Balanced and Elastic End-to-end Training of Dynamic LLMs
作者: Mohamed Wahib, Muhammed Abdullah Soyturk, Didem Unat
分类: cs.DC, cs.AI
发布日期: 2025-05-20 (更新: 2025-09-14)
💡 一句话要点
提出DynMo,实现动态LLM训练的负载均衡与弹性伸缩,提升训练效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动态LLM 负载均衡 分布式训练 弹性伸缩 模型剪枝 混合专家模型 早退出
📋 核心要点
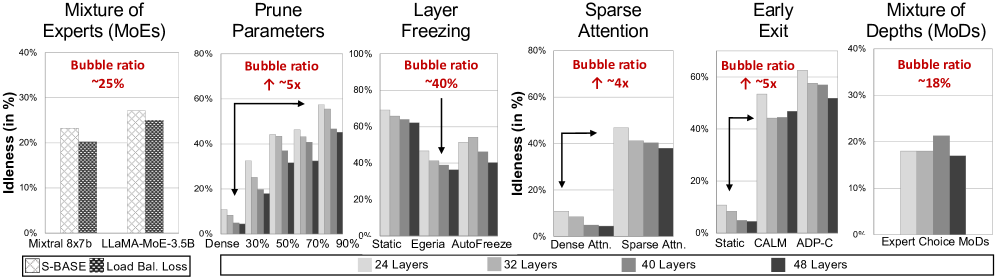
- 现有动态LLM训练方法(如MoE、剪枝等)虽然能减少计算量,但常引入严重的worker间负载不均衡,限制了其在大规模分布式训练中的应用。
- DynMo通过自主动态负载均衡,最大程度降低工作负载不平衡,自适应均衡流水线并行训练中各worker的计算负载,提升训练效率。
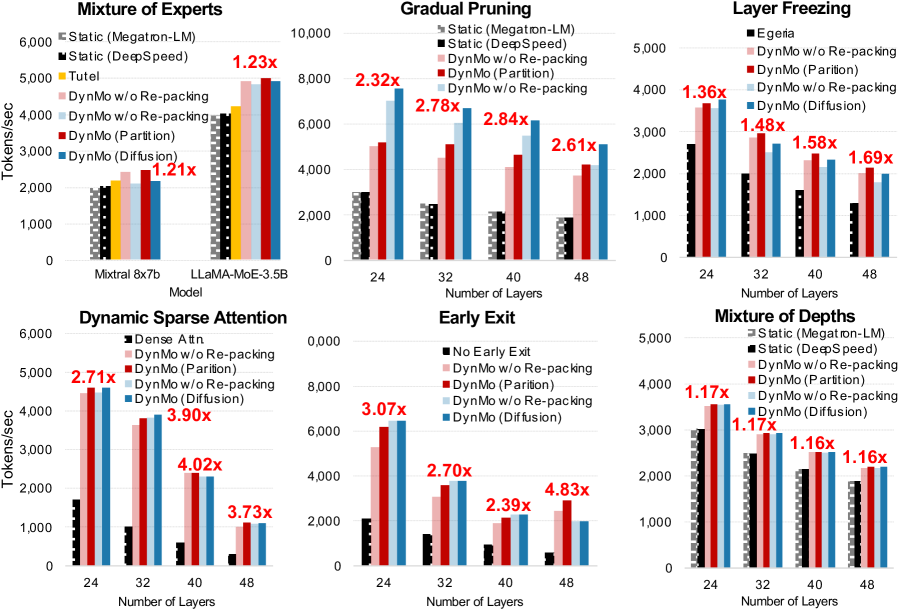
- 实验表明,DynMo在多种动态GPT模型训练中,相比静态分布式训练方案,实现了显著的加速,例如在早退机制上加速高达4.52倍。
📝 摘要(中文)
为了降低大型语言模型的计算和内存开销,涌现了多种方法,包括:混合专家模型(MoE)、模型参数的逐步剪枝、动态冻结层、动态稀疏注意力机制、token的提前退出以及混合深度模型(MoD)。尽管这些方法在减少总体计算量方面有效,但它们通常会在worker之间引入显著的工作负载不平衡。在许多情况下,这种不平衡非常严重,导致这些技术在大型分布式训练中不切实际,由于效率低下而限制了它们在玩具模型中的应用。我们提出了一种自主动态负载平衡解决方案DynMo,该方案可证明地实现了工作负载不平衡的最大程度降低,并自适应地均衡了流水线并行训练中各个worker的计算负载。此外,DynMo动态地将计算整合到更少的worker上,而不会牺牲训练吞吐量,从而允许将空闲的worker释放回作业管理器。DynMo支持单节点多GPU系统和多节点GPU集群,并且可以用于实际部署。与Megatron-LM和DeepSpeed等静态分布式训练解决方案相比,DynMo将动态GPT模型的端到端训练加速了MoE的1.23倍,参数剪枝的3.18倍,层冻结的2.23倍,稀疏注意力的4.02倍,提前退出的4.52倍以及MoD的1.17倍。
🔬 方法详解
问题定义:现有动态LLM训练方法,如MoE、剪枝、动态层冻结等,旨在降低计算成本。然而,这些方法往往导致不同worker之间的计算负载严重不均衡,使得大规模分布式训练效率低下,成为实际应用的瓶颈。现有静态分布式训练方法无法有效解决这种动态负载不均衡问题。
核心思路:DynMo的核心思路是实现自主动态的负载均衡。它通过实时监控各个worker的计算负载,并动态地调整任务分配,从而均衡各个worker的计算量。此外,DynMo还支持动态地将计算整合到更少的worker上,释放空闲资源,提高资源利用率。
技术框架:DynMo的整体框架包含以下几个主要模块:1) 负载监控模块:实时收集各个worker的计算负载信息。2) 负载均衡决策模块:基于负载信息,计算出最优的任务分配方案,以均衡各个worker的负载。3) 任务调度模块:根据负载均衡决策,动态地将任务分配给不同的worker。4) 资源管理模块:动态地调整worker的数量,将空闲的worker释放回资源池。
关键创新:DynMo的关键创新在于其自主动态的负载均衡策略。与传统的静态分配策略不同,DynMo能够根据实际的计算负载情况,动态地调整任务分配,从而最大程度地减少负载不平衡。此外,DynMo还支持动态的资源伸缩,能够根据计算需求,动态地调整worker的数量,提高资源利用率。
关键设计:DynMo的关键设计包括:1) 细粒度的负载监控:能够实时监控各个worker的计算负载,包括GPU利用率、内存占用等。2) 高效的负载均衡算法:采用高效的优化算法,快速计算出最优的任务分配方案。3) 低开销的任务调度机制:采用轻量级的任务调度机制,减少调度开销。4) 灵活的资源管理策略:支持多种资源管理策略,能够根据不同的应用场景,选择合适的资源管理方式。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DynMo在多种动态GPT模型的端到端训练中,相比Megatron-LM和DeepSpeed等静态分布式训练解决方案,实现了显著的加速。具体而言,对于MoE模型,加速了1.23倍;对于参数剪枝,加速了3.18倍;对于层冻结,加速了2.23倍;对于稀疏注意力,加速了4.02倍;对于早退出机制,加速了4.52倍;对于MoD模型,加速了1.17倍。
