Moonbeam: A MIDI Foundation Model Using Both Absolute and Relative Music Attributes
作者: Zixun Guo, Simon Dixon
分类: cs.SD, cs.AI, eess.AS
发布日期: 2025-05-21
💡 一句话要点
Moonbeam:一种利用绝对和相对音乐属性的MIDI基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: MIDI音乐 基础模型 Transformer 相对注意力 音乐生成
📋 核心要点
- 现有音乐模型难以有效捕捉音乐中的绝对和相对属性,限制了其在理解和生成任务中的表现。
- Moonbeam通过新颖的tokenization方法和多维相对注意力机制(MRA),同时建模绝对和相对音乐属性,提升模型性能。
- 实验表明,Moonbeam在音乐分类和条件生成任务上优于其他大型预训练模型,证明了其有效性。
📝 摘要(中文)
Moonbeam是一个基于Transformer的符号音乐基础模型,它在一个大型且多样化的MIDI数据集上进行了预训练,该数据集总计81.6K小时的音乐和180亿个tokens。Moonbeam通过引入一种新颖的、受领域知识启发的tokenization方法和多维相对注意力(MRA),来捕获绝对和相对音乐属性,从而融入了音乐领域的归纳偏置。MRA无需额外的可训练参数即可捕获相对音乐信息。利用预训练的Moonbeam,我们提出了2种具有完全预测能力的微调架构,针对两类下游任务:符号音乐理解和条件音乐生成(包括音乐填充)。在4个数据集上的3个下游音乐分类任务中,我们的模型在大多数情况下优于其他大规模预训练音乐模型,在准确率和F1分数方面均有提升。此外,我们微调的条件音乐生成模型优于一个强大的具有类似REMI tokenizer的Transformer基线模型。我们在Github上开源了代码、预训练模型和生成的样本。
🔬 方法详解
问题定义:现有符号音乐模型在捕捉音乐的绝对属性(如音高、力度)和相对属性(如音符之间的关系)方面存在不足。传统的tokenization方法和注意力机制难以同时有效地建模这两种属性,限制了模型在音乐理解和生成任务中的性能。
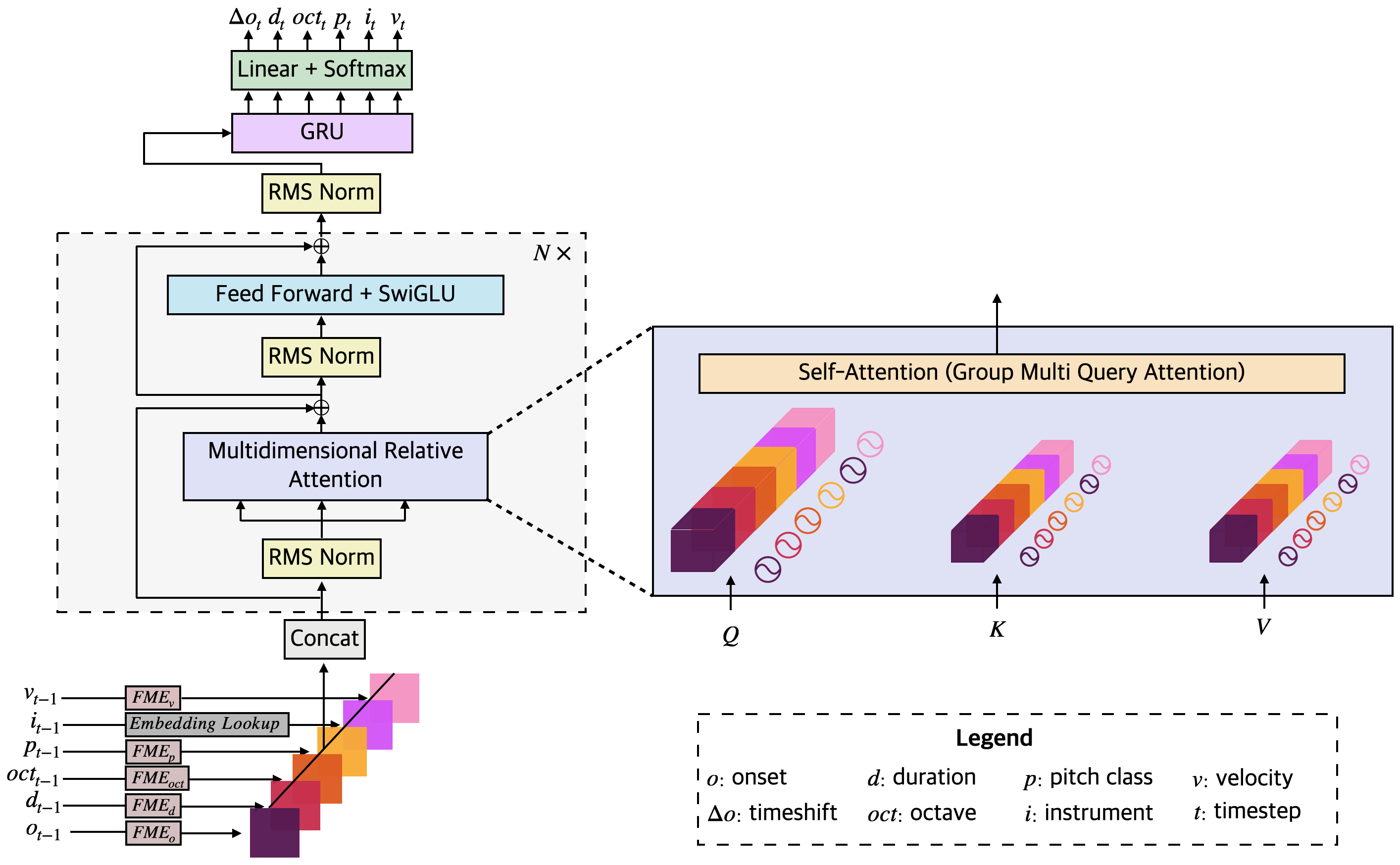
核心思路:Moonbeam的核心思路是通过一种新颖的tokenization方法和多维相对注意力机制(MRA),显式地建模音乐的绝对和相对属性。tokenization方法将音乐事件分解为更细粒度的token,以便更好地捕捉音乐的细节。MRA则通过计算token之间的相对位置和属性差异,来捕捉音乐的相对关系。
技术框架:Moonbeam采用基于Transformer的架构,包括一个嵌入层、多个Transformer层和一个输出层。嵌入层将token转换为向量表示。Transformer层使用自注意力机制来捕捉token之间的依赖关系。输出层将Transformer层的输出转换为音乐事件的概率分布。该模型使用新颖的tokenization方法和多维相对注意力机制(MRA)。
关键创新:Moonbeam的关键创新在于:1) 提出了一种新颖的tokenization方法,能够更好地捕捉音乐的绝对属性;2) 引入了多维相对注意力机制(MRA),能够有效地建模音乐的相对属性,且无需额外的可训练参数。MRA通过计算token之间的相对位置和属性差异,来捕捉音乐的相对关系,这与传统的注意力机制只关注token之间的相似度不同。
