Causal Head Gating: A Framework for Interpreting Roles of Attention Heads in Transformers
作者: Andrew Nam, Henry Conklin, Yukang Yang, Thomas Griffiths, Jonathan Cohen, Sarah-Jane Leslie
分类: cs.AI
发布日期: 2025-05-19 (更新: 2025-10-23)
备注: 10 pages, 5 figures, 2 tables. The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS 2025)
💡 一句话要点
提出因果头门控(CHG)框架,用于Transformer模型中注意力头的功能角色解释。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 注意力头解释 因果推断 Transformer模型 大型语言模型 机械可解释性
📋 核心要点
- 现有机械可解释性方法依赖于假设驱动,需要特定prompt或标签,通用性不足。
- CHG通过学习注意力头上的软门控,并根据其对任务性能的因果影响进行分类。
- 实验表明CHG能有效识别LLM中任务相关的子电路,并揭示指令遵循和上下文学习的机制。
📝 摘要(中文)
本文提出了一种可扩展的方法,即因果头门控(CHG),用于解释Transformer模型中注意力头的功能角色。CHG学习注意力头上的软门控,并根据它们对任务性能的影响,将它们分配到因果分类中——促进性的、干扰性的或不相关的。与机械可解释性中先前的、假设驱动的且需要提示模板或目标标签的方法不同,CHG直接应用于任何使用标准下一个token预测的数据集。我们在Llama 3模型家族中的多个大型语言模型(LLM)和各种任务(包括语法、常识和数学推理)中评估了CHG,并表明CHG分数产生了因果而非仅仅是相关的见解,这通过消融和因果中介分析得到了验证。我们还介绍了对比CHG,这是一种变体,可以隔离特定任务组件的子电路。我们的研究结果表明,LLM包含多个稀疏的、任务充分的子电路,单个头的角色取决于与其他头的交互(低模块化),并且指令遵循和上下文学习依赖于可分离的机制。
🔬 方法详解
问题定义:论文旨在解决Transformer模型中注意力头功能角色难以解释的问题。现有方法通常依赖于人工设计的prompt或标签,缺乏通用性和自动化程度,难以应用于大规模语言模型。此外,现有方法往往只能发现相关性,而无法揭示因果关系。
核心思路:论文的核心思路是通过学习注意力头上的软门控,并根据这些门控对模型性能的因果影响来判断注意力头的功能角色。如果一个注意力头被门控关闭后,模型性能显著下降,则认为该注意力头是“促进性的”;如果关闭后性能提升,则认为是“干扰性的”;如果关闭后性能没有明显变化,则认为是“不相关的”。
技术框架:CHG框架主要包含以下几个步骤:1) 使用标准下一个token预测任务训练Transformer模型;2) 在每个注意力头上添加一个可学习的软门控;3) 通过优化一个目标函数来学习这些门控,该目标函数鼓励门控的稀疏性,并惩罚关闭“促进性”注意力头导致的性能下降;4) 根据学习到的门控值,将注意力头分为“促进性的”、“干扰性的”或“不相关的”三类。
关键创新:CHG的关键创新在于它能够以一种数据驱动的方式,自动地发现注意力头的功能角色,而无需人工设计prompt或标签。此外,CHG通过分析门控对模型性能的因果影响,能够揭示注意力头之间的因果关系,而不仅仅是相关性。对比CHG进一步能够隔离特定任务组件的子电路。