🎯 应用场景
DynMo适用于各种需要进行大规模分布式训练的动态LLM,例如MoE模型、剪枝模型、动态层冻结模型等。它可以显著提高训练效率,降低训练成本,加速LLM的研发和部署。该技术在自然语言处理、机器翻译、文本生成等领域具有广泛的应用前景。
📄 摘要(原文)
To reduce the computational and memory overhead of Large Language Models, various approaches have been proposed. These include a) Mixture of Experts (MoEs), where token routing affects compute balance; b) gradual pruning of model parameters; c) dynamically freezing layers; d) dynamic sparse attention mechanisms; e) early exit of tokens as they pass through model layers; and f) Mixture of Depths (MoDs), where tokens bypass certain blocks. While these approaches are effective in reducing overall computation, they often introduce significant workload imbalance across workers. In many cases, this imbalance is severe enough to render the techniques impractical for large-scale distributed training, limiting their applicability to toy models due to poor efficiency. We propose an autonomous dynamic load balancing solution, DynMo, which provably achieves maximum reduction in workload imbalance and adaptively equalizes compute loads across workers in pipeline-parallel training. In addition, DynMo dynamically consolidates computation onto fewer workers without sacrificing training throughput, allowing idle workers to be released back to the job manager. DynMo supports both single-node multi-GPU systems and multi-node GPU clusters, and can be used in practical deployment. Compared to static distributed training solutions such as Megatron-LM and DeepSpeed, DynMo accelerates the end-to-end training of dynamic GPT models by up to 1.23x for MoEs, 3.18x for parameter pruning, 2.23x for layer freezing, 4.02x for sparse attention, 4.52x for early exit, and 1.17x for MoDs.