DrugPilot: LLM-based Parameterized Reasoning Agent for Drug Discovery
作者: Kun Li, Zhennan Wu, Shoupeng Wang, Jia Wu, Shirui Pan, Wenbin Hu
分类: cs.AI, q-bio.BM
发布日期: 2025-05-20 (更新: 2025-07-28)
备注: 29 pages, 8 figures, 2 tables
💡 一句话要点
DrugPilot:基于LLM的参数化推理Agent,用于药物发现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 药物发现 大型语言模型 自主Agent 参数化推理 多模态数据 自动化 记忆池
📋 核心要点
- 现有LLM Agent在药物发现中面临大规模多模态数据处理、任务自动化程度低和领域特定工具支持不足等挑战。
- DrugPilot通过参数化推理架构和参数化记忆池,将异构数据转换为标准化表示,实现高效的多轮对话和科学决策。
- 实验结果表明,DrugPilot在药物发现任务中显著优于现有Agent,尤其在多工具和多轮交互场景下表现突出。
📝 摘要(中文)
本文提出DrugPilot,一个基于大型语言模型(LLM)的Agent系统,采用参数化推理架构,旨在实现药物发现中的端到端科学工作流程。DrugPilot通过将结构化工具使用与新型参数化记忆池相结合,支持多阶段研究过程。该记忆池将来自公共来源和用户自定义输入的异构数据转换为标准化表示,从而支持高效的多轮对话,减少数据交换过程中的信息损失,并增强复杂的科学决策能力。为了支持训练和基准测试,作者构建了一个涵盖八个核心药物发现任务的药物指令数据集。在Berkeley函数调用基准测试中,DrugPilot显著优于ReAct和LoT等最先进的Agent,在简单、多工具和多轮场景下的任务完成率分别达到98.0%、93.5%和64.0%。这些结果突显了DrugPilot作为一种通用Agent框架的潜力,适用于需要自动化、交互式和数据集成推理的计算科学领域。
🔬 方法详解
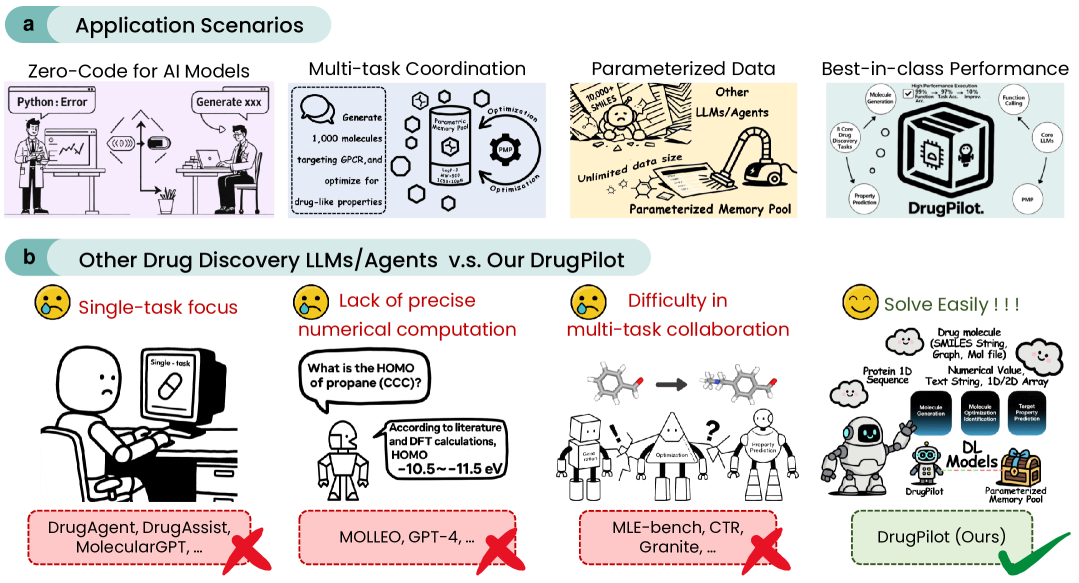
问题定义:药物发现流程复杂,涉及大量异构数据和领域特定工具。现有基于LLM的Agent在处理这些复杂任务时,存在数据处理能力不足、任务自动化程度低以及对领域特定工具支持有限等问题,导致难以实现端到端的自动化药物发现。
核心思路:DrugPilot的核心思路是构建一个参数化的推理Agent,通过参数化记忆池来统一处理异构数据,并结合结构化的工具使用,从而实现高效的多轮对话和复杂的科学决策。这种设计旨在克服现有Agent在数据处理、任务自动化和工具集成方面的局限性。
技术框架:DrugPilot的整体架构包含以下几个主要模块:1) LLM推理引擎,负责根据用户指令和上下文进行推理和决策;2) 参数化记忆池,用于存储和管理来自不同来源的异构数据,并将其转换为统一的表示形式;3) 结构化工具使用模块,用于调用和执行领域特定的工具;4) 任务执行模块,负责执行LLM生成的指令和调用工具的结果。整个流程通过多轮对话的方式进行交互,直到完成最终的药物发现任务。
关键创新:DrugPilot的关键创新在于其参数化记忆池的设计。传统的记忆机制难以有效处理药物发现中涉及的各种异构数据,例如分子结构、生物活性数据、文献信息等。DrugPilot通过将这些数据转换为标准化的参数化表示,使得LLM能够更有效地利用这些信息进行推理和决策。此外,DrugPilot还通过结构化工具使用模块,实现了对领域特定工具的有效集成。
关键设计:参数化记忆池的具体实现细节未知,但可以推测其可能涉及对不同类型的数据进行编码和嵌入,并使用参数化的方式来表示这些嵌入。此外,DrugPilot可能还采用了某种形式的注意力机制,以便LLM能够根据当前的任务和上下文,选择性地关注记忆池中的相关信息。具体的损失函数和网络结构等技术细节在论文中未详细描述。
🖼️ 关键图片


📊 实验亮点
