Monte Carlo Beam Search for Actor-Critic Reinforcement Learning in Continuous Control
作者: Hazim Alzorgan, Abolfazl Razi
分类: cs.AI, cs.LG
发布日期: 2025-05-13
💡 一句话要点
提出基于蒙特卡洛束搜索的Actor-Critic强化学习方法,提升连续控制任务的探索效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 Actor-Critic 连续控制 蒙特卡洛束搜索 探索策略 TD3 机器人控制
📋 核心要点
- 传统Actor-Critic方法依赖噪声探索,易导致策略收敛至局部最优,探索效率较低。
- MCBS结合束搜索与蒙特卡洛rollout,在策略输出附近生成候选动作并评估,提升动作选择质量。
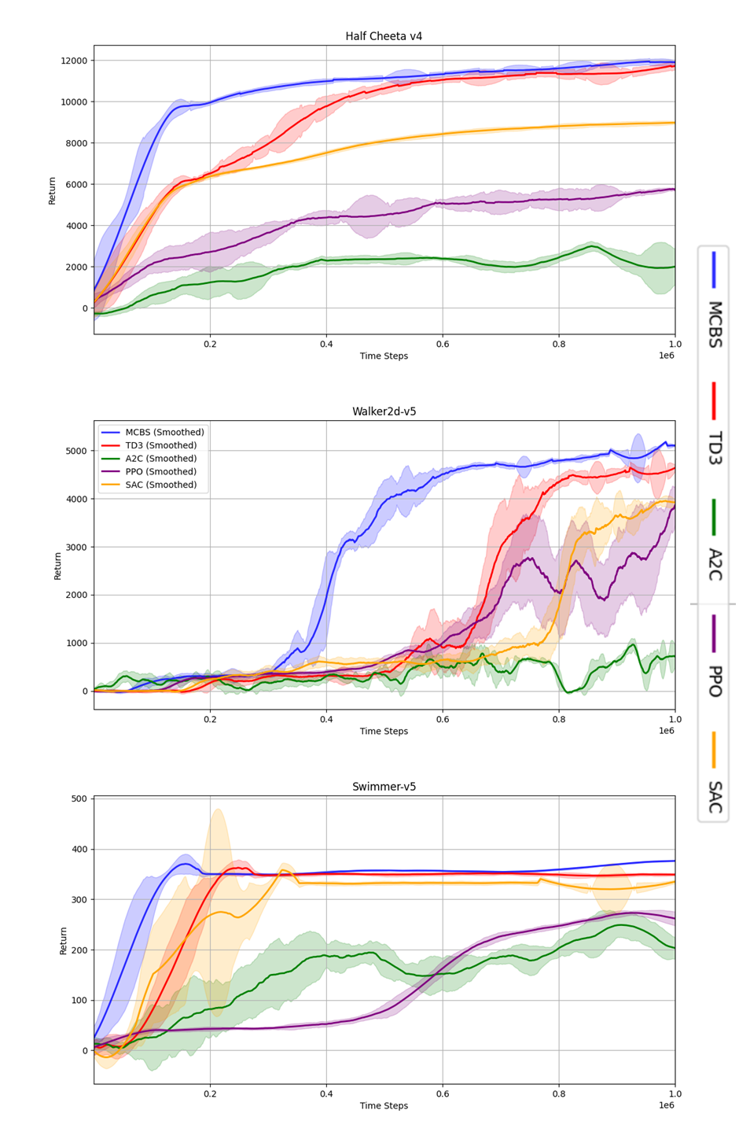
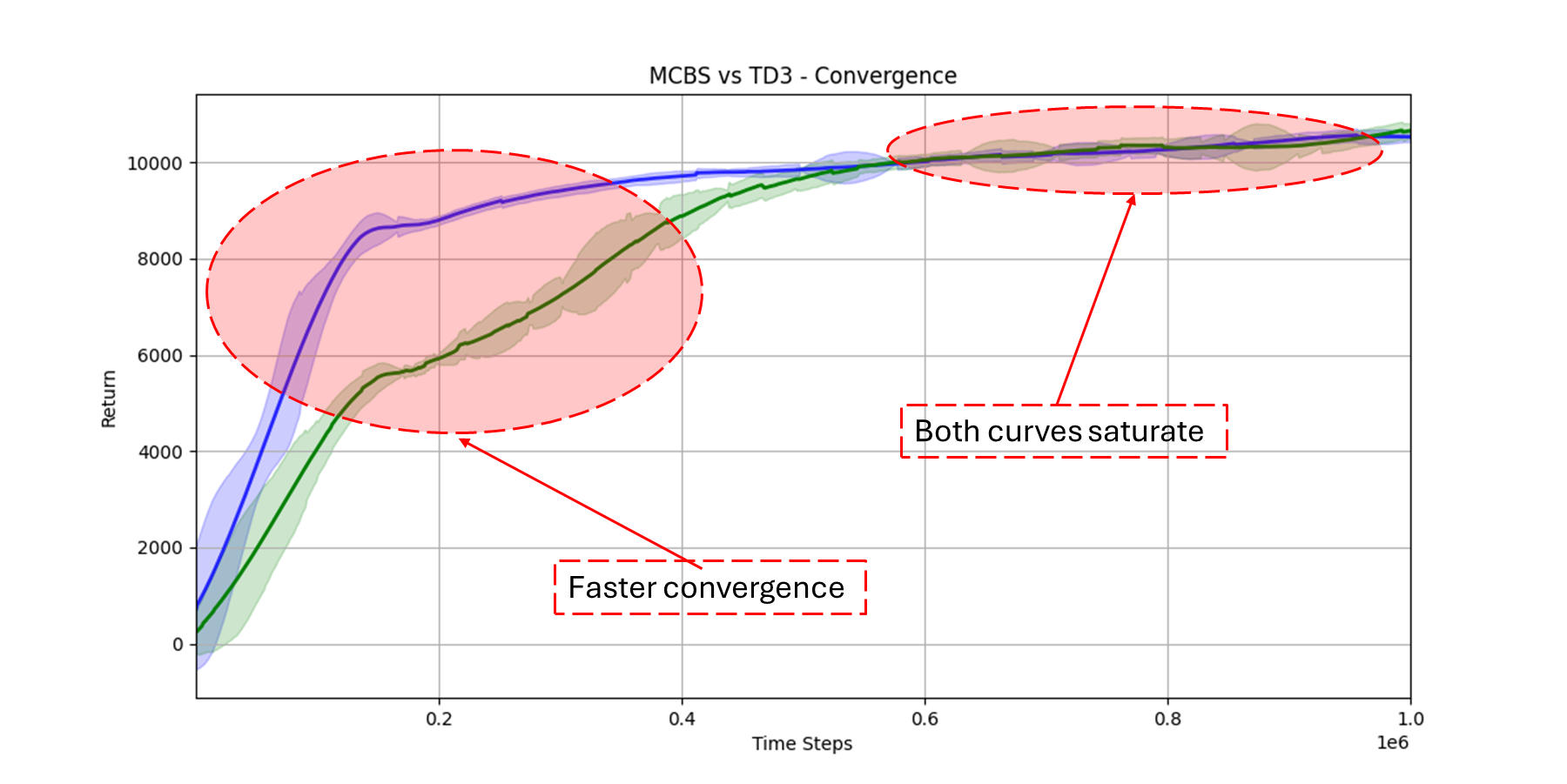
- 实验表明,MCBS在连续控制任务中,相较于TD3、SAC等方法,具有更高的样本效率和收敛速度。
📝 摘要(中文)