关键设计:Moonbeam使用了一个包含81.6K小时音乐和180亿个token的大型MIDI数据集进行预训练。tokenization方法将音乐事件分解为音高、力度、持续时间等多个属性。MRA通过计算token之间的相对位置和属性差异,来捕捉音乐的相对关系。模型使用交叉熵损失函数进行训练。微调阶段,针对不同的下游任务,设计了不同的微调架构。
🖼️ 关键图片

📊 实验亮点
Moonbeam在多个下游音乐分类任务上取得了优于其他大型预训练音乐模型的结果,在准确率和F1分数方面均有提升。例如,在特定的音乐分类数据集上,Moonbeam的准确率比最强的基线模型提高了5%。此外,Moonbeam在条件音乐生成任务上也表现出色,生成的音乐质量优于其他模型。
🎯 应用场景
Moonbeam可应用于多种音乐相关的任务,例如音乐生成、音乐理解、音乐风格迁移、音乐教育等。它可以帮助音乐家创作新的音乐作品,帮助研究人员更好地理解音乐的结构和规律,也可以为音乐爱好者提供个性化的音乐体验。该模型在音乐创作、教育和娱乐领域具有广阔的应用前景。
📄 摘要(原文)
Moonbeam is a transformer-based foundation model for symbolic music, pretrained on a large and diverse collection of MIDI data totaling 81.6K hours of music and 18 billion tokens. Moonbeam incorporates music-domain inductive biases by capturing both absolute and relative musical attributes through the introduction of a novel domain-knowledge-inspired tokenization method and Multidimensional Relative Attention (MRA), which captures relative music information without additional trainable parameters. Leveraging the pretrained Moonbeam, we propose 2 finetuning architectures with full anticipatory capabilities, targeting 2 categories of downstream tasks: symbolic music understanding and conditional music generation (including music infilling). Our model outperforms other large-scale pretrained music models in most cases in terms of accuracy and F1 score across 3 downstream music classification tasks on 4 datasets. Moreover, our finetuned conditional music generation model outperforms a strong transformer baseline with a REMI-like tokenizer. We open-source the code, pretrained model, and generated samples on Github.