HAVA: Hybrid Approach to Value-Alignment through Reward Weighing for Reinforcement Learning
作者: Kryspin Varys, Federico Cerutti, Adam Sobey, Timothy J. Norman
分类: cs.AI
发布日期: 2025-05-21
💡 一句话要点
HAVA:通过奖励加权混合方法实现强化学习中的价值对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 价值对齐 强化学习 奖励加权 规范学习 混合方法
📋 核心要点
- 现有强化学习方法难以有效整合显式(如法律)和隐式(如社会规范)的多种价值规范表示。
- 提出HAVA方法,通过监控智能体的规范遵守情况并以“声誉”值加权奖励,激励价值对齐。
- 实验表明,HAVA方法在交通问题中能有效结合成文和未成文规范,优于单独使用任一规范。
📝 摘要(中文)
我们的社会由一系列规范所约束,这些规范共同构成了我们珍视的价值观,如安全、公平和可信赖。价值对齐的目标是创建不仅能完成任务,而且通过其行为也能促进这些价值观的智能体。许多规范被写成法律或规则(法律/安全规范),但更多规范仍然是未成文的(社会规范)。此外,用于表示这些规范的技术也各不相同。安全/法律规范通常被显式地表示,例如,在某种逻辑语言中,而社会规范通常是被学习的,并隐藏在神经网络的参数空间中。文献中缺乏能够将这些不同的规范表示形式组合成单一算法的方法。我们提出了一种新颖的方法,将这些规范整合到强化学习过程中。我们的方法监控智能体对给定规范的遵守情况,并将其总结为一个称为智能体声誉的量。该量用于权衡收到的奖励,以激励智能体实现价值对齐。我们进行了一系列实验,包括一个连续状态空间的交通问题,以证明成文和未成文规范的重要性,并展示我们的方法如何找到价值对齐的策略。此外,我们进行了消融实验,以证明将这两组规范结合起来比单独使用其中任何一组更好。
🔬 方法详解
问题定义:论文旨在解决强化学习智能体如何同时考虑显式规则(例如法律法规)和隐式社会规范,从而实现价值对齐的问题。现有方法通常只能处理其中一种规范,或者难以将两者有效结合,导致智能体的行为可能不符合整体社会价值观。
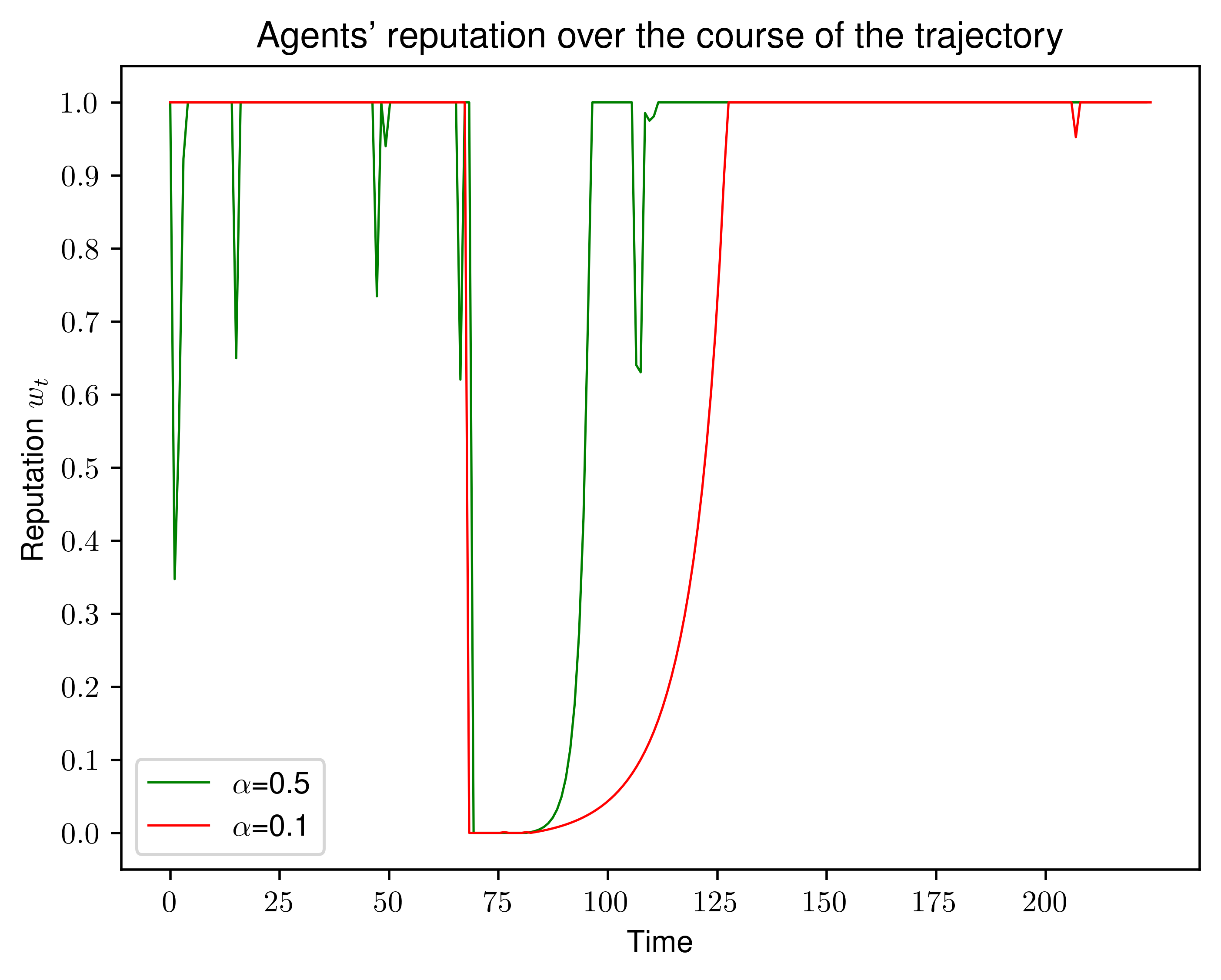
核心思路:论文的核心思路是通过引入“声誉”的概念,量化智能体对各种规范的遵守程度。然后,利用这个声誉值来加权智能体从环境中获得的奖励。如果智能体违反了规范,其声誉会下降,从而降低其获得的奖励,促使其学习符合价值规范的行为。
技术框架:HAVA方法的技术框架主要包含以下几个模块:1) 规范监控模块:负责监控智能体在环境中的行为,并判断其是否违反了预定义的显式或隐式规范。2) 声誉计算模块:根据规范监控模块的输出,计算智能体的声誉值。声誉值越高,表示智能体越符合规范。3) 奖励加权模块:使用声誉值来加权智能体从环境中获得的原始奖励。声誉越高,奖励的权重越大。4) 强化学习智能体:使用加权后的奖励进行学习,从而调整其行为策略,使其更符合价值规范。
关键创新:HAVA方法的关键创新在于它能够将显式和隐式规范统一到一个框架中,并通过声誉机制将它们的影响融入到强化学习的过程中。与现有方法相比,HAVA方法能够更全面地考虑各种价值规范,从而训练出更符合社会价值观的智能体。
关键设计:规范监控模块需要针对不同的规范类型进行设计。对于显式规范,可以使用逻辑规则或约束来判断智能体的行为是否符合规范。对于隐式规范,可以使用机器学习模型(例如神经网络)来学习规范的表示,并判断智能体的行为是否符合规范。声誉值的计算可以采用多种方式,例如,可以根据违反规范的严重程度和频率来调整声誉值。奖励加权函数的设计也很重要,需要确保智能体既能完成任务,又能遵守规范。
🖼️ 关键图片


📊 实验亮点
