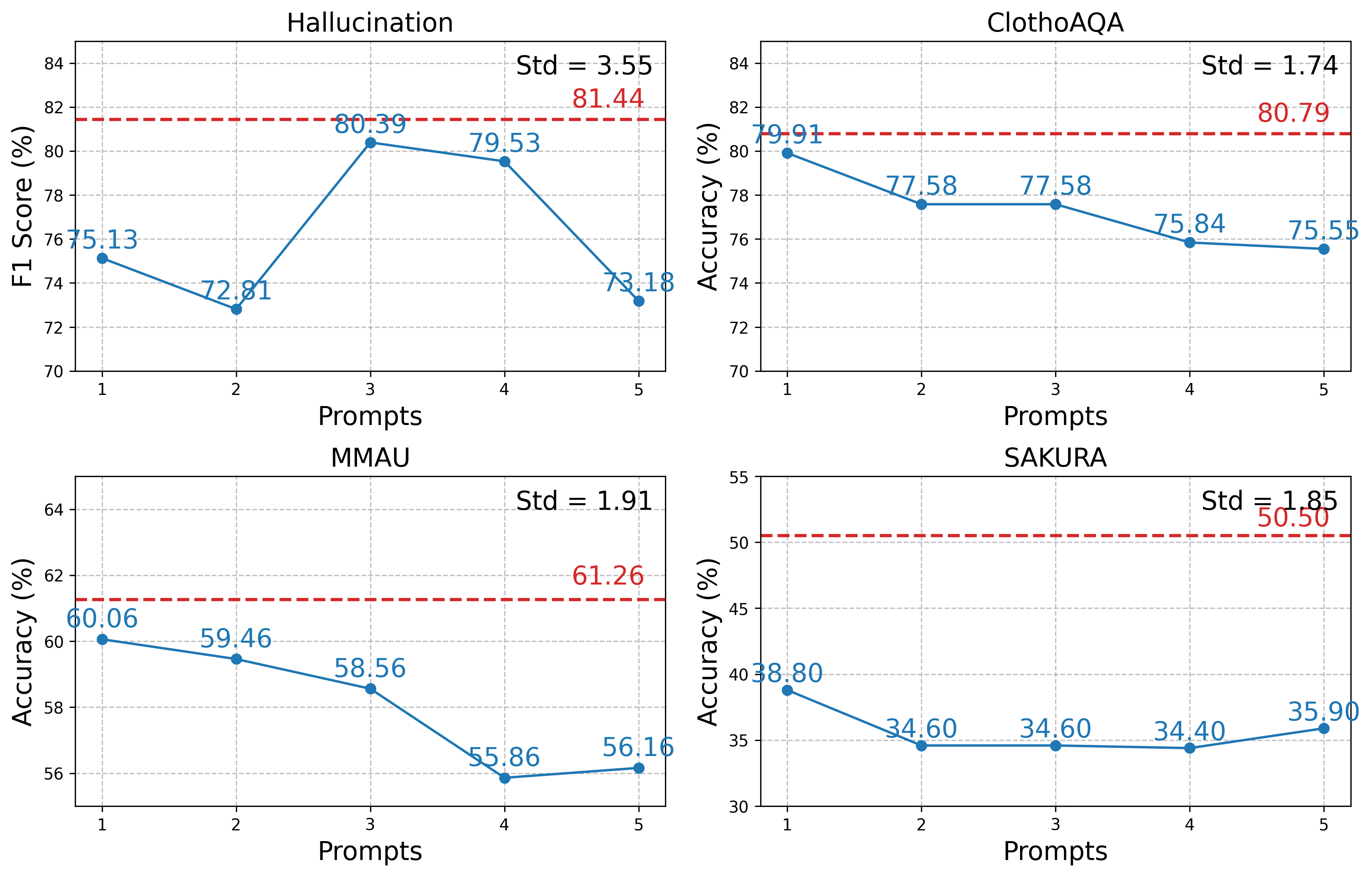
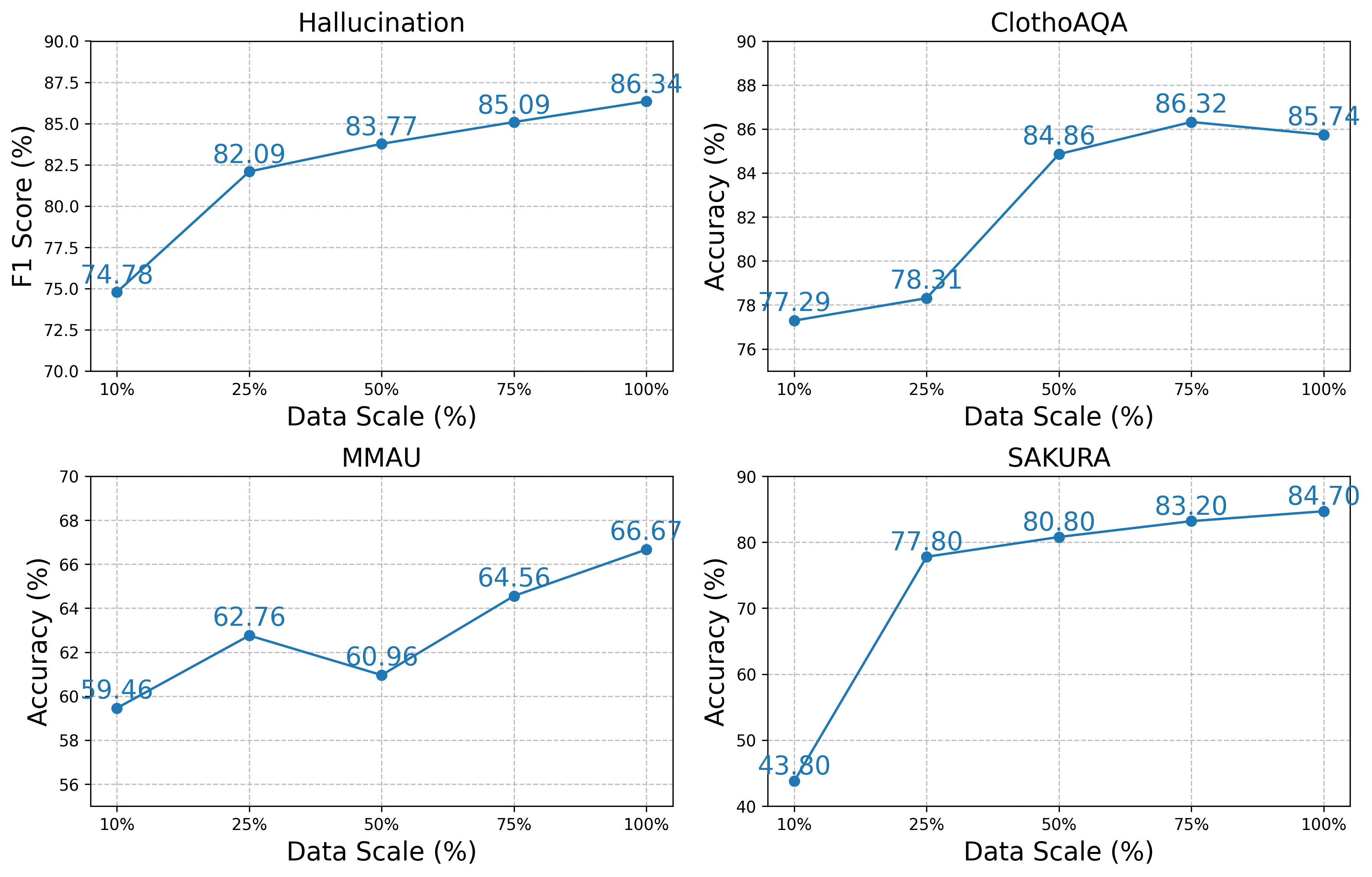
实验结果表明,BALSa能够有效缓解音频幻觉,同时保持ALLMs在音频理解、推理和指令遵循方面的强大性能。通过对比实验,证明了BALSa在多个音频理解和推理基准测试上的有效性。此外,多音频训练进一步增强了模型的理解和推理能力,在相关任务上取得了显著的性能提升。具体性能数据未知。
🎯 应用场景
该研究成果可应用于智能语音助手、音频内容分析、自动驾驶等领域。例如,可以提升语音助手对用户指令的理解能力,使其能够更准确地识别和响应用户的语音指令。在自动驾驶领域,可以帮助车辆更好地理解周围环境的声音信息,提高驾驶安全性。此外,该方法还可以用于音频内容的自动标注和分析,例如自动生成音频字幕、识别音频中的事件等。
📄 摘要(原文)
Audio-aware large language models (ALLMs) have recently made great strides in understanding and processing audio inputs. These models are typically adapted from text-based large language models (LLMs) through additional training on audio-related tasks. This adaptation process presents two major limitations. First, ALLMs often suffer from catastrophic forgetting, where crucial textual capabilities like instruction-following are lost after training on audio data. In some cases, models may even hallucinate sounds that are not present in the input audio, raising concerns about reliability. Second, achieving cross-modal alignment between audio and language typically relies on large collections of task-specific question-answer pairs for instruction tuning, making it resource-intensive. To address these issues, previous works have leveraged the backbone LLMs to synthesize general-purpose, caption-style alignment data. In this paper, we propose a data generation framework that produces contrastive-like training data, designed to enhance ALLMs' ability to differentiate between present and absent sounds. We further extend our approach to multi-audio scenarios, enabling the model to either explain differences between audio inputs or produce unified captions that describe all inputs, thereby enhancing audio-language alignment. We refer to the entire ALLM training framework as bootstrapping audio-language alignment via synthetic data generation from backbone LLMs (BALSa). Experimental results indicate that our method effectively mitigates audio hallucinations while reliably maintaining strong performance on audio understanding and reasoning benchmarks, as well as instruction-following skills. Moreover, incorporating multi-audio training further enhances the model's comprehension and reasoning capabilities. Overall, BALSa offers an efficient and scalable approach to developing ALLMs.