RL of Thoughts: Navigating LLM Reasoning with Inference-time Reinforcement Learning
作者: Qianyue Hao, Sibo Li, Jian Yuan, Yong Li
分类: cs.AI
发布日期: 2025-05-20 (更新: 2025-09-25)
💡 一句话要点
RLoT:利用推理时强化学习引导LLM进行复杂推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 推理时学习 思维链 自适应推理 逻辑推理 导航器模型
📋 核心要点
- 现有推理时技术缺乏对不同任务的适应性,限制了LLM的推理能力。
- RLoT通过强化学习训练导航器模型,动态选择逻辑块组合成任务特定的推理结构。
- 实验表明,RLoT在多个基准测试中优于现有方法,且具有良好的可迁移性。
📝 摘要(中文)
大型语言模型(LLM)的快速发展受到其token级别自回归特性的限制,影响了其复杂推理能力。为了增强LLM的推理能力,推理时技术,如思维链/树/图,通过在不修改LLM参数的情况下,利用复杂的逻辑结构引导推理,从而有效地提高了性能。然而,这些手动预定义的、与任务无关的框架在不同的任务中统一应用,缺乏适应性。为了改进这一点,我们提出了RL-of-Thoughts(RLoT),我们使用强化学习(RL)训练一个轻量级的导航器模型,以在推理时自适应地增强LLM的推理能力。具体来说,我们从人类认知的角度设计了五个基本的逻辑块。在推理过程中,训练好的RL导航器根据问题的特点动态地选择合适的逻辑块,并将它们组合成特定于任务的逻辑结构。在多个推理基准(AIME、MATH、GPQA等)上,使用多个LLM(GPT、Llama、Qwen和DeepSeek)进行的实验表明,RLoT的性能优于已建立的推理时技术,最高可达13.4%。值得注意的是,我们的RL导航器只有不到3K的参数,就能使sub-10B的LLM与100B规模的LLM相媲美。此外,RL导航器表现出强大的可迁移性:在一个特定的LLM-任务对上训练的模型可以有效地推广到未见过的LLM和任务。我们的代码在https://anonymous.4open.science/r/RL-LLM-Reasoning-1A30开源,以保证可重复性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂推理任务中表现不佳的问题。现有的推理时方法,如思维链(Chain-of-Thought)等,通常采用预定义的、与任务无关的逻辑结构,缺乏对不同任务的适应性,导致推理效率和准确性受限。这些方法无法根据问题的特点动态调整推理策略,造成资源浪费和性能瓶颈。
核心思路:论文的核心思路是利用强化学习(RL)训练一个轻量级的导航器模型,该模型能够在推理过程中动态地选择和组合不同的逻辑块,从而构建任务特定的推理结构。这种自适应的推理方式能够更好地利用LLM的知识和能力,提高推理的效率和准确性。通过模仿人类认知过程中的逻辑推理方式,设计了一系列基本的逻辑块,作为导航器模型的操作空间。
