Self-Evolving Curriculum for LLM Reasoning
作者: Xiaoyin Chen, Jiarui Lu, Minsu Kim, Dinghuai Zhang, Jian Tang, Alexandre Piché, Nicolas Gontier, Yoshua Bengio, Ehsan Kamalloo
分类: cs.AI, cs.LG
发布日期: 2025-05-20 (更新: 2025-10-30)
💡 一句话要点
提出自适应课程学习(SEC)方法,提升LLM在推理任务中强化学习微调的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自适应课程学习 强化学习 大型语言模型 推理能力 多臂老虎机
📋 核心要点
- 强化学习微调LLM面临课程选择难题,随机课程效果差,人工设计依赖启发式,在线过滤计算成本高。
- SEC将课程选择建模为多臂老虎机问题,利用策略梯度绝对优势作为奖励,自动学习课程策略。
- 实验表明,SEC在规划、归纳推理和数学等领域显著提升LLM推理能力,并提高泛化性和技能平衡。
📝 摘要(中文)
本文提出了一种名为自适应课程学习(SEC)的自动课程学习方法,用于强化学习(RL)微调大型语言模型(LLM),以增强其在数学和代码生成等领域的推理能力。SEC将课程选择建模为一个非平稳多臂老虎机问题,将每个问题类别(例如,难度级别或问题类型)视为一个单独的臂。该方法利用策略梯度方法的绝对优势作为即时学习收益的代理指标。在每个训练步骤中,课程策略选择类别以最大化此奖励信号,并使用TD(0)方法进行更新。在规划、归纳推理和数学三个不同的推理领域中,实验表明SEC显著提高了模型的推理能力,使其能够更好地泛化到更困难的、分布外的测试问题。此外,该方法在同时对多个推理领域进行微调时,实现了更好的技能平衡。这些发现表明,SEC是LLM的RL微调的一种有前途的策略。
🔬 方法详解
问题定义:现有强化学习微调LLM的方法在课程选择上存在不足。随机课程策略效果不佳,无法有效引导模型学习;人工设计的课程策略通常依赖于领域知识和启发式方法,缺乏通用性;在线过滤方法虽然可以动态调整课程,但计算成本过高,难以应用于大规模LLM的训练。因此,如何自动、高效地设计课程策略,提升LLM的推理能力是一个关键问题。
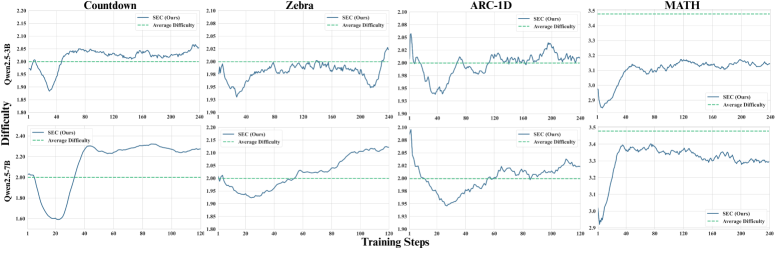
核心思路:本文的核心思路是将课程选择问题建模为一个非平稳多臂老虎机(MAB)问题。每个“臂”代表一个问题类别(例如,不同难度级别或不同类型的数学题)。通过学习一个策略来选择每次训练迭代中使用的“臂”,从而优化训练过程。选择“臂”的依据是最大化即时学习收益,即选择那些能够使模型获得最大提升的问题类别。
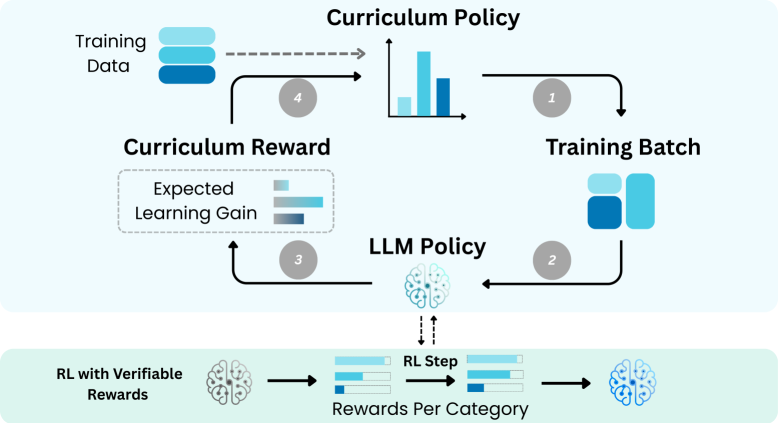
技术框架:SEC的整体框架包含以下几个主要模块:1) LLM:待微调的大型语言模型。2) 环境:提供不同类别的问题,用于训练LLM。3) 课程策略:一个策略网络,用于选择下一个要训练的问题类别。4) 奖励函数:基于策略梯度方法的绝对优势,衡量LLM在特定问题类别上的学习收益。5) 训练循环:在每个训练步骤中,课程策略选择一个问题类别,LLM在该类别上进行训练,计算奖励,并使用TD(0)方法更新课程策略。
关键创新:SEC的关键创新在于将课程学习问题建模为非平稳MAB问题,并使用策略梯度方法的绝对优势作为奖励信号。这种方法无需人工设计课程,也避免了在线过滤的高计算成本。通过自动学习课程策略,SEC能够更有效地引导LLM的学习过程,提升其推理能力。与现有方法相比,SEC更加通用、高效,并且能够更好地适应不同的推理领域。
关键设计:在SEC中,课程策略可以使用任何能够处理离散动作空间的强化学习算法实现。本文使用TD(0)方法更新课程策略。奖励函数的设计至关重要,本文使用策略梯度方法的绝对优势作为奖励,具体计算方式为:A(s, a) = Q(s, a) - V(s),其中A(s, a)表示在状态s下选择动作a的优势,Q(s, a)表示在状态s下选择动作a的期望回报,V(s)表示在状态s下的期望回报。通过最大化绝对优势,SEC能够选择那些能够使模型获得最大提升的问题类别。
🖼️ 关键图片
📊 实验亮点
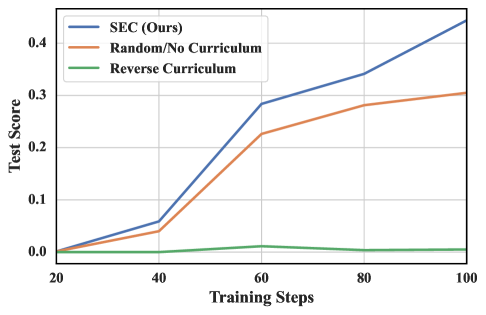
