ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
作者: Qiushi Sun, Zhoumianze Liu, Chang Ma, Zichen Ding, Fangzhi Xu, Zhangyue Yin, Haiteng Zhao, Zhenyu Wu, Kanzhi Cheng, Zhaoyang Liu, Jianing Wang, Qintong Li, Xiangru Tang, Tianbao Xie, Xiachong Feng, Xiang Li, Ben Kao, Wenhai Wang, Biqing Qi, Lingpeng Kong, Zhiyong Wu
分类: cs.AI, cs.CL, cs.CV, cs.HC
发布日期: 2025-05-26 (更新: 2025-06-27)
备注: work in progress
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ScienceBoard:构建多模态自主Agent的科学工作流评估基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态Agent 科学工作流 自主Agent 基准测试 科学发现 LLM 计算机视觉
📋 核心要点
- 现有基于LLM的Agent在科学发现领域潜力巨大,但缺乏在真实、复杂科学工作流中的有效评估。
- ScienceBoard提出一个多领域、动态且视觉丰富的科学环境,集成专业软件,Agent可自主交互。
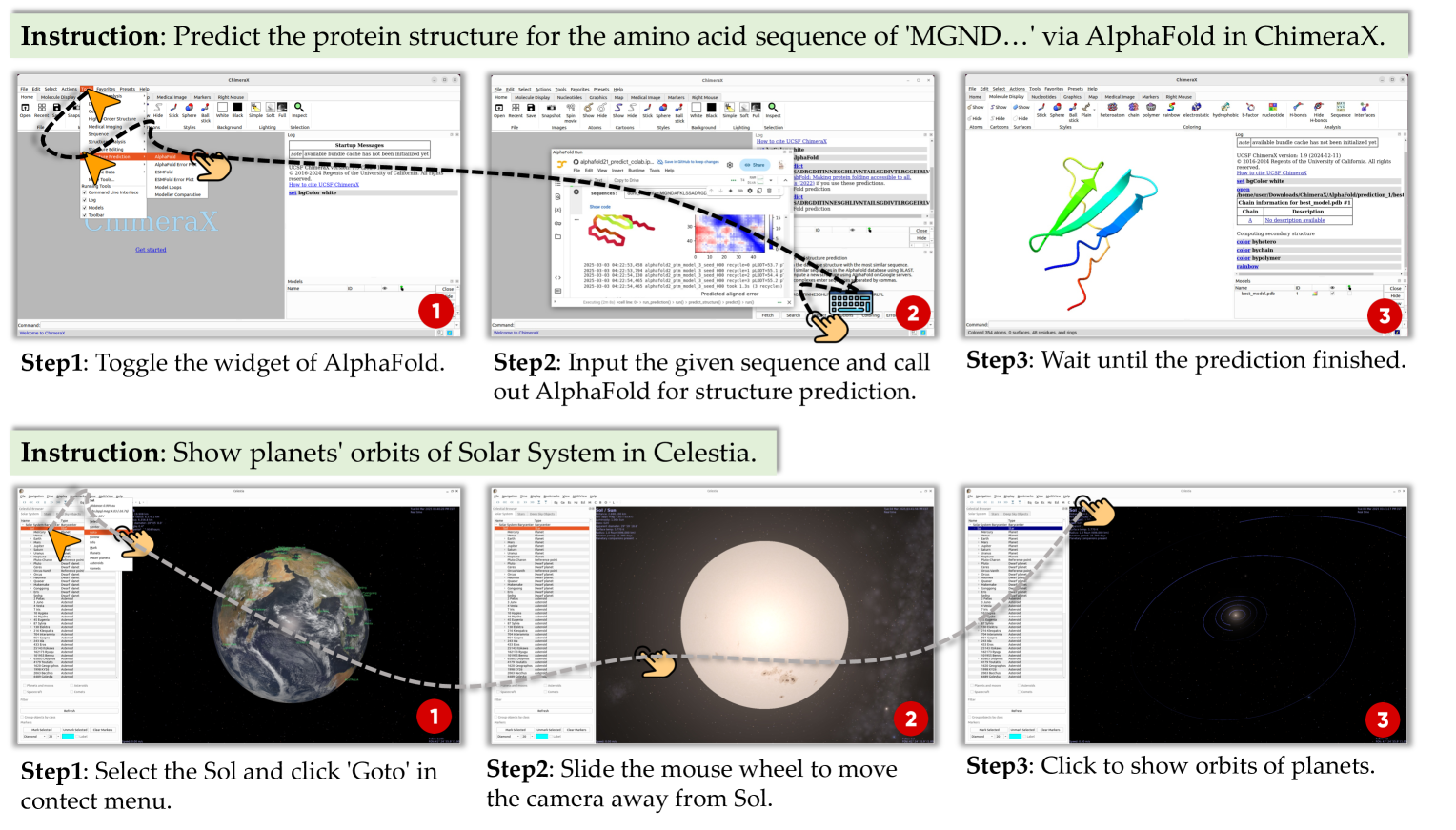
- 构建包含169个真实世界任务的基准,涵盖生物化学、天文学等领域,评估Agent在复杂工作流中的表现。
📝 摘要(中文)
大型语言模型(LLMs)的影响已扩展到自然语言处理之外,极大地促进了跨学科研究的发展。最近,各种基于LLM的Agent被开发出来,以协助跨多个方面和领域的科学发现。其中,能够像人类一样与操作系统交互的计算机使用Agent,正在为自动化科学问题解决和研究人员工作流程中的日常任务铺平道路。认识到这些Agent的变革潜力,我们引入了ScienceBoard,它包含两个互补的贡献:(i)一个现实的、多领域的环境,具有动态和视觉丰富的科学工作流程,集成了专业的软件,Agent可以通过不同的界面自主交互,以加速复杂的研究任务和实验;(ii)一个具有挑战性的基准,包含169个高质量、经过严格验证的真实世界任务,由人类策划,涵盖生物化学、天文学和地球信息学等领域的科学发现工作流程。对具有最先进骨干网络(例如,GPT-4o、Claude 3.7、UI-TARS)的Agent进行的大量评估表明,尽管取得了一些有希望的结果,但它们仍然无法可靠地协助科学家完成复杂的工作流程,总体成功率仅为15%。深入分析进一步为解决当前Agent的局限性和更有效的设计原则提供了宝贵的见解,为构建更强大的科学发现Agent铺平了道路。我们的代码、环境和基准位于https://qiushisun.github.io/ScienceBoard-Home/。
