Guarded Query Routing for Large Language Models
作者: Richard Šléher, William Brach, Tibor Sloboda, Kristián Košťál, Lukas Galke
分类: cs.AI
发布日期: 2025-05-20 (更新: 2025-10-25)
DOI: 10.3233/FAIA251304
🔗 代码/项目: GITHUB
💡 一句话要点
提出GQR-Bench基准测试,并研究了LLM在安全查询路由中的有效性和效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 查询路由 大型语言模型 分布外检测 基准测试 文本分类
📋 核心要点
- 现有查询路由方法在处理分布外查询时存在不足,可能导致错误分类或安全问题。
- 论文提出GQR-Bench基准测试,用于评估不同模型在受保护查询路由任务中的性能,并对比了多种模型。
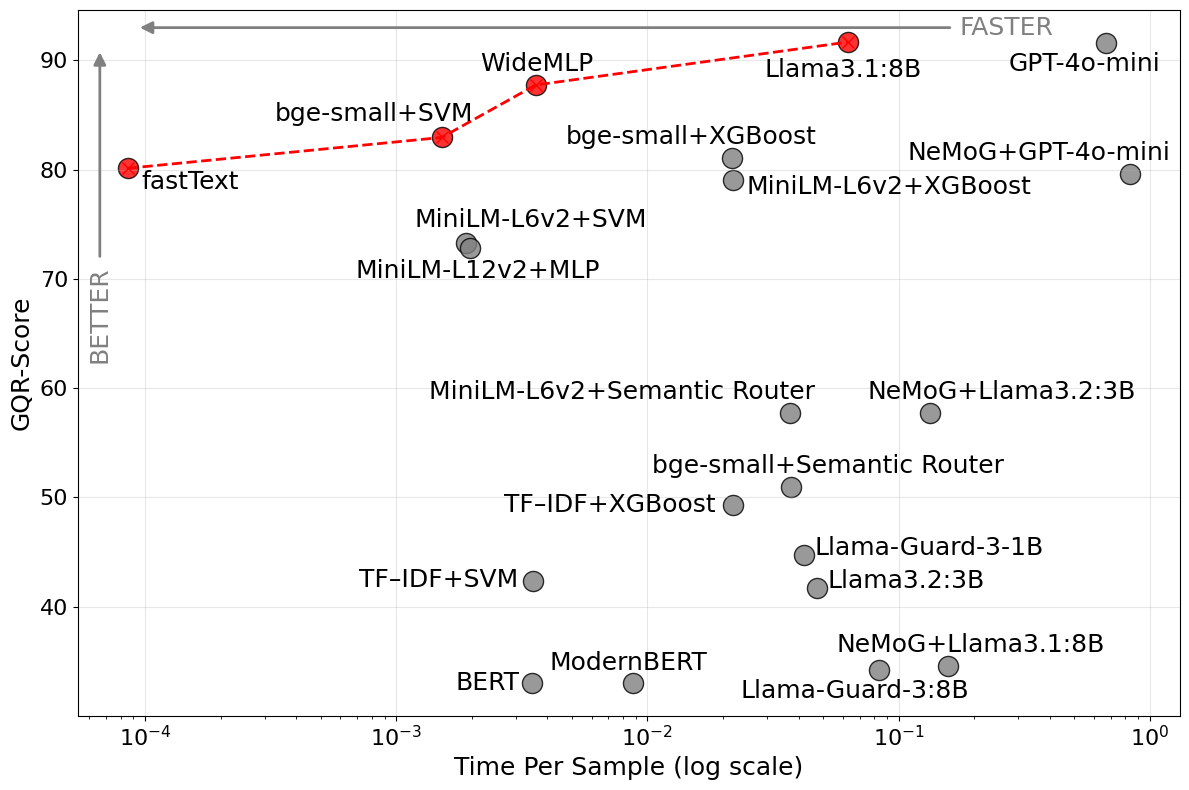
- 实验结果表明,WideMLP在准确率和速度之间取得了最佳平衡,挑战了对LLM的过度依赖。
📝 摘要(中文)
查询路由是将用户查询分配给不同的大型语言模型(LLM)端点的任务,可以被视为文本分类问题。然而,必须妥善处理分布外的查询,因为它们可能涉及不相关的领域、其他语言的查询,甚至包含不安全文本。因此,我们研究了一个受保护的查询路由问题,为此我们首先引入了受保护的查询路由基准(GQR-Bench,以Python包gqr形式发布),涵盖三个示例目标领域(法律、金融和医疗保健)和七个数据集,以测试针对分布外查询的鲁棒性。然后,我们使用GQR-Bench来对比基于LLM的路由机制(GPT-4o-mini、Llama-3.2-3B和Llama-3.1-8B)、标准的基于LLM的防护栏方法(LlamaGuard和NVIDIA NeMo Guardrails)、连续词袋分类器(WideMLP、fastText)和传统机器学习模型(SVM、XGBoost)的有效性和效率。我们的结果表明,通过领域外检测能力增强的WideMLP在准确率(88%)和速度(<4ms)之间取得了最佳平衡。基于嵌入的fastText在速度(<1ms)方面表现出色,准确率可接受(80%),而LLM的准确率最高(91%),但速度相对较慢(本地Llama-3.1:8B为62ms,远程GPT-4o-mini调用为669ms)。我们的发现挑战了对LLM在(受保护的)查询路由中的自动依赖,并为实际应用提供了具体建议。源代码可在https://github.com/williambrach/gqr获取。
🔬 方法详解
问题定义:论文旨在解决查询路由任务中,如何有效且安全地处理分布外(OOD)查询的问题。现有方法,特别是直接依赖LLM的方法,在面对不相关领域、其他语言或包含不安全内容的查询时,鲁棒性不足,可能导致错误路由或安全风险。
核心思路:论文的核心思路是通过构建一个包含多种OOD查询的基准测试集GQR-Bench,来系统地评估不同查询路由方法在实际应用中的性能。同时,探索传统机器学习模型与LLM在效率和准确率之间的权衡,并提出结合OOD检测的WideMLP模型,以实现更好的性能。
技术框架:论文的技术框架主要包含以下几个部分:1) 构建GQR-Bench基准测试集,包含法律、金融和医疗保健三个领域的数据集,以及多种OOD查询。2) 评估多种查询路由方法,包括LLM(GPT-4o-mini、Llama-3.2-3B、Llama-3.1-8B)、LLM Guardrails(LlamaGuard、NVIDIA NeMo Guardrails)、连续词袋模型(WideMLP、fastText)和传统机器学习模型(SVM、XGBoost)。3) 对比不同方法的准确率和速度,并分析其优缺点。
关键创新:论文的关键创新点在于:1) 提出了GQR-Bench基准测试集,为受保护的查询路由任务提供了一个标准化的评估平台。2) 发现传统机器学习模型,特别是结合OOD检测的WideMLP,在准确率和速度方面可以优于或匹敌LLM,挑战了对LLM的过度依赖。
关键设计:论文的关键设计包括:1) GQR-Bench基准测试集的构建,包含了多种类型的OOD查询,以全面评估模型的鲁棒性。2) WideMLP模型结合了OOD检测机制,例如使用自编码器或对抗生成网络来识别OOD查询,并将其路由到安全处理模块。3) 实验中对不同模型的参数进行了优化,并使用了标准化的评估指标(准确率、速度)进行对比。
