DSMentor: Enhancing Data Science Agents with Curriculum Learning and Online Knowledge Accumulation
作者: He Wang, Alexander Hanbo Li, Yiqun Hu, Sheng Zhang, Hideo Kobayashi, Jiani Zhang, Henry Zhu, Chung-Wei Hang, Patrick Ng
分类: cs.AI
发布日期: 2025-05-20
💡 一句话要点
DSMentor:利用课程学习和在线知识积累增强数据科学Agent能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据科学Agent 课程学习 长期记忆 推理优化 因果推理
📋 核心要点
- 现有LLM Agent在数据科学任务中面临挑战,尤其是在复杂问题上,传统方法侧重于上下文学习,忽略了任务顺序的重要性。
- DSMentor通过课程学习,由简入难地组织任务,并结合长期记忆积累经验,引导Agent学习,从而提升解决复杂问题的能力。
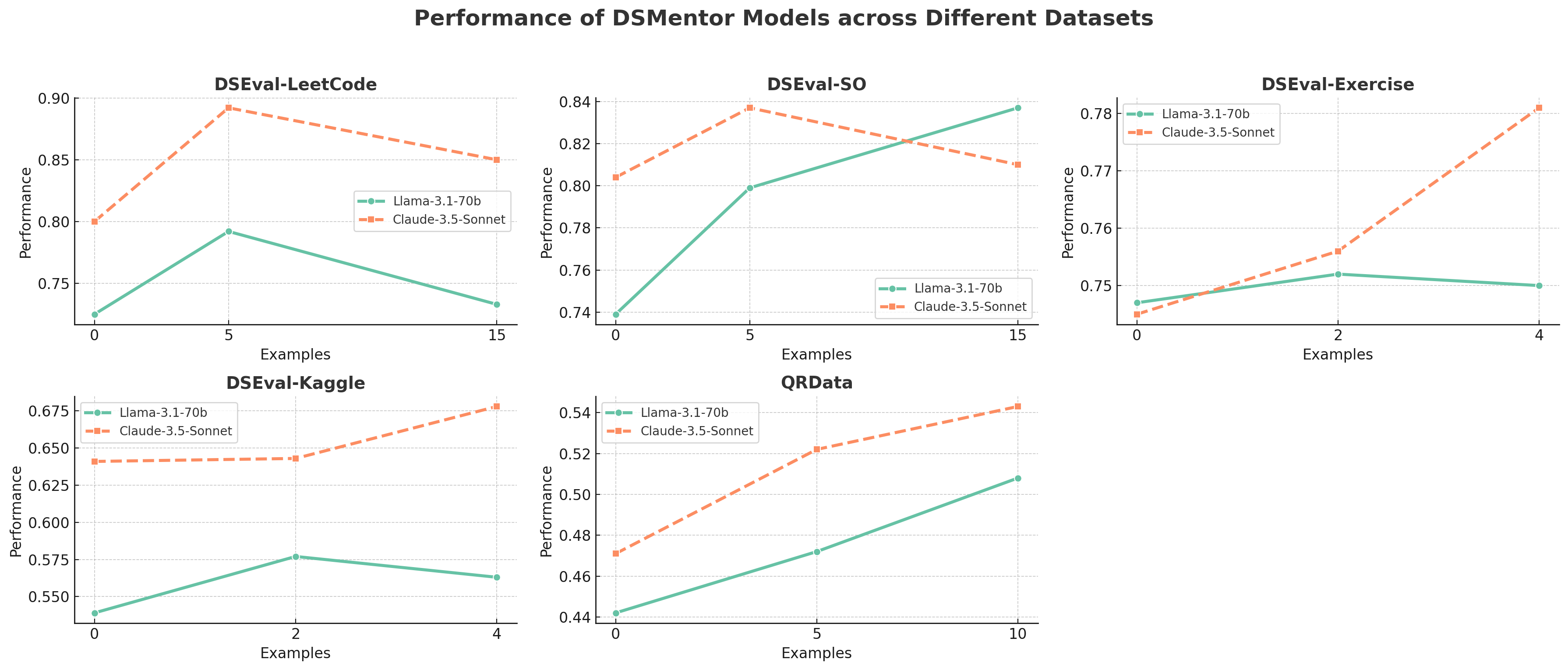
- 实验结果表明,DSMentor在DSEval和QRData等基准测试中,相比基线Agent,通过率显著提升,尤其在因果推理问题上表现突出。
📝 摘要(中文)
大型语言模型(LLM)Agent在生成代码以解决复杂数据科学问题方面表现出良好的性能。目前的研究主要集中于通过改进搜索、采样和规划技术来增强上下文学习,而忽略了在推理过程中解决问题的顺序的重要性。本文提出了一种新颖的推理时优化框架,称为DSMentor,它利用课程学习——一种首先引入更简单的任务,然后随着学习者的进步逐步转向更复杂的任务的策略——来增强LLM Agent在具有挑战性的数据科学任务中的性能。我们的导师引导框架按照难度递增的顺序组织数据科学任务,并结合不断增长的长期记忆来保留先前的经验,从而指导Agent的学习过程,并能够更有效地利用积累的知识。我们通过在DSEval和QRData基准上的大量实验评估了DSMentor。实验表明,与基线Agent相比,使用Claude-3.5-Sonnet的DSMentor在DSEval和QRData上的通过率提高了高达5.2%。此外,DSMentor表现出更强的因果推理能力,与使用思维链提示的GPT-4相比,在因果关系问题上的通过率提高了8.8%。我们的工作强调了开发有效策略以在推理过程中积累和利用知识的重要性,这反映了人类的学习过程,并为通过基于课程的推理优化来提高LLM性能开辟了新途径。
🔬 方法详解
问题定义:论文旨在解决LLM Agent在复杂数据科学任务中表现不佳的问题。现有方法主要关注改进上下文学习,例如优化搜索、采样和规划策略,但忽略了任务呈现顺序对Agent学习效果的影响。这种忽略导致Agent难以有效利用已学知识解决后续问题,尤其是在需要较强因果推理能力的任务中。
核心思路:论文的核心思路是借鉴课程学习的思想,即从简单到复杂地组织任务,并结合长期记忆机制,使Agent能够逐步学习和积累知识。通过这种方式,Agent可以更好地理解和解决复杂问题,并能有效利用先前学习的经验。这种方法模拟了人类的学习过程,有助于Agent更有效地掌握数据科学技能。
技术框架:DSMentor框架主要包含两个核心组件:课程生成器和长期记忆模块。课程生成器负责根据任务的难度进行排序,形成由简到繁的任务序列。长期记忆模块用于存储Agent在先前任务中获得的知识和经验,并在后续任务中进行检索和利用。Agent在解决每个任务时,会首先从长期记忆中检索相关知识,然后结合当前任务的输入进行推理和代码生成。
关键创新:DSMentor的关键创新在于将课程学习和长期记忆机制结合起来,用于优化LLM Agent在数据科学任务中的推理过程。与现有方法相比,DSMentor不仅关注如何更好地利用上下文信息,还关注如何通过合理的任务组织和知识积累来提升Agent的学习效率和问题解决能力。
关键设计:课程生成器使用启发式规则或机器学习模型来评估任务难度,例如可以根据任务涉及的数据量、代码复杂度或所需推理步骤的数量来确定难度。长期记忆模块可以使用向量数据库或知识图谱来存储和检索知识。Agent在解决任务时,可以使用注意力机制或相似度匹配来从长期记忆中选择相关知识。具体的损失函数和网络结构取决于所使用的LLM Agent和长期记忆模块。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DSMentor在DSEval和QRData基准测试中,使用Claude-3.5-Sonnet模型时,相比基线Agent,通过率分别提升了5.2%。更重要的是,在因果推理问题上,DSMentor相比使用思维链提示的GPT-4模型,通过率提升了8.8%,表明DSMentor在提升Agent的因果推理能力方面具有显著优势。
