Prosody-Adaptable Audio Codecs for Zero-Shot Voice Conversion via In-Context Learning
作者: Junchuan Zhao, Xintong Wang, Ye Wang
分类: cs.SD, cs.AI, eess.AS
发布日期: 2025-05-21
备注: 5 pages, 3 figures
💡 一句话要点
提出基于上下文学习和韵律自适应音频编解码器的零样本语音转换模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 语音转换 零样本学习 上下文学习 音频编解码器 韵律控制
📋 核心要点
- 现有的语音转换方法在韵律控制方面存在不足,难以灵活地调整语音的表达方式。
- 论文提出PACE模块,通过解耦韵律信息,增强模型对韵律的控制能力,提升语音转换的灵活性。
- 实验结果表明,该方法在韵律保持、音色一致性和自然度方面均优于基线系统,效果显著。
📝 摘要(中文)
本文提出了一种基于VALLE-X框架的语音转换(VC)模型,该模型利用其强大的上下文学习能力进行说话人自适应。为了增强韵律控制,我们引入了一个韵律感知音频编解码器编码器(PACE)模块,该模块从其他来源中隔离和细化韵律,从而提高表现力和控制力。通过将PACE集成到我们的VC模型中,我们在保持说话人音色的同时,实现了更大的韵律操作灵活性。实验评估结果表明,我们的方法在韵律保持、音色一致性和整体自然度方面优于基线VC系统。
