Visual Instruction Bottleneck Tuning
作者: Changdae Oh, Jiatong Li, Shawn Im, Sharon Li
分类: cs.AI
发布日期: 2025-05-20 (更新: 2025-10-20)
备注: NeurIPS 2025
💡 一句话要点
提出Visual Instruction Bottleneck Tuning (Vittle),提升多模态大语言模型在分布偏移下的泛化性和鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 信息瓶颈 表征学习 分布偏移 泛化能力 鲁棒性 视觉指令调优
📋 核心要点
- 多模态大语言模型在分布偏移下性能显著下降,现有方法依赖大量数据或更大模型,成本高昂。
- Vittle方法基于信息瓶颈原理,学习最小充分视觉表征,增强模型在分布偏移下的鲁棒性。
- 实验证明,Vittle在多个数据集和任务上,显著提升了MLLM在分布偏移下的性能。
📝 摘要(中文)
多模态大语言模型(MLLM)虽然应用广泛,但在遇到分布偏移下的不熟悉查询时,性能会下降。现有的提升MLLM泛化能力的方法通常需要更多的指令数据或更大的高级模型架构,这会带来大量的人工或计算成本。本文从表征学习的角度,提出了一种替代方法来增强MLLM在分布偏移下的泛化性和鲁棒性。受到信息瓶颈(IB)原理的启发,我们推导了MLLM的IB的变分下界,并设计了一个实用的实现,即Visual Instruction Bottleneck Tuning (Vittle)。然后,我们通过揭示Vittle与MLLM的信息论鲁棒性度量之间的联系,为Vittle提供了理论依据。在包括30个偏移场景的45个数据集上,对多个MLLM在开放式和封闭式问答以及对象幻觉检测任务上的实证验证表明,Vittle通过追求学习最小充分表示,始终如一地提高了MLLM在偏移下的鲁棒性。
🔬 方法详解
问题定义:多模态大语言模型(MLLM)在面对与训练数据分布不同的新数据时,性能会显著下降,即存在泛化性问题。现有的提升泛化性的方法,例如增加训练数据或使用更大的模型,需要大量的人工标注或计算资源,成本很高。因此,如何在不显著增加成本的前提下,提升MLLM在分布偏移下的鲁棒性是一个关键问题。
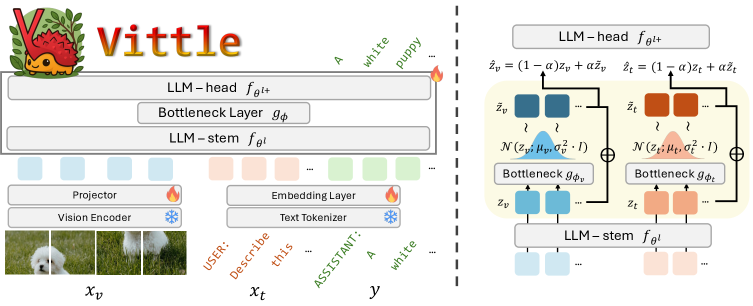
核心思路:论文的核心思路是借鉴信息瓶颈(Information Bottleneck, IB)原理,学习一种“最小充分”的视觉表征。这种表征既包含了完成任务所需的所有信息,又尽可能地去除了与任务无关的噪声和冗余信息。通过这种方式,模型可以更好地应对分布偏移,因为它更加关注本质特征,而不是受到表面因素的干扰。
技术框架:Vittle方法主要包含以下几个步骤:1) 推导MLLM的信息瓶颈的变分下界。2) 设计一个可行的优化目标,鼓励模型学习最小充分的视觉表征。3) 通过微调(tuning)的方式,在预训练的MLLM上应用该方法。具体来说,Vittle在视觉编码器和语言模型之间引入一个瓶颈层,该层强制模型学习压缩的视觉表征。
关键创新:Vittle的关键创新在于将信息瓶颈原理应用于多模态大语言模型的微调,并提出了一种有效的实现方式。与传统的微调方法不同,Vittle不仅关注提升模型在特定任务上的性能,更关注提升模型的泛化能力和鲁棒性。此外,论文还从理论上证明了Vittle与MLLM的信息论鲁棒性度量之间的联系,为该方法提供了理论支撑。
关键设计:Vittle的关键设计包括:1) 使用变分推断来近似信息瓶颈的优化目标。2) 设计一个合适的损失函数,鼓励模型学习最小充分的视觉表征。该损失函数通常包含两部分:一部分是重构损失,用于保证表征包含足够的信息;另一部分是正则化项,用于约束表征的复杂度。3) 通过实验选择合适的瓶颈层大小和正则化系数,以平衡性能和鲁棒性。
🖼️ 关键图片

📊 实验亮点
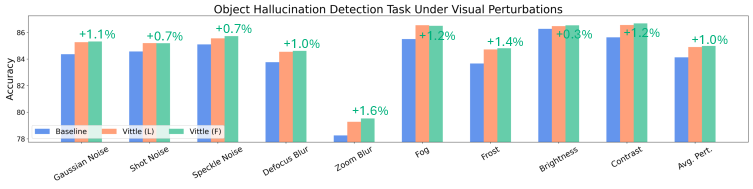
实验结果表明,Vittle在45个数据集(包括30个分布偏移场景)上,显著提升了多个MLLM的鲁棒性。例如,在对象幻觉检测任务上,Vittle能够有效减少模型产生的幻觉,提升模型的准确性。在开放式和封闭式问答任务上,Vittle也能够提升模型在分布偏移下的性能,使其更好地泛化到新的数据分布。
🎯 应用场景
Vittle方法可广泛应用于各种需要多模态理解和推理的场景,例如智能客服、自动驾驶、医疗诊断等。通过提升模型在分布偏移下的鲁棒性,可以使其在更加真实和复杂的环境中稳定可靠地工作。此外,该方法还可以用于提升模型的安全性,减少模型受到对抗攻击的风险。未来,Vittle可以进一步扩展到其他模态和任务,例如语音识别、自然语言处理等。
📄 摘要(原文)
Despite widespread adoption, multimodal large language models (MLLMs) suffer performance degradation when encountering unfamiliar queries under distribution shifts. Existing methods to improve MLLM generalization typically require either more instruction data or larger advanced model architectures, both of which incur non-trivial human labor or computational costs. In this work, we take an alternative approach to enhance the generalization and robustness of MLLMs under distribution shifts, from a representation learning perspective. Inspired by information bottleneck (IB) principle, we derive a variational lower bound of the IB for MLLMs and devise a practical implementation, Visual Instruction Bottleneck Tuning (Vittle). We then provide a theoretical justification of Vittle by revealing its connection to an information-theoretic robustness metric of MLLM. Empirical validation of multiple MLLMs on open-ended and closed-form question answering and object hallucination detection tasks over 45 datasets, including 30 shift scenarios, demonstrates that Vittle consistently improves the MLLM's robustness under shifts by pursuing the learning of a minimal sufficient representation.