DrugPilot在Berkeley函数调用基准测试中表现出色,显著优于现有Agent。在简单场景下,任务完成率达到98.0%;在多工具场景下,任务完成率达到93.5%;在多轮场景下,任务完成率达到64.0%。这些结果表明,DrugPilot在处理复杂药物发现任务方面具有显著优势。
🎯 应用场景
DrugPilot有望应用于药物发现的各个阶段,包括靶点发现、先导化合物筛选、药物优化和临床试验设计等。通过自动化和智能化药物发现流程,DrugPilot可以显著缩短药物研发周期,降低研发成本,并提高药物研发的成功率。此外,该框架还可以扩展到其他计算科学领域,例如材料科学和化学工程等。
📄 摘要(原文)
Large language models (LLMs) integrated with autonomous agents hold significant potential for advancing scientific discovery through automated reasoning and task execution. However, applying LLM agents to drug discovery is still constrained by challenges such as large-scale multimodal data processing, limited task automation, and poor support for domain-specific tools. To overcome these limitations, we introduce DrugPilot, a LLM-based agent system with a parameterized reasoning architecture designed for end-to-end scientific workflows in drug discovery. DrugPilot enables multi-stage research processes by integrating structured tool use with a novel parameterized memory pool. The memory pool converts heterogeneous data from both public sources and user-defined inputs into standardized representations. This design supports efficient multi-turn dialogue, reduces information loss during data exchange, and enhances complex scientific decision-making. To support training and benchmarking, we construct a drug instruction dataset covering eight core drug discovery tasks. Under the Berkeley function-calling benchmark, DrugPilot significantly outperforms state-of-the-art agents such as ReAct and LoT, achieving task completion rates of 98.0%, 93.5%, and 64.0% for simple, multi-tool, and multi-turn scenarios, respectively. These results highlight DrugPilot's potential as a versatile agent framework for computational science domains requiring automated, interactive, and data-integrated reasoning.