🖼️ 关键图片

📊 实验亮点
实验结果表明,WideMLP在准确率(88%)和速度(<4ms)之间取得了最佳平衡,优于其他模型。fastText在速度方面表现出色(<1ms),但准确率稍低(80%)。LLM的准确率最高(91%),但速度较慢(Llama-3.1:8B为62ms,GPT-4o-mini为669ms)。这些结果表明,在实际应用中,需要根据具体需求权衡准确率和速度,选择合适的查询路由模型。
🎯 应用场景
该研究成果可应用于各种需要安全查询路由的场景,例如智能客服、法律咨询、金融风控和医疗诊断等。通过选择合适的查询路由模型,可以提高系统的准确性和安全性,降低运营成本,并提升用户体验。未来的研究可以进一步探索更有效的OOD检测方法和更轻量级的查询路由模型。
📄 摘要(原文)
Query routing, the task to route user queries to different large language model (LLM) endpoints, can be considered as a text classification problem. However, out-of-distribution queries must be handled properly, as those could be about unrelated domains, queries in other languages, or even contain unsafe text. Here, we thus study a guarded query routing problem, for which we first introduce the Guarded Query Routing Benchmark (GQR-Bench, released as Python package gqr), covers three exemplary target domains (law, finance, and healthcare), and seven datasets to test robustness against out-of-distribution queries. We then use GQR-Bench to contrast the effectiveness and efficiency of LLM-based routing mechanisms (GPT-4o-mini, Llama-3.2-3B, and Llama-3.1-8B), standard LLM-based guardrail approaches (LlamaGuard and NVIDIA NeMo Guardrails), continuous bag-of-words classifiers (WideMLP, fastText), and traditional machine learning models (SVM, XGBoost). Our results show that WideMLP, enhanced with out-of-domain detection capabilities, yields the best trade-off between accuracy (88%) and speed (<4ms). The embedding-based fastText excels at speed (<1ms) with acceptable accuracy (80%), whereas LLMs yield the highest accuracy (91%) but are comparatively slow (62ms for local Llama-3.1:8B and 669ms for remote GPT-4o-mini calls). Our findings challenge the automatic reliance on LLMs for (guarded) query routing and provide concrete recommendations for practical applications. Source code is available: https://github.com/williambrach/gqr.