🔬 方法详解
问题定义:语音转换(VC)旨在改变源语音的说话人身份,使其听起来像目标说话人。现有的语音转换方法在韵律控制方面存在局限性,难以在保持说话人音色的同时,灵活地调整语音的韵律,例如语速、语调和节奏。这限制了语音转换的应用场景和用户体验。
核心思路:本文的核心思路是利用上下文学习能力和解耦韵律信息来提升语音转换的性能。通过VALLE-X框架的上下文学习能力,模型可以更好地适应目标说话人的音色。同时,引入PACE模块来提取和控制韵律信息,从而实现更灵活的韵律调整。
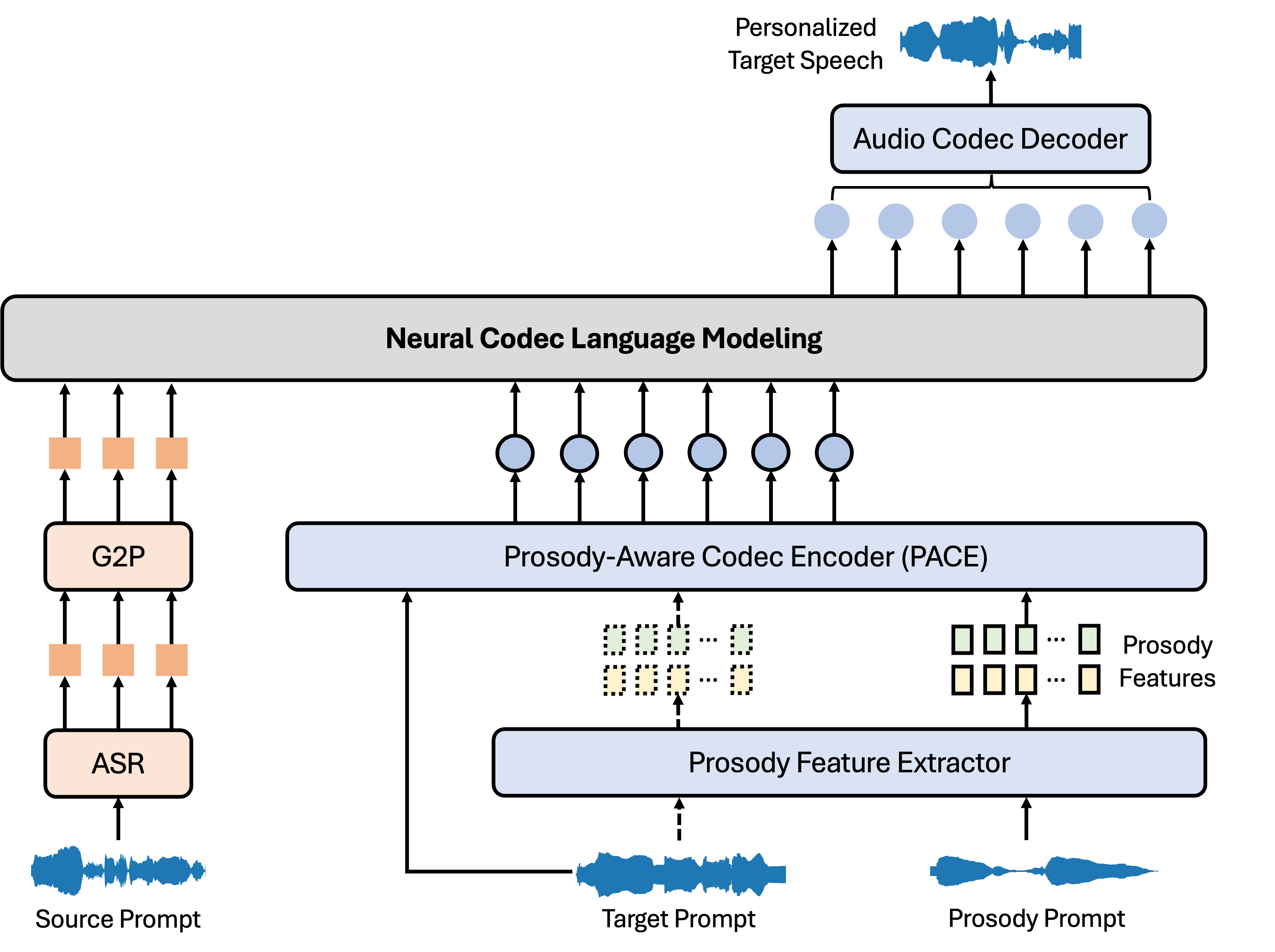
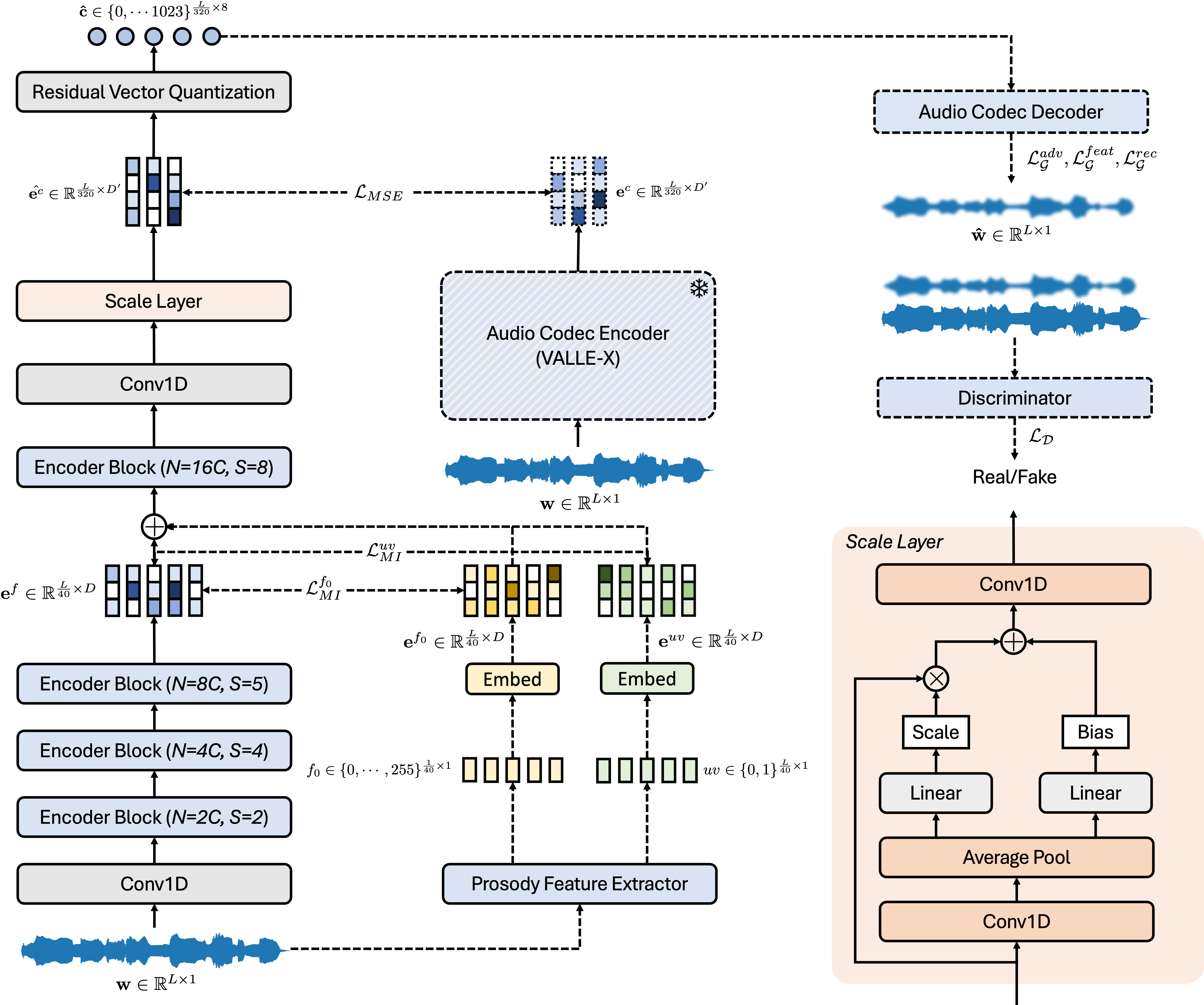
技术框架:该语音转换模型基于VALLE-X框架,主要包含以下模块:1) 音频编解码器:将语音信号转换为离散的token序列。2) PACE模块:从token序列中提取和细化韵律信息。3) 上下文学习模块:利用目标说话人的少量语音样本,学习其音色特征。4) 解码器:根据韵律信息和音色特征,生成目标语音。整体流程是:首先,使用音频编解码器将源语音转换为token序列;然后,使用PACE模块提取韵律信息;接着,利用上下文学习模块学习目标说话人的音色特征;最后,使用解码器生成具有目标说话人音色和期望韵律的语音。
关键创新:该论文的关键创新在于PACE模块的设计。PACE模块能够有效地从语音信号中解耦韵律信息,并允许模型独立地控制韵律,从而实现更灵活的语音转换。与传统的语音转换方法相比,该方法能够更好地保持说话人音色,并生成更自然、更具表现力的语音。