关键设计:CHG使用sigmoid函数来实现软门控,门控的输出值在0到1之间。目标函数包含两部分:一部分是标准的下一个token预测损失函数,另一部分是一个正则化项,用于鼓励门控的稀疏性。正则化项通常采用L1正则化或L0正则化的近似。论文还使用了因果中介分析来验证CHG的因果推断能力。对比CHG通过对比不同任务场景下的CHG结果,来区分不同任务组件所依赖的子电路。
🖼️ 关键图片

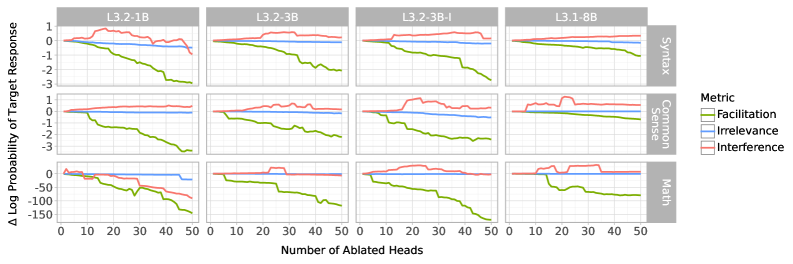
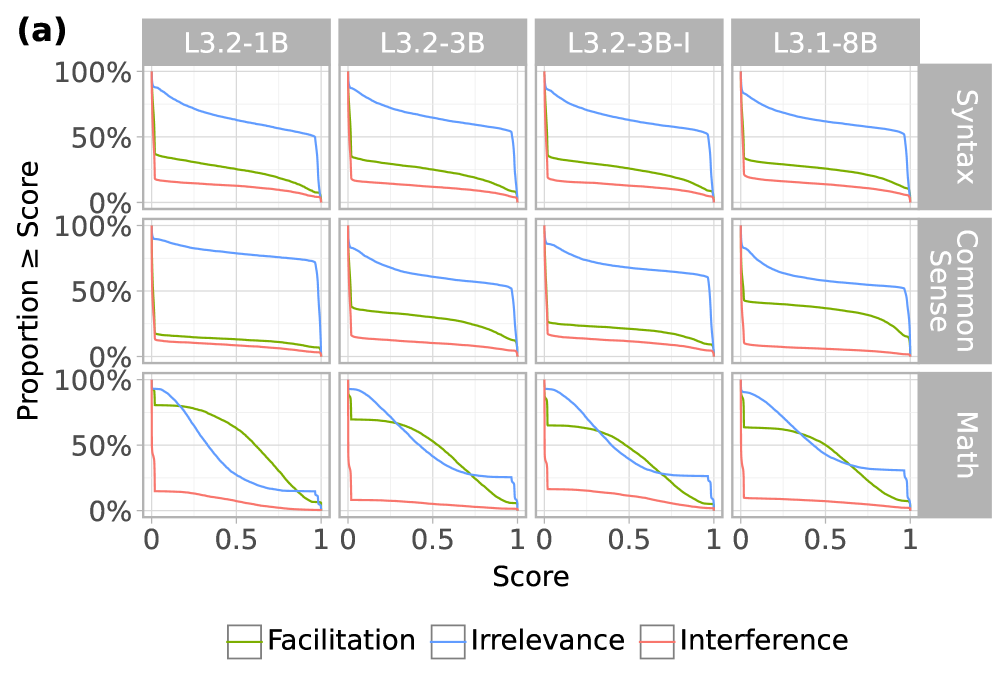
📊 实验亮点
在Llama 3模型家族的多个LLM上,CHG在语法、常识和数学推理等任务上进行了评估。实验结果表明,CHG能够有效地识别出对任务性能有重要影响的注意力头,并且这些注意力头的角色取决于与其他头的交互。通过消融实验和因果中介分析,验证了CHG的因果推断能力。对比CHG能够有效隔离特定任务组件的子电路。
🎯 应用场景
CHG可用于分析和理解大型语言模型的内部工作机制,例如识别哪些注意力头负责处理语法、常识或数学推理等任务。这有助于改进模型设计,例如通过选择性地保留或修改某些注意力头来提高模型性能或减少计算成本。此外,CHG还可以用于诊断模型的潜在问题,例如识别导致模型产生错误或偏见的注意力头。
📄 摘要(原文)
We present causal head gating (CHG), a scalable method for interpreting the functional roles of attention heads in transformer models. CHG learns soft gates over heads and assigns them a causal taxonomy - facilitating, interfering, or irrelevant - based on their impact on task performance. Unlike prior approaches in mechanistic interpretability, which are hypothesis-driven and require prompt templates or target labels, CHG applies directly to any dataset using standard next-token prediction. We evaluate CHG across multiple large language models (LLMs) in the Llama 3 model family and diverse tasks, including syntax, commonsense, and mathematical reasoning, and show that CHG scores yield causal, not merely correlational, insight validated via ablation and causal mediation analyses. We also introduce contrastive CHG, a variant that isolates sub-circuits for specific task components. Our findings reveal that LLMs contain multiple sparse task-sufficient sub-circuits, that individual head roles depend on interactions with others (low modularity), and that instruction following and in-context learning rely on separable mechanisms.