Multi-Modal Multi-Task (M3T) Federated Foundation Models for Embodied AI: Potentials and Challenges for Edge Integration
作者: Kasra Borazjani, Payam Abdisarabshali, Fardis Nadimi, Naji Khosravan, Minghui Liwang, Xianbin Wang, Yiguang Hong, Seyyedali Hosseinalipour
分类: cs.AI, cs.RO
发布日期: 2025-05-16 (更新: 2025-09-05)
备注: Accepted for Publication in IEEE Internet of Things Magazine, 2025
💡 一句话要点
面向具身AI,提出多模态多任务联邦基础模型(M3T-FFM),解决边缘设备上的泛化与个性化难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身AI 多模态学习 联邦学习 基础模型 边缘计算
📋 核心要点
- 现有具身AI系统难以在资源受限和保护隐私的前提下,实现多模态信息的有效学习和用户偏好的持续适应。
- 提出多模态多任务联邦基础模型(M3T-FFM),结合M3T-FM的泛化能力和联邦学习的隐私保护分布式训练特性。
- 构建了EMBODY框架,用于评估M3T-FFM在具身AI生态系统中的部署,并进行了原型实现和性能评估。
📝 摘要(中文)
随着具身AI系统变得越来越具有多模态、个性化和交互性,它们必须有效地从不同的感官输入中学习,不断适应用户偏好,并在资源和隐私约束下安全运行。这些挑战暴露了对机器学习模型的迫切需求,这些模型能够在快速、感知上下文的适应的同时,平衡模型泛化和个性化。多模态多任务基础模型(M3T-FM)提供了一条跨任务和模态泛化的途径,而联邦学习(FL)则为分布式、保护隐私的模型更新和用户级模型个性化提供了基础设施。然而,当单独使用时,这些方法都无法满足现实世界具身AI环境的复杂和多样化的能力需求。本文提出了一种用于具身AI的多模态多任务联邦基础模型(M3T-FFM),这是一种新的范例,它将M3T-FM的优势与FL的保护隐私的分布式训练性质结合起来,从而在无线边缘实现智能系统。本文收集了M3T-FFM在具身AI生态系统中的关键部署维度,并提出了一个统一的框架,命名为“EMBODY”。最后,本文展示了M3T-FFM的原型实现,并评估了它们的能量和延迟性能。
🔬 方法详解
问题定义:具身AI系统需要在边缘设备上处理多模态数据,同时满足个性化需求和隐私保护。现有的多模态多任务模型和联邦学习方法单独使用时,无法同时满足泛化能力、个性化和隐私保护的要求,并且在资源受限的边缘设备上部署面临挑战。
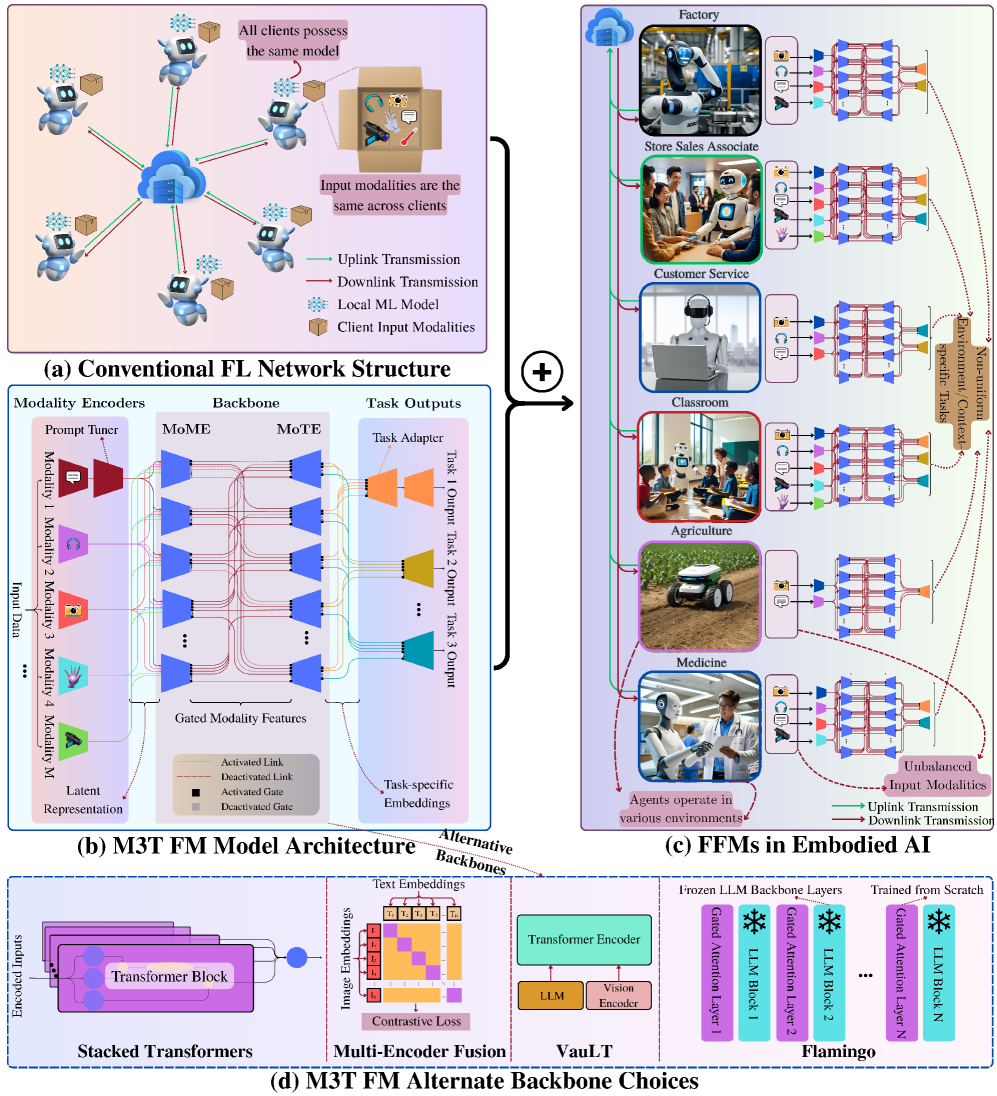
核心思路:论文的核心思路是将多模态多任务基础模型(M3T-FM)与联邦学习(FL)相结合,构建多模态多任务联邦基础模型(M3T-FFM)。M3T-FM负责跨任务和模态的泛化,FL负责在保护用户隐私的前提下进行分布式训练和用户级模型个性化。通过这种结合,M3T-FFM能够在边缘设备上实现高效、个性化和隐私保护的具身AI应用。