🔬 方法详解
问题定义:现有基于LLM的Agent在科学发现领域展现出潜力,但缺乏在模拟真实科研环境下的有效评估。现有方法难以模拟科研工作流的复杂性,例如需要操作专业软件、处理多模态信息等,导致Agent在实际科研任务中的表现远低于预期。
核心思路:ScienceBoard的核心思路是构建一个更贴近真实科研场景的评估环境和基准。通过集成专业软件、模拟动态工作流和提供多模态输入,ScienceBoard能够更全面地评估Agent在解决复杂科研问题时的能力。这样设计的目的是为了弥合现有评估方法与实际科研需求之间的差距,从而推动更实用的科研Agent的开发。
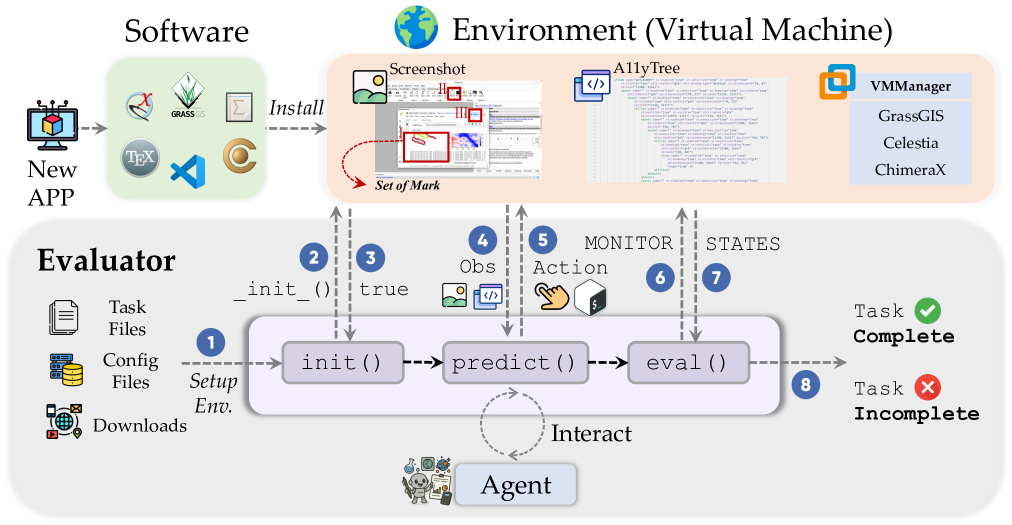
技术框架:ScienceBoard包含两个主要组成部分:一是多领域环境,二是基准数据集。多领域环境模拟了真实的科研工作流程,集成了专业的科学软件,并支持Agent通过不同的界面进行交互。基准数据集包含169个高质量的真实世界任务,涵盖生物化学、天文学和地球信息学等领域。Agent需要在该环境中自主完成这些任务,并根据其完成情况进行评估。
关键创新:ScienceBoard的关键创新在于其真实性和复杂性。与以往的评估环境相比,ScienceBoard更贴近真实的科研场景,能够更全面地评估Agent在解决复杂科研问题时的能力。此外,ScienceBoard还提供了一个统一的评估平台,方便研究人员进行Agent的开发和评估。
关键设计:ScienceBoard环境的关键设计包括:(1) 集成多种专业科学软件,模拟真实科研工具的使用;(2) 设计动态的工作流程,模拟科研任务的复杂性和不确定性;(3) 提供多模态输入,包括文本、图像和表格等,模拟科研数据的多样性;(4) 任务设计由领域专家人工构建和验证,保证任务的质量和难度。
🖼️ 关键图片
📊 实验亮点
在ScienceBoard基准测试中,即使是最先进的Agent(如GPT-4o、Claude 3.7和UI-TARS)的总体成功率也仅为15%。这表明现有Agent在复杂科学工作流程中仍存在显著局限性,突出了ScienceBoard作为评估和改进科研Agent的重要价值。该结果为未来的Agent设计提供了宝贵的见解。
🎯 应用场景
ScienceBoard可用于评估和提升AI Agent在科学研究中的自主能力,例如自动化实验设计、数据分析和文献检索。它能加速科研进程,降低科研成本,并可能促进新的科学发现。未来,ScienceBoard有望成为科研人员的重要助手,甚至能够独立完成部分科研任务。
📄 摘要(原文)
Large Language Models (LLMs) have extended their impact beyond Natural Language Processing, substantially fostering the development of interdisciplinary research. Recently, various LLM-based agents have been developed to assist scientific discovery progress across multiple aspects and domains. Among these, computer-using agents, capable of interacting with operating systems as humans do, are paving the way to automated scientific problem-solving and addressing routines in researchers' workflows. Recognizing the transformative potential of these agents, we introduce ScienceBoard, which encompasses two complementary contributions: (i) a realistic, multi-domain environment featuring dynamic and visually rich scientific workflows with integrated professional software, where agents can autonomously interact via different interfaces to accelerate complex research tasks and experiments; and (ii) a challenging benchmark of 169 high-quality, rigorously validated real-world tasks curated by humans, spanning scientific-discovery workflows in domains such as biochemistry, astronomy, and geoinformatics. Extensive evaluations of agents with state-of-the-art backbones (e.g., GPT-4o, Claude 3.7, UI-TARS) show that, despite some promising results, they still fall short of reliably assisting scientists in complex workflows, achieving only a 15% overall success rate. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents for scientific discovery. Our code, environment, and benchmark are at https://qiushisun.github.io/ScienceBoard-Home/.