Reproducibility Study of "Cooperate or Collapse: Emergence of Sustainable Cooperation in a Society of LLM Agents"
作者: Pedro M. P. Curvo, Mara Dragomir, Salvador Torpes, Mohammadmahdi Rahimi
分类: cs.AI
发布日期: 2025-05-14
备注: 11 Tables, 9 Figures
💡 一句话要点
复现并扩展GovSim框架,评估LLM在资源共享场景下的合作决策能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 合作博弈 多智能体系统 资源共享 GovSim框架
📋 核心要点
- 现有方法难以有效评估LLM在复杂资源共享场景下的合作决策能力,缺乏通用性。
- 论文复现并扩展GovSim框架,通过模拟资源分配,评估LLM在不同场景下的合作行为。
- 实验验证了大型LLM在合作任务中的优越性,并探索了异构智能体环境下的行为影响。
📝 摘要(中文)
本研究评估并扩展了Piatti等人提出的GovSim框架,该框架旨在评估大型语言模型(LLM)在资源共享场景中的合作决策能力。通过复现关键实验,我们验证了关于大型模型(如GPT-4-turbo)相对于较小模型的性能的论断。我们还考察了普遍化原则的影响,结果表明,大型模型无论是否采用该原则,都能实现可持续合作,而较小模型在没有该原则的情况下则无法实现。此外,我们提供了多个扩展,以探索该框架在新环境中的适用性。我们评估了其他模型,如DeepSeek-V3和GPT-4o-mini,以测试合作行为是否能推广到不同的架构和模型大小。此外,我们引入了新的设置:创建了一个异构多智能体环境,研究了一个使用日语指令的场景,并探索了一个“逆环境”,其中智能体必须合作以减轻有害的资源分配。我们的结果证实,该基准可以应用于新的模型、场景和语言,为LLM在复杂合作任务中的适应性提供了有价值的见解。此外,涉及异构多智能体系统的实验表明,高性能模型可以影响低性能模型采用类似的行为。这一发现对其他基于智能体的应用具有重要意义,可能能够更有效地利用计算资源,并有助于开发更有效的合作AI系统。