关键设计:PACE模块的具体实现细节未知,但可以推测其可能采用注意力机制或对抗训练等技术,以实现韵律信息的有效提取和解耦。损失函数的设计可能包括韵律损失、音色损失和对抗损失等,以保证生成语音的韵律准确、音色一致和自然度高。
🖼️ 关键图片
📊 实验亮点
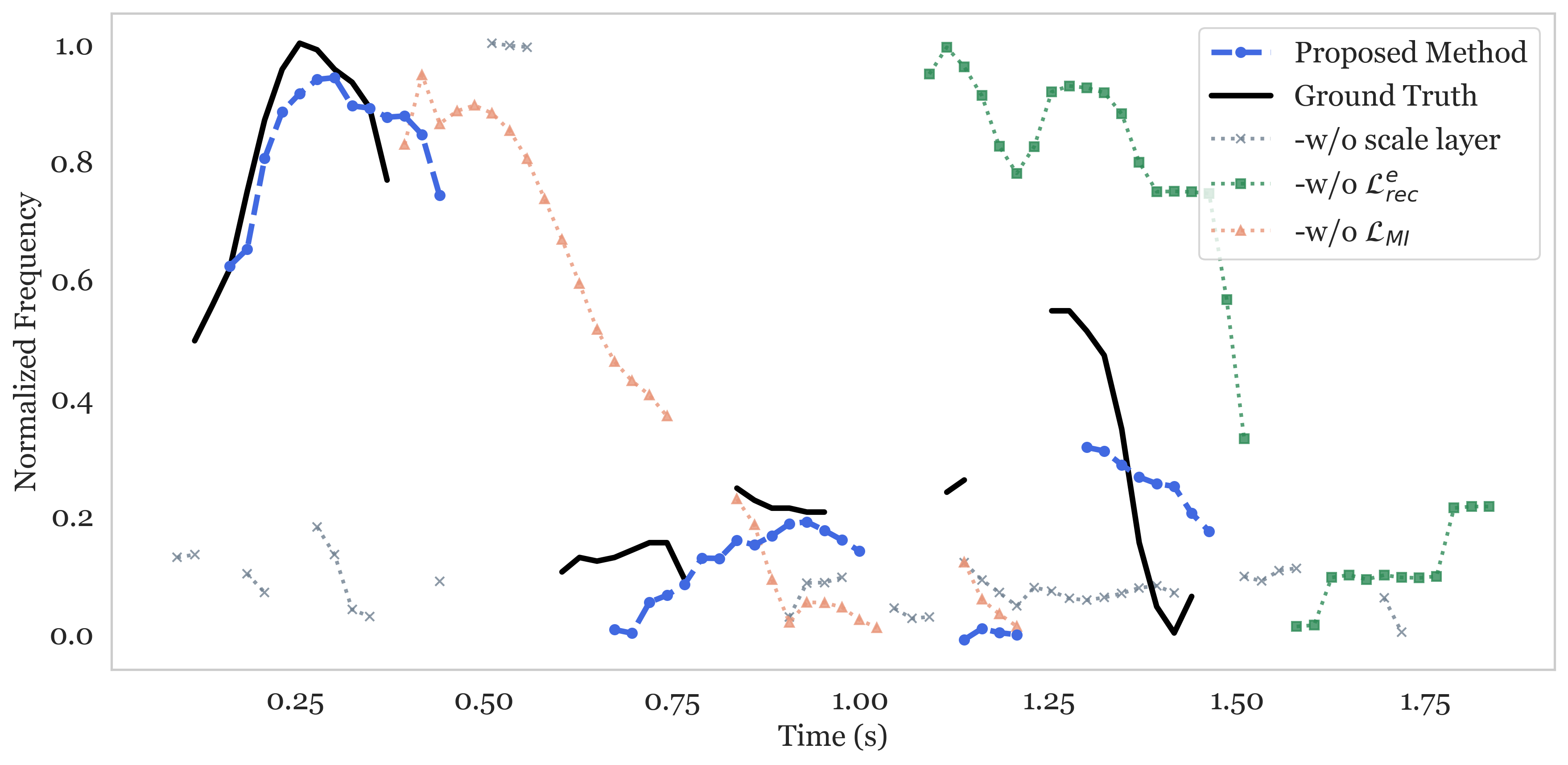
实验结果表明,该方法在韵律保持、音色一致性和整体自然度方面均优于基线VC系统。具体性能数据未知,但摘要中明确指出该方法超越了基线系统,表明其在语音转换任务中具有显著的优势。
🎯 应用场景
该研究成果可应用于语音合成、语音编辑、个性化语音助手等领域。例如,用户可以通过该技术将自己的声音转换为其他人的声音,或者调整语音的语速、语调等韵律特征,从而实现更个性化的语音交互体验。此外,该技术还可以用于语音修复,例如恢复因疾病或损伤而受损的语音。
📄 摘要(原文)
Recent advances in discrete audio codecs have significantly improved speech representation modeling, while codec language models have enabled in-context learning for zero-shot speech synthesis. Inspired by this, we propose a voice conversion (VC) model within the VALLE-X framework, leveraging its strong in-context learning capabilities for speaker adaptation. To enhance prosody control, we introduce a prosody-aware audio codec encoder (PACE) module, which isolates and refines prosody from other sources, improving expressiveness and control. By integrating PACE into our VC model, we achieve greater flexibility in prosody manipulation while preserving speaker timbre. Experimental evaluation results demonstrate that our approach outperforms baseline VC systems in prosody preservation, timbre consistency, and overall naturalness, surpassing baseline VC systems.