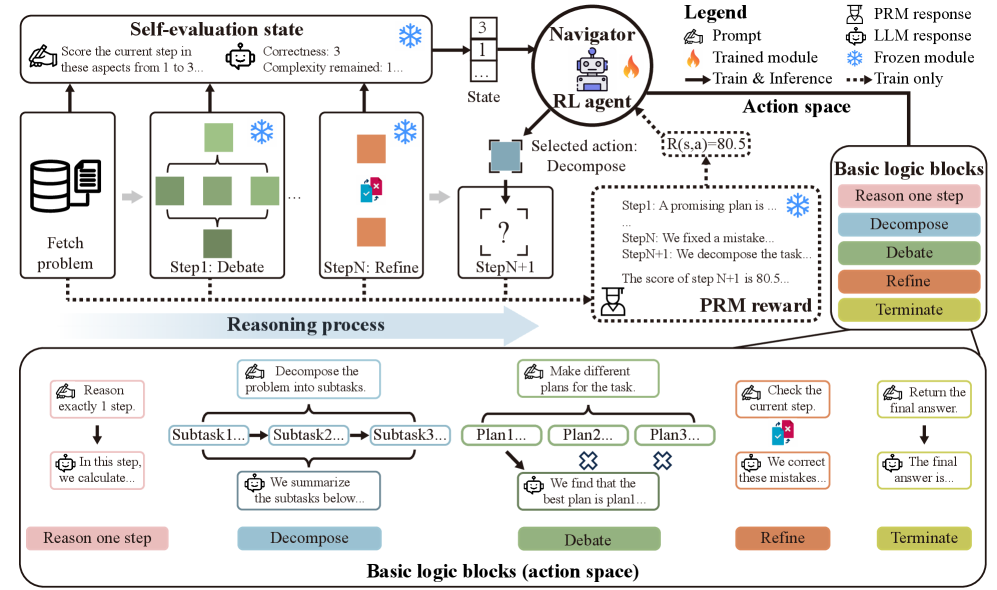
技术框架:RLoT的整体框架包含以下几个主要模块:1)LLM:作为基础的知识来源和推理引擎;2)逻辑块:预定义的、可组合的推理单元,例如分解问题、生成假设、验证假设等;3)RL导航器:一个轻量级的模型,负责根据当前推理状态选择合适的逻辑块;4)环境:模拟推理过程,并根据LLM的输出和任务目标给出奖励信号。推理过程是一个迭代的过程,RL导航器根据当前状态选择一个逻辑块,LLM执行该逻辑块并生成新的状态,环境给出奖励信号,RL导航器根据奖励信号更新策略。
关键创新:RLoT的关键创新在于引入了强化学习来动态地控制LLM的推理过程。与传统的推理时方法相比,RLoT能够根据问题的特点自适应地调整推理策略,从而提高推理的效率和准确性。此外,RLoT通过设计一系列基本的逻辑块,将复杂的推理过程分解为一系列可控的操作,使得RL导航器能够更好地理解和控制LLM的推理过程。
关键设计:RL导航器是一个轻量级的神经网络,输入是当前推理状态的表示,输出是选择不同逻辑块的概率。论文采用策略梯度方法训练RL导航器,奖励函数的设计至关重要,需要综合考虑LLM的输出质量和任务目标。具体来说,奖励函数可以包括:1)正确性奖励:如果LLM的输出是正确的,则给予正向奖励;2)效率奖励:如果LLM在较少的步骤内完成推理,则给予正向奖励;3)惩罚项:如果LLM的输出不合理或与任务目标不符,则给予负向奖励。论文还探索了不同的网络结构和训练技巧,以提高RL导航器的性能和泛化能力。
🖼️ 关键图片

📊 实验亮点
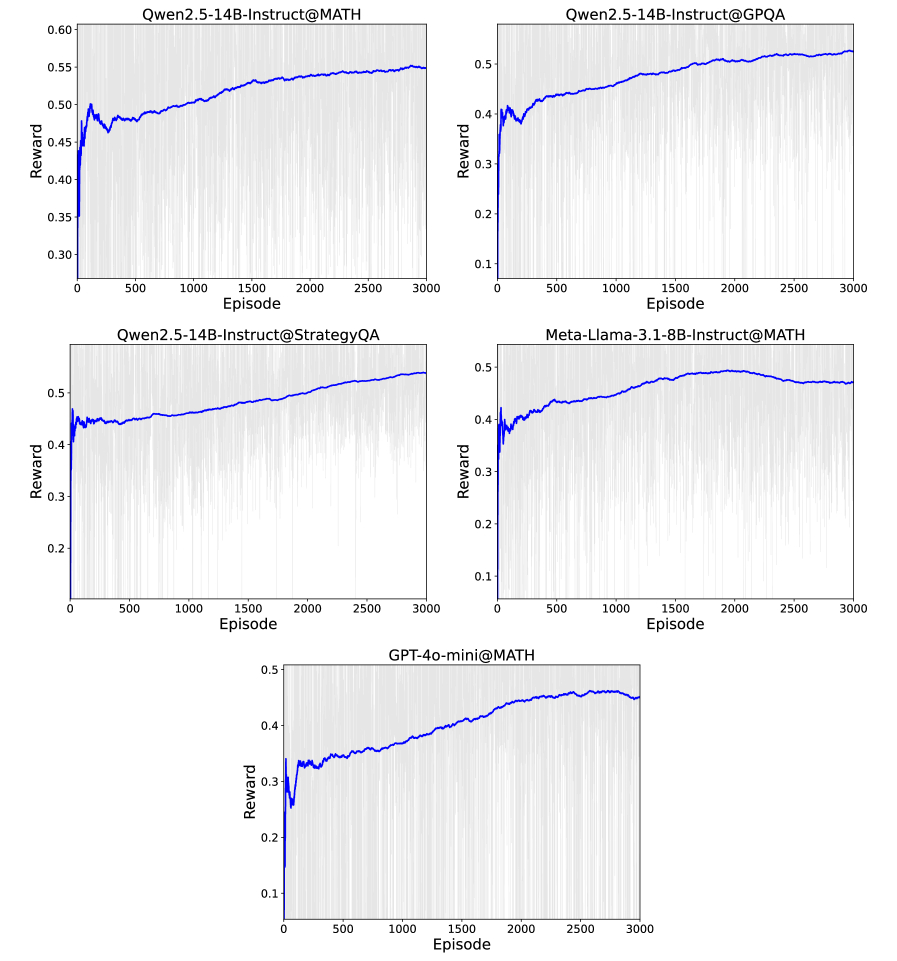
实验结果表明,RLoT在多个推理基准测试中取得了显著的性能提升。例如,在MATH数据集上,RLoT使多个LLM(GPT、Llama、Qwen和DeepSeek)的性能提升高达13.4%。更重要的是,RLoT使用一个只有不到3K参数的RL导航器,就能使sub-10B的LLM与100B规模的LLM相媲美。此外,实验还证明了RL导航器具有很强的可迁移性,在一个LLM-任务对上训练的模型可以有效地推广到未见过的LLM和任务。
🎯 应用场景
RLoT具有广泛的应用前景,可以应用于各种需要复杂推理的场景,例如数学问题求解、科学推理、常识推理等。该方法可以显著提高LLM在这些任务中的性能,并降低对LLM规模的需求。此外,RLoT还可以应用于智能助手、对话系统等领域,提高系统的智能化水平和用户体验。未来,RLoT有望成为一种通用的LLM推理增强技术,推动人工智能的发展。
📄 摘要(原文)
Despite rapid advancements in large language models (LLMs), the token-level autoregressive nature constrains their complex reasoning capabilities. To enhance LLM reasoning, inference-time techniques, including Chain/Tree/Graph-of-Thought(s), successfully improve the performance, as they are fairly cost-effective by guiding reasoning through sophisticated logical structures without modifying LLMs' parameters. However, these manually predefined, task-agnostic frameworks are applied uniformly across diverse tasks, lacking adaptability. To improve this, we propose RL-of-Thoughts (RLoT), where we train a lightweight navigator model with reinforcement learning (RL) to adaptively enhance LLM reasoning at inference time. Specifically, we design five basic logic blocks from the perspective of human cognition. During the reasoning process, the trained RL navigator dynamically selects the suitable logic blocks and combines them into task-specific logical structures according to problem characteristics. Experiments across multiple reasoning benchmarks (AIME, MATH, GPQA, etc.) with multiple LLMs (GPT, Llama, Qwen, and DeepSeek) illustrate that RLoT outperforms established inference-time techniques by up to 13.4%. Remarkably, with less than 3K parameters, our RL navigator is able to make sub-10B LLMs comparable to 100B-scale counterparts. Moreover, the RL navigator demonstrates strong transferability: a model trained on one specific LLM-task pair can effectively generalize to unseen LLMs and tasks. Our code is open-source at https://anonymous.4open.science/r/RL-LLM-Reasoning-1A30 for reproducibility.