🔬 方法详解
问题定义:论文旨在解决如何有效评估和提升大型语言模型(LLM)在复杂合作场景下的决策能力,特别是在资源共享问题中。现有方法,如传统博弈论模型,难以捕捉LLM的复杂行为和泛化能力。GovSim框架虽然提供了一个评估平台,但其适用性和泛化性仍需进一步验证。
核心思路:核心思路是通过构建一个模拟环境,让多个LLM智能体在资源有限的情况下进行互动,观察它们的合作或竞争行为。通过改变环境设置(例如,引入普遍化原则、异构智能体、不同语言指令),来测试LLM的鲁棒性和适应性。这种方法允许研究者在可控的环境中分析LLM的决策过程,并评估其在不同条件下的表现。
技术框架:GovSim框架的核心是一个资源共享模拟器,其中多个LLM智能体被赋予一定的初始资源,并需要通过合作或竞争来获取更多资源。模拟器可以配置不同的参数,例如资源总量、智能体数量、合作奖励等。研究人员通过观察智能体在模拟过程中的行为(例如,资源分配策略、合作频率),来评估LLM的合作能力。框架包含以下主要模块:环境配置模块、智能体交互模块、结果分析模块。
关键创新:本研究的关键创新在于对GovSim框架的复现和扩展,包括:1) 验证了大型LLM在资源共享任务中的优越性;2) 探索了普遍化原则对合作行为的影响;3) 引入了异构智能体环境,研究了高性能模型对低性能模型的影响;4) 测试了不同语言指令(日语)对LLM合作行为的影响;5) 设计了“逆环境”,考察了LLM在减轻有害资源分配方面的合作能力。这些扩展使得GovSim框架更加通用和实用。
关键设计:实验中使用了多种LLM模型,包括GPT-4-turbo、DeepSeek-V3和GPT-4o-mini。异构智能体环境通过混合使用不同能力的LLM来实现。日语指令场景通过将指令翻译成日语来创建。逆环境通过改变资源分配规则,使得合作能够减轻资源分配不均带来的负面影响。具体的参数设置(例如,资源总量、智能体数量)根据不同的实验场景进行调整。损失函数主要关注智能体的资源获取量和合作频率。
🖼️ 关键图片
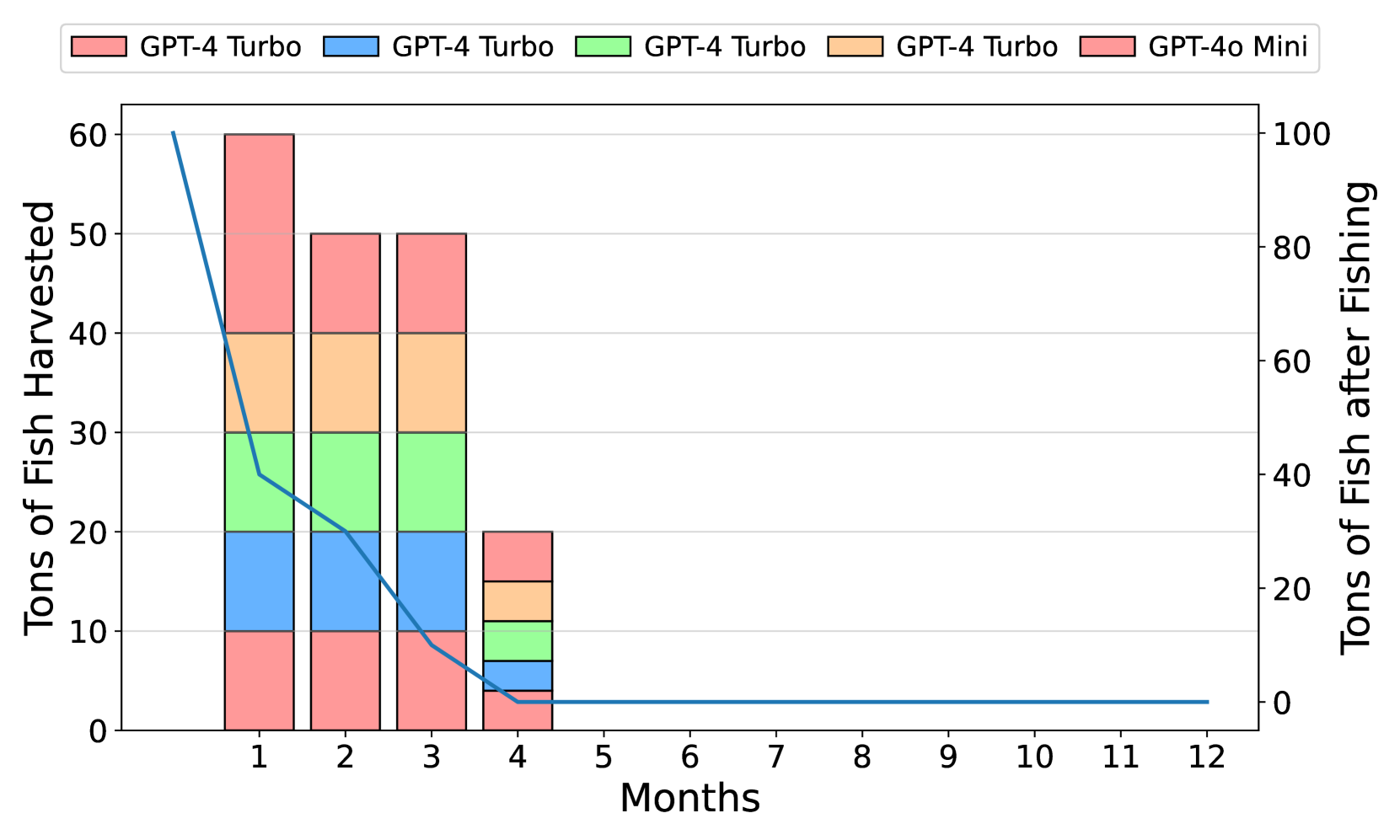
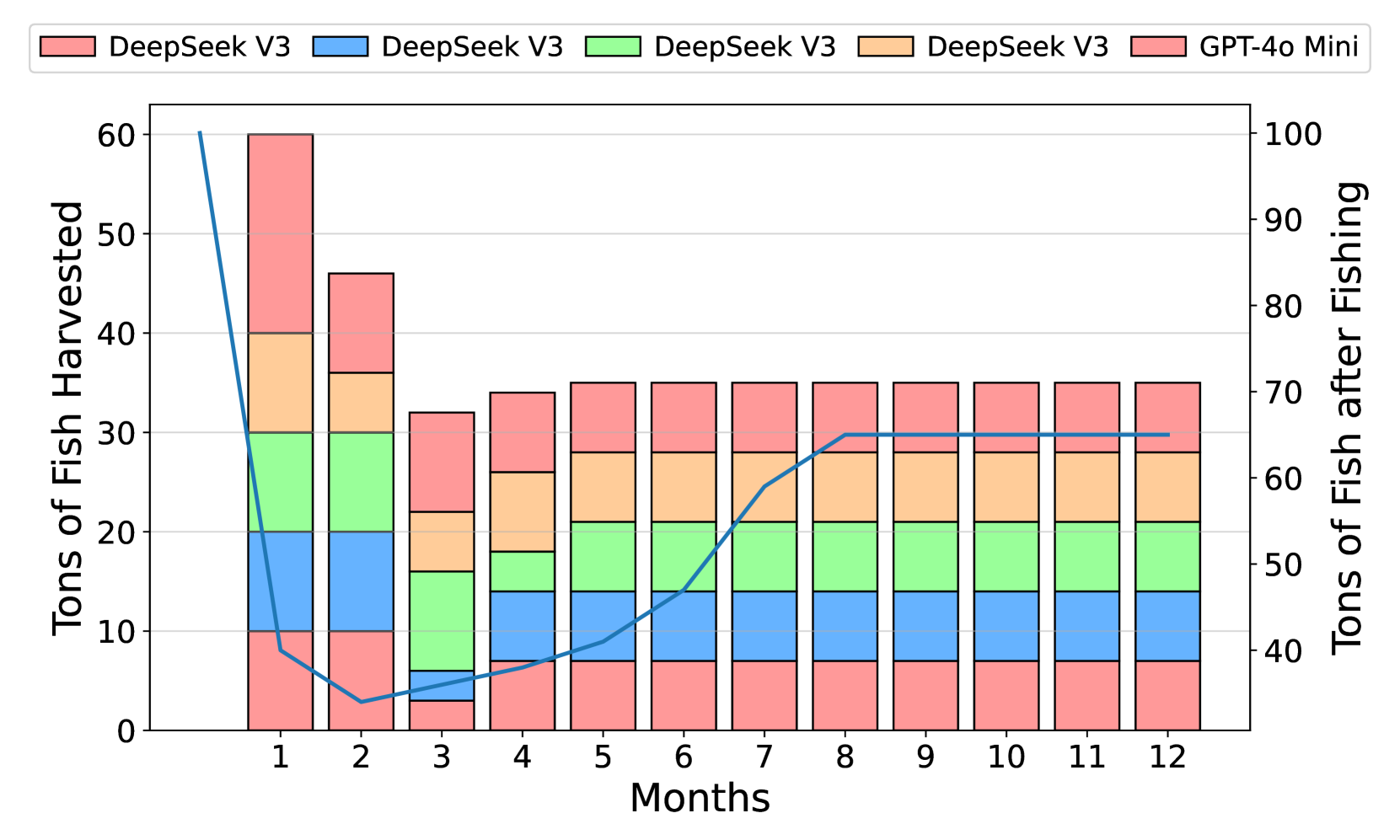
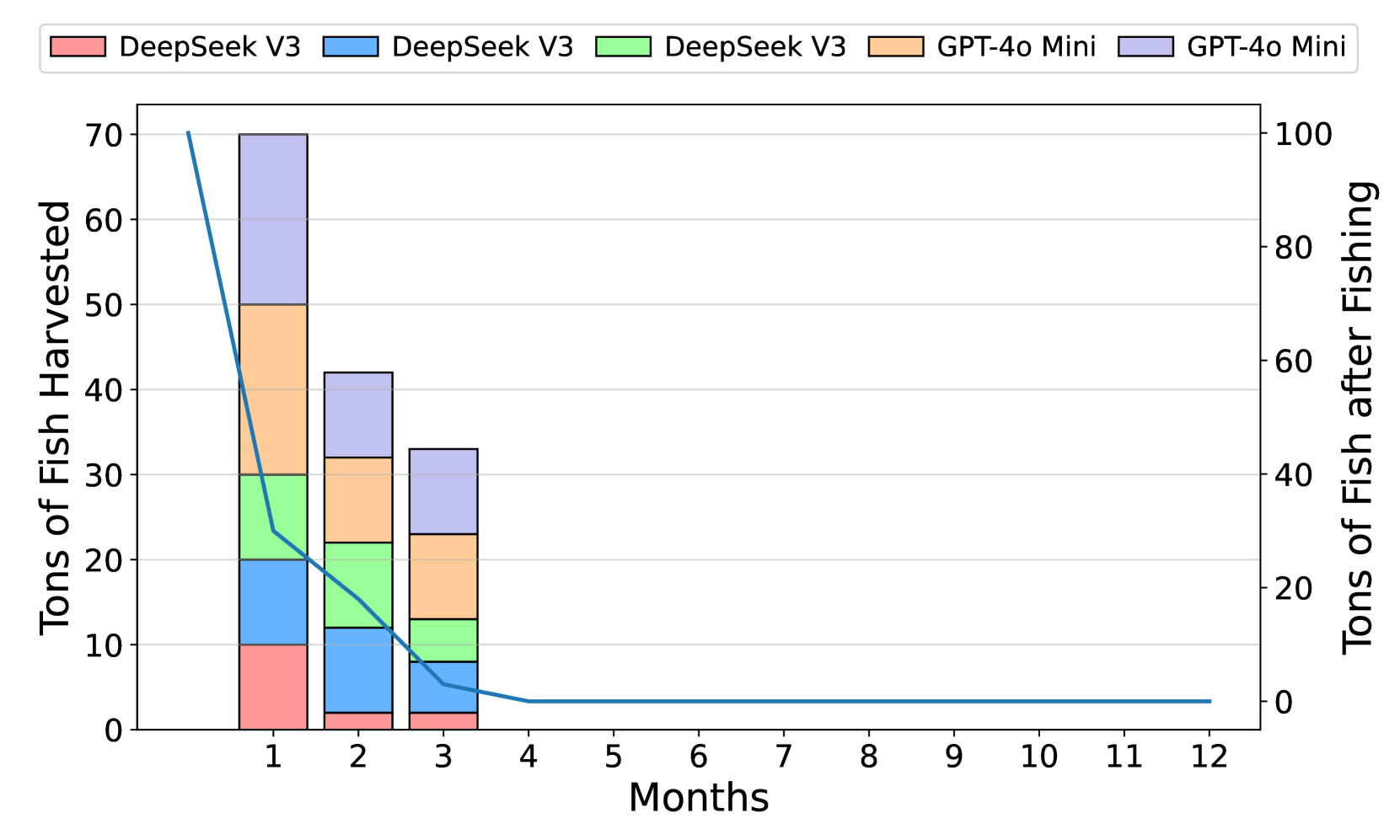
