Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures
作者: Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Huazuo Gao, Jiashi Li, Liyue Zhang, Panpan Huang, Shangyan Zhou, Shirong Ma, Wenfeng Liang, Ying He, Yuqing Wang, Yuxuan Liu, Y. X. Wei
分类: cs.DC, cs.AI, cs.AR
发布日期: 2025-05-14 (更新: 2025-12-23)
备注: This is the author's version of the work. It is posted here for your personal use. Not for redistribution. The definitive version appeared as part of the Industry Track in Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA '25)
期刊: Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA '25), June 2025
💡 一句话要点
DeepSeek-V3:硬件感知模型协同设计,突破大模型扩展瓶颈
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 硬件感知 模型协同设计 混合专家模型 低精度训练
📋 核心要点
- 现有硬件架构在大模型扩展时面临内存、计算效率和互连带宽的限制,阻碍了AI的发展。
- DeepSeek-V3采用硬件感知的模型协同设计,通过MLA、MoE、FP8混合精度训练和多平面网络拓扑等技术优化硬件利用率。
- DeepSeek-V3在2048个H800 GPU上成功训练,验证了硬件感知模型设计在提升训练效率和降低成本方面的有效性。
📝 摘要(中文)
大型语言模型(LLM)的快速扩展揭示了当前硬件架构的关键限制,包括内存容量、计算效率和互连带宽的约束。DeepSeek-V3在2048个NVIDIA H800 GPU上进行训练,展示了硬件感知的模型协同设计如何有效地应对这些挑战,从而实现具有成本效益的大规模训练和推理。本文深入分析了DeepSeek-V3/R1模型架构及其AI基础设施,重点介绍了关键创新,例如用于增强内存效率的多头潜在注意力(MLA)、用于优化计算-通信权衡的混合专家(MoE)架构、用于释放硬件全部潜力的FP8混合精度训练以及用于最小化集群级网络开销的多平面网络拓扑。基于DeepSeek-V3开发过程中遇到的硬件瓶颈,我们与学术界和工业界的同行就未来潜在的硬件方向进行了更广泛的讨论,包括精确的低精度计算单元、scale-up和scale-out的融合以及低延迟通信结构方面的创新。这些见解强调了硬件和模型协同设计在满足不断升级的AI工作负载需求方面的关键作用,为下一代AI系统的创新提供了实践蓝图。
