SAFEPATH: Preventing Harmful Reasoning in Chain-of-Thought via Early Alignment
作者: Wonje Jeung, Sangyeon Yoon, Minsuk Kahng, Albert No
分类: cs.AI, cs.CL
发布日期: 2025-05-20 (更新: 2025-10-23)
备注: Accepted at NeurIPS 2025. Code and models are available at https://ai-isl.github.io/safepath
💡 一句话要点
提出SAFEPATH以解决大型推理模型的安全性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型推理模型 安全对齐 有害输出 推理深度 越狱攻击 轻量级方法 人工智能安全 深度学习
📋 核心要点
- 现有的安全对齐方法在减少有害输出的同时,往往会降低推理深度,导致复杂任务中的显著权衡。
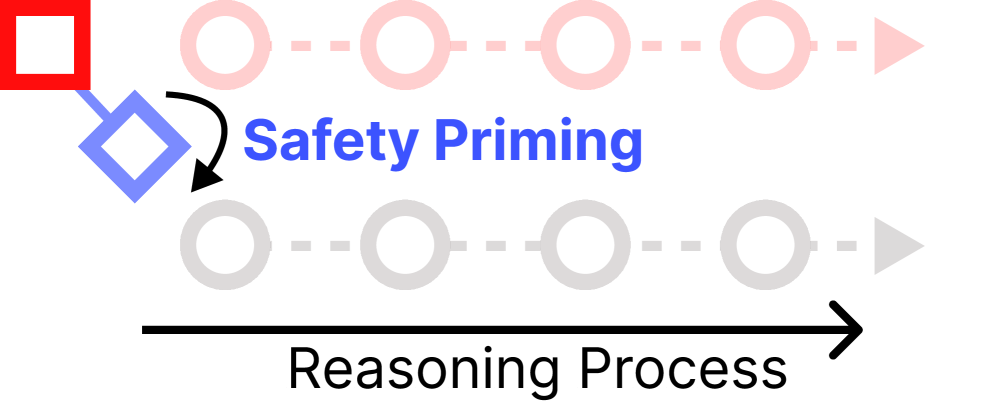
- SAFEPATH通过在推理开始时发出短小的安全引导,针对有害提示进行轻量级对齐,同时保持后续推理过程的自主性。
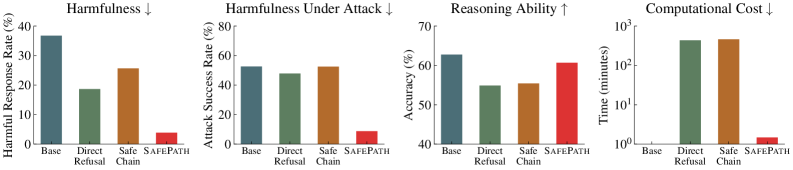
- 实验结果显示,SAFEPATH在DeepSeek-R1-Distill-Llama-8B模型中将有害响应减少了90.0%,并阻止了83.3%的越狱尝试,计算效率显著提升。
📝 摘要(中文)
大型推理模型(LRMs)在复杂问题解决中表现出色,但其结构化推理路径在面对有害提示时可能产生不安全的输出。现有的安全对齐方法虽然能减少有害输出,但往往会降低推理深度,导致在复杂多步任务中出现显著的权衡,并且仍然容易受到复杂的越狱攻击。为此,本文提出SAFEPATH,这是一种轻量级的对齐方法,通过在推理开始时针对有害提示发出短小的8-token安全引导,同时保持其余推理过程不受监督。实验证明,SAFEPATH有效降低了有害输出,同时保持了推理性能,具体而言,SAFEPATH将有害响应减少了高达90.0%,并阻止了83.3%的越狱尝试,同时计算需求比直接拒绝方法低295.9倍,比SafeChain低314.1倍。我们还介绍了一种无需微调的零-shot变体,并对现有方法在推理中心模型中的泛化能力进行了全面分析,揭示了关键的缺口和安全AI的新方向。
🔬 方法详解
问题定义:本文旨在解决大型推理模型在面对有害提示时产生不安全输出的问题。现有的安全对齐方法虽然能减少有害输出,但往往会降低推理深度,并且容易受到越狱攻击。
核心思路:SAFEPATH的核心思路是通过在推理开始时发出一个短小的安全引导,来有效应对有害提示,同时保持后续推理过程的自主性,从而避免了现有方法的深度损失。
技术框架:SAFEPATH的整体架构包括两个主要阶段:第一阶段是生成8-token的安全引导,第二阶段是进行自主推理。该方法在处理有害提示时,首先生成安全引导,然后进入正常的推理流程。
关键创新:SAFEPATH的主要创新在于其轻量级的对齐机制,通过短小的安全引导来实现对有害提示的响应,这与现有方法的全面监督方式形成了本质区别。
关键设计:在设计上,SAFEPATH采用了特定的参数设置以优化安全引导的生成,同时在损失函数上进行了调整,以确保在减少有害输出的同时不影响推理性能。
🖼️ 关键图片

📊 实验亮点
SAFEPATH在DeepSeek-R1-Distill-Llama-8B模型中将有害响应减少了高达90.0%,并成功阻止了83.3%的越狱尝试。同时,该方法的计算需求显著低于现有的直接拒绝和SafeChain方法,分别降低了295.9倍和314.1倍,显示出其在效率和安全性上的双重优势。
🎯 应用场景
SAFEPATH的研究成果具有广泛的应用潜力,尤其是在需要高安全性和可靠性的人工智能系统中,如医疗诊断、金融决策和自动驾驶等领域。通过有效减少有害输出,该方法能够提升AI系统的安全性,增强用户信任,并推动更安全的AI技术发展。
📄 摘要(原文)
Large Reasoning Models (LRMs) have become powerful tools for complex problem solving, but their structured reasoning pathways can lead to unsafe outputs when exposed to harmful prompts. Existing safety alignment methods reduce harmful outputs but can degrade reasoning depth, leading to significant trade-offs in complex, multi-step tasks, and remain vulnerable to sophisticated jailbreak attacks. To address this, we introduce SAFEPATH, a lightweight alignment method that fine-tunes LRMs to emit a short, 8-token Safety Primer at the start of their reasoning, in response to harmful prompts, while leaving the rest of the reasoning process unsupervised. Empirical results across multiple benchmarks indicate that SAFEPATH effectively reduces harmful outputs while maintaining reasoning performance. Specifically, SAFEPATH reduces harmful responses by up to 90.0% and blocks 83.3% of jailbreak attempts in the DeepSeek-R1-Distill-Llama-8B model, while requiring 295.9x less compute than Direct Refusal and 314.1x less than SafeChain. We further introduce a zero-shot variant that requires no fine-tuning. In addition, we provide a comprehensive analysis of how existing methods in LLMs generalize, or fail, when applied to reasoning-centric models, revealing critical gaps and new directions for safer AI.