SCAN: Semantic Document Layout Analysis for Textual and Visual Retrieval-Augmented Generation
作者: Yuyang Dong, Nobuhiro Ueda, Krisztián Boros, Daiki Ito, Takuya Sera, Masafumi Oyamada
分类: cs.AI
发布日期: 2025-05-20 (更新: 2025-12-11)
💡 一句话要点
提出SCAN:一种语义文档布局分析方法,提升文本和视觉RAG性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档布局分析 语义分割 检索增强生成 视觉-语言模型 富文档处理
📋 核心要点
- 现有方法在处理包含大量信息的富文档时,RAG性能面临挑战,需要更有效的文档分割和理解方法。
- SCAN通过粗粒度的语义分析,将文档分割成连贯的区域,平衡了上下文保留和VLM的处理效率。
- 实验结果表明,SCAN在文本和视觉RAG任务中,相较于传统方法和商业方案,性能分别提升高达9.4和10.4个点。
📝 摘要(中文)
随着大型语言模型(LLMs)和视觉-语言模型(VLMs)的日益普及,用于检索增强生成(RAG)和视觉RAG等应用的富文档分析技术正受到广泛关注。 近期研究表明,使用VLM可以获得更好的RAG性能,但处理富文档仍然是一个挑战,因为单个页面包含大量信息。本文提出了一种新颖的方法SCAN(语义文档布局分析),旨在增强处理视觉丰富文档的文本和视觉检索增强生成(RAG)系统。SCAN是一种VLM友好的方法,它以适当的语义粒度识别文档组件,从而平衡上下文保留和处理效率。SCAN使用粗粒度的语义方法将文档划分为覆盖连续组件的连贯区域。我们通过在带注释的数据集上微调目标检测模型来训练SCAN模型。在英语和日语数据集上的实验结果表明,应用SCAN可将端到端文本RAG性能提高高达9.4个点,将视觉RAG性能提高高达10.4个点,优于传统方法甚至商业文档处理解决方案。
🔬 方法详解
问题定义:论文旨在解决视觉丰富文档的检索增强生成(RAG)问题。现有方法在处理此类文档时,由于单个页面信息量大,导致RAG性能受限。传统的文档处理方法要么粒度过细,导致上下文信息丢失,要么粒度过粗,难以有效利用VLM的能力。
核心思路:SCAN的核心思路是采用一种粗粒度的语义文档布局分析方法,将文档分割成具有语义连贯性的区域。这种方法旨在平衡上下文信息的保留和VLM的处理效率,使得VLM能够更好地理解和利用文档中的信息。通过将文档分割成语义相关的区域,SCAN能够减少噪声,突出关键信息,从而提升RAG的性能。
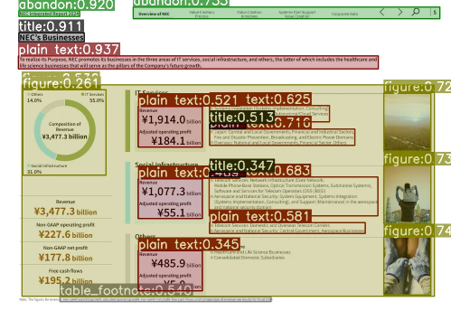
技术框架:SCAN的整体框架包括以下几个主要步骤:1) 文档输入:接收视觉丰富的文档作为输入。2) 语义文档布局分析:使用训练好的SCAN模型对文档进行布局分析,将文档分割成语义连贯的区域。3) 特征提取:提取每个区域的文本和视觉特征。4) 检索增强生成:利用提取的特征进行检索,并生成相应的文本或视觉内容。SCAN模型基于目标检测模型进行微调,以识别文档中的不同语义区域。
关键创新:SCAN的关键创新在于其粗粒度的语义文档布局分析方法。与传统的细粒度或粗粒度方法相比,SCAN能够更好地平衡上下文信息的保留和VLM的处理效率。此外,SCAN通过在带注释的数据集上微调目标检测模型,实现了对文档布局的准确分析。
关键设计:SCAN的关键设计包括:1) 语义区域的定义:定义了文档中具有语义连贯性的区域,例如段落、标题、表格等。2) 目标检测模型的选择和微调:选择合适的目标检测模型,并在带注释的数据集上进行微调,以提高模型对文档布局的识别精度。3) 损失函数的设计:设计合适的损失函数,以优化模型的训练过程。具体参数设置和网络结构的选择取决于具体的目标检测模型和数据集。
🖼️ 关键图片
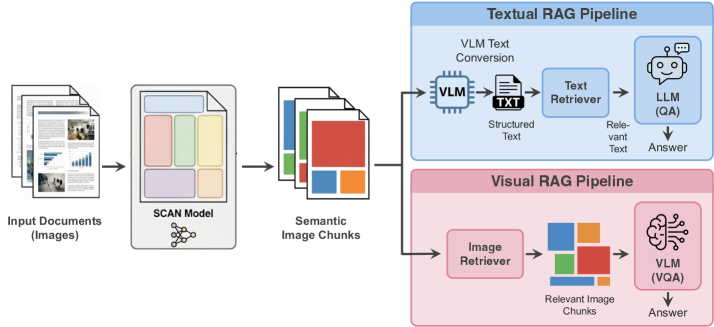

📊 实验亮点
SCAN在英语和日语数据集上进行了实验,结果表明,SCAN能够显著提升文本和视觉RAG的性能。具体而言,SCAN将端到端文本RAG性能提高了高达9.4个点,将视觉RAG性能提高了高达10.4个点。SCAN的性能优于传统的文档处理方法,甚至超过了商业文档处理解决方案。
🎯 应用场景
SCAN技术可广泛应用于各种需要处理视觉丰富文档的场景,例如智能文档处理、信息检索、问答系统、报告生成等。该技术能够提升RAG系统的性能,从而提高用户获取信息的效率和准确性。未来,SCAN有望在企业知识管理、教育资源整合、金融文档分析等领域发挥重要作用。
📄 摘要(原文)
With the increasing adoption of Large Language Models (LLMs) and Vision-Language Models (VLMs), rich document analysis technologies for applications like Retrieval-Augmented Generation (RAG) and visual RAG are gaining significant attention. Recent research indicates that using VLMs yields better RAG performance, but processing rich documents remains a challenge since a single page contains large amounts of information. In this paper, we present SCAN (SemantiC Document Layout ANalysis), a novel approach that enhances both textual and visual Retrieval-Augmented Generation (RAG) systems that work with visually rich documents. It is a VLM-friendly approach that identifies document components with appropriate semantic granularity, balancing context preservation with processing efficiency. SCAN uses a coarse-grained semantic approach that divides documents into coherent regions covering contiguous components. We trained the SCAN model by fine-tuning object detection models on an annotated dataset. Our experimental results across English and Japanese datasets demonstrate that applying SCAN improves end-to-end textual RAG performance by up to 9.4 points and visual RAG performance by up to 10.4 points, outperforming conventional approaches and even commercial document processing solutions.