实验结果表明,HAVA方法在交通问题中能够有效地结合成文和未成文规范,找到价值对齐的策略。与单独使用成文或未成文规范相比,HAVA方法能够获得更好的性能。消融实验进一步验证了将两种规范结合起来的优势。
🎯 应用场景
HAVA方法具有广泛的应用前景,例如自动驾驶、机器人助手、金融交易等领域。在自动驾驶中,HAVA可以帮助车辆遵守交通规则和道德规范,从而提高安全性。在机器人助手中,HAVA可以帮助机器人理解和遵守社会规范,从而更好地与人类互动。在金融交易中,HAVA可以帮助交易员遵守法律法规和伦理准则,从而降低风险。
📄 摘要(原文)
Our society is governed by a set of norms which together bring about the values we cherish such as safety, fairness or trustworthiness. The goal of value-alignment is to create agents that not only do their tasks but through their behaviours also promote these values. Many of the norms are written as laws or rules (legal / safety norms) but even more remain unwritten (social norms). Furthermore, the techniques used to represent these norms also differ. Safety / legal norms are often represented explicitly, for example, in some logical language while social norms are typically learned and remain hidden in the parameter space of a neural network. There is a lack of approaches in the literature that could combine these various norm representations into a single algorithm. We propose a novel method that integrates these norms into the reinforcement learning process. Our method monitors the agent's compliance with the given norms and summarizes it in a quantity we call the agent's reputation. This quantity is used to weigh the received rewards to motivate the agent to become value-aligned. We carry out a series of experiments including a continuous state space traffic problem to demonstrate the importance of the written and unwritten norms and show how our method can find the value-aligned policies. Furthermore, we carry out ablations to demonstrate why it is better to combine these two groups of norms rather than using either separately.