实验结果表明,SEC在规划、归纳推理和数学三个领域均显著优于随机课程和人工设计的课程。例如,在数学领域,SEC使模型在更困难的、分布外的测试问题上取得了显著的性能提升。此外,SEC在同时对多个推理领域进行微调时,实现了更好的技能平衡,表明其具有良好的通用性和适应性。
🎯 应用场景
SEC方法可广泛应用于各种需要强化学习微调LLM的场景,例如数学问题求解、代码生成、规划任务等。该方法能够提升LLM在特定领域的推理能力,并提高其泛化性和鲁棒性。此外,SEC还可以用于多任务学习,平衡不同任务之间的学习进度,提高整体性能。未来,SEC有望成为LLM强化学习微调的标准方法之一。
📄 摘要(原文)
Reinforcement learning (RL) has proven effective for fine-tuning large language models (LLMs), significantly enhancing their reasoning abilities in domains such as mathematics and code generation. A crucial factor influencing RL fine-tuning success is the training curriculum: the order in which training problems are presented. While random curricula serve as common baselines, they remain suboptimal; manually designed curricula often rely heavily on heuristics, and online filtering methods can be computationally prohibitive. To address these limitations, we propose Self-Evolving Curriculum (SEC), an automatic curriculum learning method that learns a curriculum policy concurrently with the RL fine-tuning process. Our approach formulates curriculum selection as a non-stationary Multi-Armed Bandit problem, treating each problem category (e.g., difficulty level or problem type) as an individual arm. We leverage the absolute advantage from policy gradient methods as a proxy measure for immediate learning gain. At each training step, the curriculum policy selects categories to maximize this reward signal and is updated using the TD(0) method. Across three distinct reasoning domains: planning, inductive reasoning, and mathematics, our experiments demonstrate that SEC significantly improves models' reasoning capabilities, enabling better generalization to harder, out-of-distribution test problems. Additionally, our approach achieves better skill balance when fine-tuning simultaneously on multiple reasoning domains. These findings highlight SEC as a promising strategy for RL fine-tuning of LLMs.