技术框架:M3T-FFM的整体框架包含以下几个主要模块:1) 多模态数据采集和预处理模块,负责从各种传感器获取数据并进行清洗和转换;2) M3T-FM模型,负责学习跨任务和模态的通用表示;3) 联邦学习模块,负责在多个边缘设备上进行分布式训练,并聚合模型更新;4) 个性化模块,负责根据用户偏好对模型进行微调;5) 部署和推理模块,负责将训练好的模型部署到边缘设备上进行推理。
关键创新:论文的关键创新在于提出了M3T-FFM这一新的模型架构,它将M3T-FM的泛化能力和联邦学习的隐私保护特性结合起来,从而能够在边缘设备上实现高效、个性化和隐私保护的具身AI应用。此外,论文还提出了EMBODY框架,用于评估M3T-FFM在具身AI生态系统中的部署,并识别了具体的挑战和研究方向。
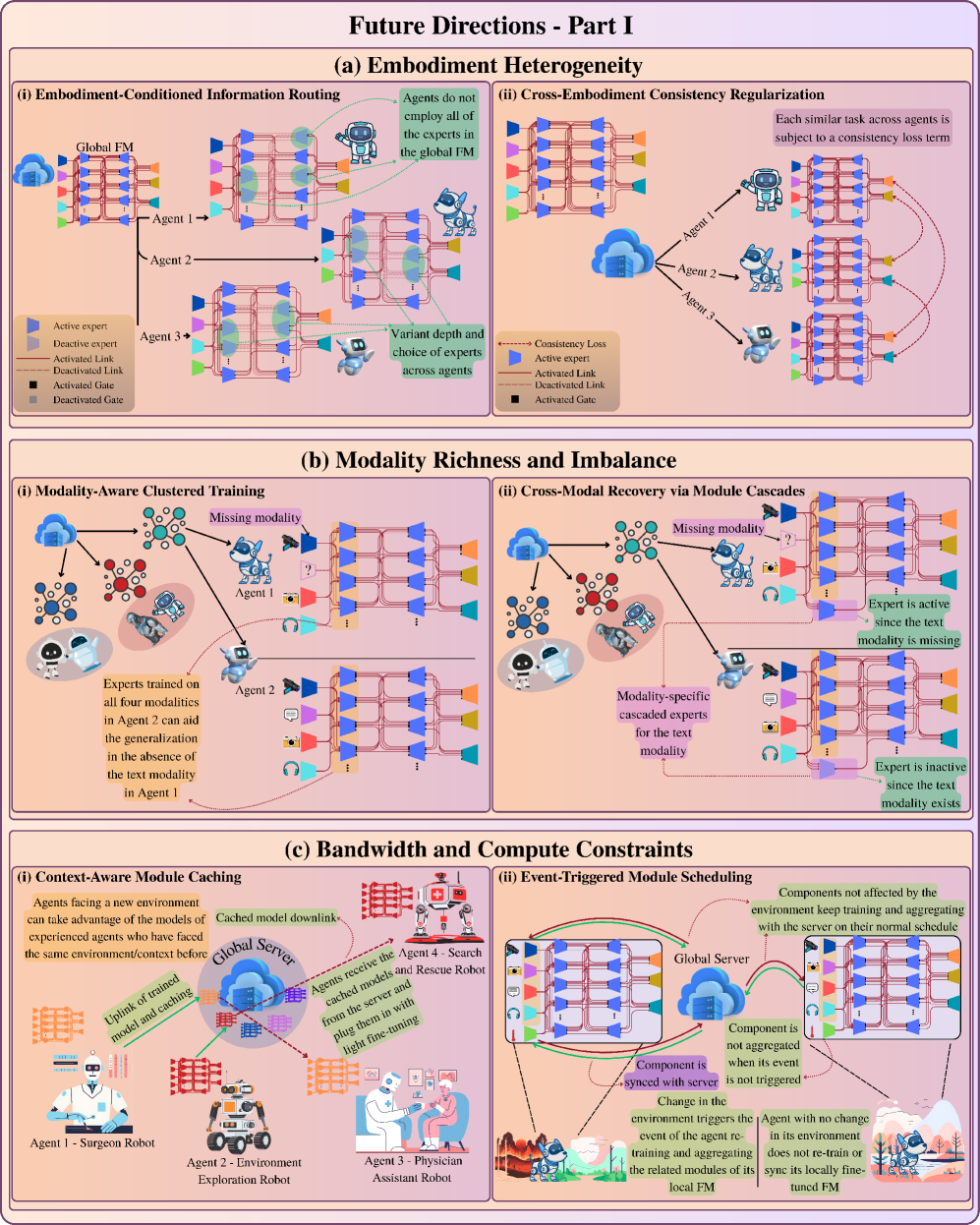
关键设计:EMBODY框架包含以下几个关键维度:1) Embodiment heterogeneity(具身异构性):考虑不同具身AI设备的硬件和软件差异;2) Modality richness and imbalance(模态丰富性和不平衡性):处理不同模态数据的多样性和数据量差异;3) Bandwidth and compute constraints(带宽和计算约束):在资源受限的边缘设备上进行模型训练和推理;4) On-device continual learning(设备端持续学习):实现模型的持续更新和适应;5) Distributed control and autonomy(分布式控制和自主性):实现多个具身AI设备的协同工作;6) Yielding safety, privacy, and personalization(安全、隐私和个性化):确保模型的安全性和用户隐私,并实现个性化服务。
🖼️ 关键图片
📊 实验亮点
论文展示了M3T-FFM的原型实现,并评估了其能量和延迟性能。实验结果表明,M3T-FFM能够在边缘设备上实现高效的推理,并且能够有效地降低能量消耗。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
M3T-FFM在具身AI领域具有广泛的应用前景,例如智能家居、辅助机器人、自动驾驶等。它可以帮助这些系统更好地理解环境、适应用户偏好,并提供更安全、更个性化的服务。未来,M3T-FFM有望成为边缘智能的重要组成部分,推动具身AI的普及和发展。
📄 摘要(原文)
As embodied AI systems become increasingly multi-modal, personalized, and interactive, they must learn effectively from diverse sensory inputs, adapt continually to user preferences, and operate safely under resource and privacy constraints. These challenges expose a pressing need for machine learning models capable of swift, context-aware adaptation while balancing model generalization and personalization. Here, two methods emerge as suitable candidates, each offering parts of these capabilities: multi-modal multi-task foundation models (M3T-FMs) provide a pathway toward generalization across tasks and modalities, whereas federated learning (FL) offers the infrastructure for distributed, privacy-preserving model updates and user-level model personalization. However, when used in isolation, each of these approaches falls short of meeting the complex and diverse capability requirements of real-world embodied AI environments. In this vision paper, we introduce multi-modal multi-task federated foundation models (M3T-FFMs) for embodied AI, a new paradigm that unifies the strengths of M3T-FMs with the privacy-preserving distributed training nature of FL, enabling intelligent systems at the wireless edge. We collect critical deployment dimensions of M3T-FFMs in embodied AI ecosystems under a unified framework, which we name "EMBODY": Embodiment heterogeneity, Modality richness and imbalance, Bandwidth and compute constraints, On-device continual learning, Distributed control and autonomy, and Yielding safety, privacy, and personalization. For each, we identify concrete challenges and envision actionable research directions. We also present an evaluation framework for deploying M3T-FFMs in embodied AI systems, along with the associated trade-offs. Finally, we present a prototype implementation of M3T-FFMs and evaluate their energy and latency performance.