🔬 方法详解
问题定义:现有的大型语言模型训练受到硬件资源的限制,具体表现为内存容量不足、计算效率低下以及节点间通信带宽受限。这些限制导致训练成本高昂,模型扩展困难。
核心思路:DeepSeek-V3的核心思路是进行硬件感知的模型协同设计,即在模型架构设计时充分考虑硬件的特性和限制,通过优化模型结构来更好地利用硬件资源,从而提升训练效率和降低成本。
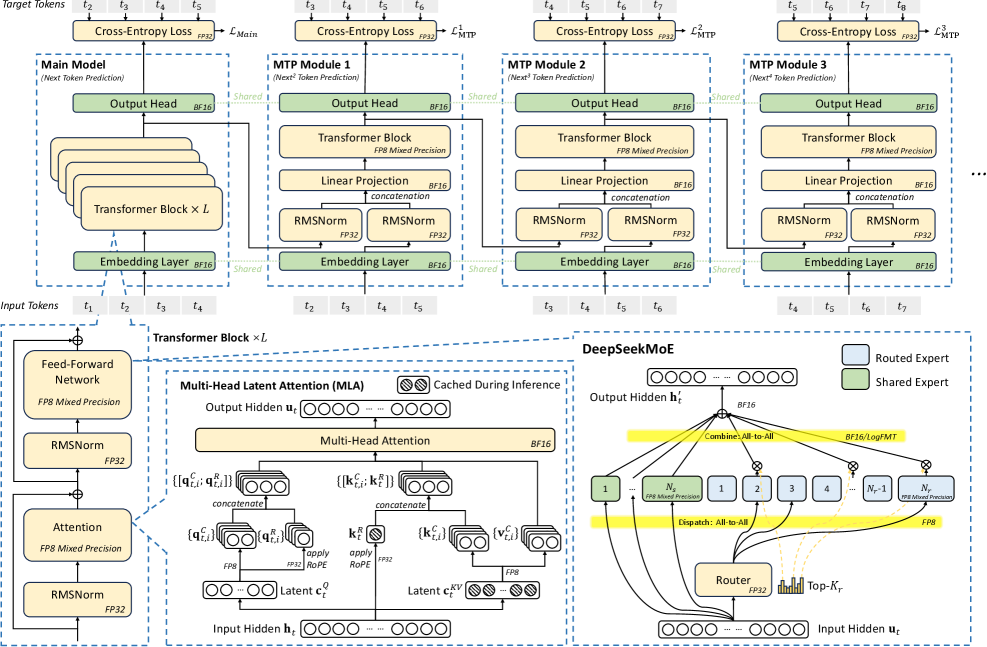
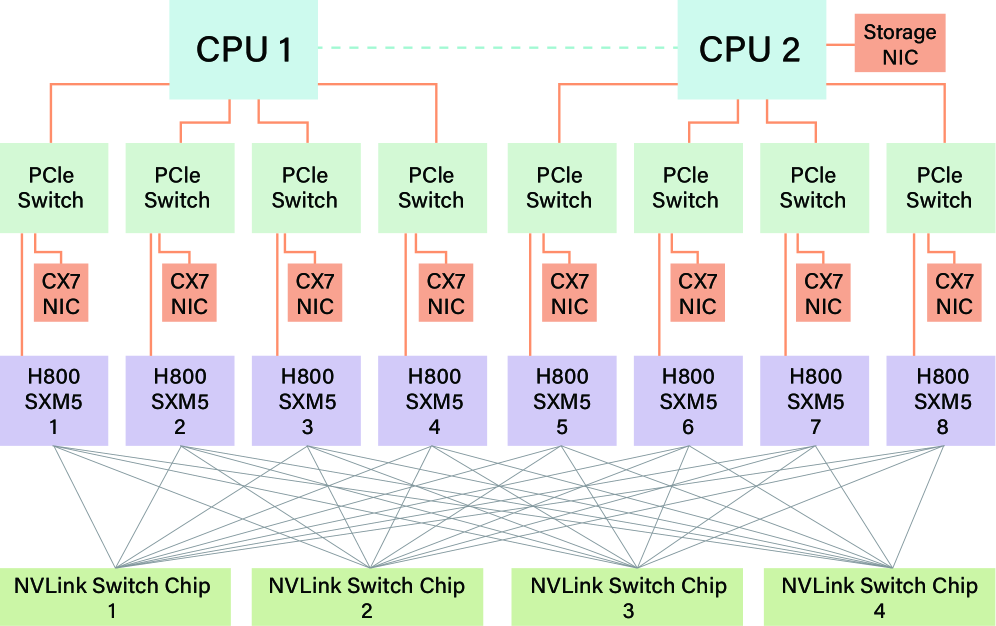
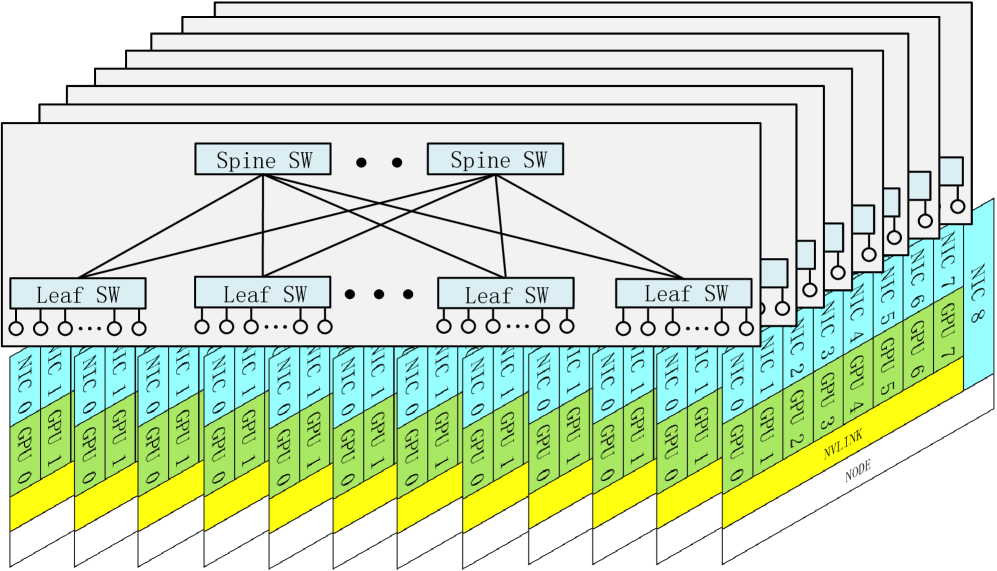
技术框架:DeepSeek-V3的技术框架主要包括以下几个方面:1) 模型架构优化:采用Multi-head Latent Attention (MLA)来减少内存占用,采用Mixture of Experts (MoE)架构来平衡计算和通信开销。2) 训练优化:使用FP8混合精度训练来充分利用硬件的计算能力。3) 网络拓扑优化:设计Multi-Plane Network Topology来减少集群级别的网络开销。
关键创新:DeepSeek-V3的关键创新在于其硬件感知的模型协同设计理念,以及在此理念下实现的多种优化技术。MLA通过减少attention计算中的冗余信息来降低内存需求。MoE通过将计算任务分配给不同的专家模型来减少通信开销。FP8混合精度训练则充分利用了H800 GPU的低精度计算能力。
关键设计:MLA的具体实现方式是使用latent representation来代替原始的token embedding进行attention计算,从而减少计算量和内存占用。MoE的具体实现方式是将输入token路由到不同的专家模型进行处理,每个专家模型只处理一部分token,从而减少了计算量和通信量。FP8混合精度训练的具体实现方式是在前向传播中使用FP8精度,在反向传播中使用FP16或FP32精度,从而在保证精度的同时提升计算效率。Multi-Plane Network Topology的具体实现方式是将GPU节点分成多个平面,每个平面内的节点之间使用高速网络连接,平面之间使用低速网络连接,从而减少了集群级别的网络拥塞。
🖼️ 关键图片
📊 实验亮点
DeepSeek-V3在2048个NVIDIA H800 GPU上成功完成训练,验证了硬件感知模型协同设计的有效性。MLA显著降低了内存占用,MoE有效平衡了计算和通信开销,FP8混合精度训练充分利用了硬件的计算能力,多平面网络拓扑降低了集群级别的网络开销。这些技术共同作用,使得DeepSeek-V3能够以更低的成本和更高的效率进行训练和推理。
🎯 应用场景
DeepSeek-V3的研究成果可应用于各种需要大规模语言模型支持的场景,如智能客服、机器翻译、文本生成、代码生成等。通过硬件感知的模型协同设计,可以降低大模型的训练和部署成本,加速AI技术在各行业的落地和应用,并为未来更大规模AI系统的设计提供参考。
📄 摘要(原文)
The rapid scaling of large language models (LLMs) has unveiled critical limitations in current hardware architectures, including constraints in memory capacity, computational efficiency, and interconnection bandwidth. DeepSeek-V3, trained on 2,048 NVIDIA H800 GPUs, demonstrates how hardware-aware model co-design can effectively address these challenges, enabling cost-efficient training and inference at scale. This paper presents an in-depth analysis of the DeepSeek-V3/R1 model architecture and its AI infrastructure, highlighting key innovations such as Multi-head Latent Attention (MLA) for enhanced memory efficiency, Mixture of Experts (MoE) architectures for optimized computation-communication trade-offs, FP8 mixed-precision training to unlock the full potential of hardware capabilities, and a Multi-Plane Network Topology to minimize cluster-level network overhead. Building on the hardware bottlenecks encountered during DeepSeek-V3's development, we engage in a broader discussion with academic and industry peers on potential future hardware directions, including precise low-precision computation units, scale-up and scale-out convergence, and innovations in low-latency communication fabrics. These insights underscore the critical role of hardware and model co-design in meeting the escalating demands of AI workloads, offering a practical blueprint for innovation in next-generation AI systems.