🎯 应用场景
DSMentor具有广泛的应用前景,可用于自动化数据分析、机器学习模型开发、数据科学教育等领域。通过提供更有效的学习和推理框架,DSMentor可以帮助数据科学家更高效地解决复杂问题,并降低数据科学的入门门槛。未来,该技术有望应用于更广泛的AI Agent领域,提升Agent在各种复杂任务中的表现。
📄 摘要(原文)
Large language model (LLM) agents have shown promising performance in generating code for solving complex data science problems. Recent studies primarily focus on enhancing in-context learning through improved search, sampling, and planning techniques, while overlooking the importance of the order in which problems are tackled during inference. In this work, we develop a novel inference-time optimization framework, referred to as DSMentor, which leverages curriculum learning -- a strategy that introduces simpler task first and progressively moves to more complex ones as the learner improves -- to enhance LLM agent performance in challenging data science tasks. Our mentor-guided framework organizes data science tasks in order of increasing difficulty and incorporates a growing long-term memory to retain prior experiences, guiding the agent's learning progression and enabling more effective utilization of accumulated knowledge. We evaluate DSMentor through extensive experiments on DSEval and QRData benchmarks. Experiments show that DSMentor using Claude-3.5-Sonnet improves the pass rate by up to 5.2% on DSEval and QRData compared to baseline agents. Furthermore, DSMentor demonstrates stronger causal reasoning ability, improving the pass rate by 8.8% on the causality problems compared to GPT-4 using Program-of-Thoughts prompts. Our work underscores the importance of developing effective strategies for accumulating and utilizing knowledge during inference, mirroring the human learning process and opening new avenues for improving LLM performance through curriculum-based inference optimization.