📊 实验亮点
实验结果表明,大型LLM(如GPT-4-turbo)在资源共享任务中表现优于小型模型。在异构智能体环境中,高性能模型能够影响低性能模型,使其采用更合作的行为。此外,GovSim框架成功应用于日语指令场景和“逆环境”,验证了其通用性和可扩展性。
🎯 应用场景
该研究成果可应用于开发更有效的多智能体系统,例如在自动驾驶、供应链管理、智能城市等领域,通过模拟不同智能体之间的互动,优化资源分配和协作策略。此外,该研究也有助于理解和提升LLM在复杂社会环境中的行为,促进负责任的AI发展。
📄 摘要(原文)
This study evaluates and extends the findings made by Piatti et al., who introduced GovSim, a simulation framework designed to assess the cooperative decision-making capabilities of large language models (LLMs) in resource-sharing scenarios. By replicating key experiments, we validate claims regarding the performance of large models, such as GPT-4-turbo, compared to smaller models. The impact of the universalization principle is also examined, with results showing that large models can achieve sustainable cooperation, with or without the principle, while smaller models fail without it. In addition, we provide multiple extensions to explore the applicability of the framework to new settings. We evaluate additional models, such as DeepSeek-V3 and GPT-4o-mini, to test whether cooperative behavior generalizes across different architectures and model sizes. Furthermore, we introduce new settings: we create a heterogeneous multi-agent environment, study a scenario using Japanese instructions, and explore an "inverse environment" where agents must cooperate to mitigate harmful resource distributions. Our results confirm that the benchmark can be applied to new models, scenarios, and languages, offering valuable insights into the adaptability of LLMs in complex cooperative tasks. Moreover, the experiment involving heterogeneous multi-agent systems demonstrates that high-performing models can influence lower-performing ones to adopt similar behaviors. This finding has significant implications for other agent-based applications, potentially enabling more efficient use of computational resources and contributing to the development of more effective cooperative AI systems.