本研究提出了一种新的混合方法,即蒙特卡洛束搜索(MCBS),它将束搜索和蒙特卡洛rollout与TD3算法相结合,以改善探索和动作选择,解决TD3等Actor-Critic方法依赖于基于噪声的探索而导致的策略收敛欠佳问题。MCBS在策略输出附近生成多个候选动作,并通过短时程rollout评估它们,使智能体能够做出更明智的选择。我们在包括HalfCheetah-v4、Walker2d-v5和Swimmer-v5在内的各种连续控制基准上测试了MCBS,结果表明,与标准TD3以及SAC、PPO和A2C等其他基线方法相比,MCBS具有更高的样本效率和性能。我们的研究结果强调了MCBS通过结构化的前瞻搜索来增强策略学习的能力,同时确保了计算效率。此外,我们还详细分析了关键超参数,如束宽度和rollout深度,并探索了自适应策略来优化MCBS以适应复杂的控制任务。我们的方法在不同的环境中显示出比TD3、SAC、PPO和A2C更高的收敛速度。例如,我们大约在20万个时间步内实现了最大可实现奖励的90%,而第二好的方法需要40万个时间步。
🔬 方法详解
问题定义:论文旨在解决连续控制任务中,基于Actor-Critic的强化学习算法(如TD3)探索效率低下的问题。现有方法主要依赖于在动作空间中添加噪声进行探索,这种方式缺乏对未来状态的考虑,容易陷入局部最优,导致样本效率不高。
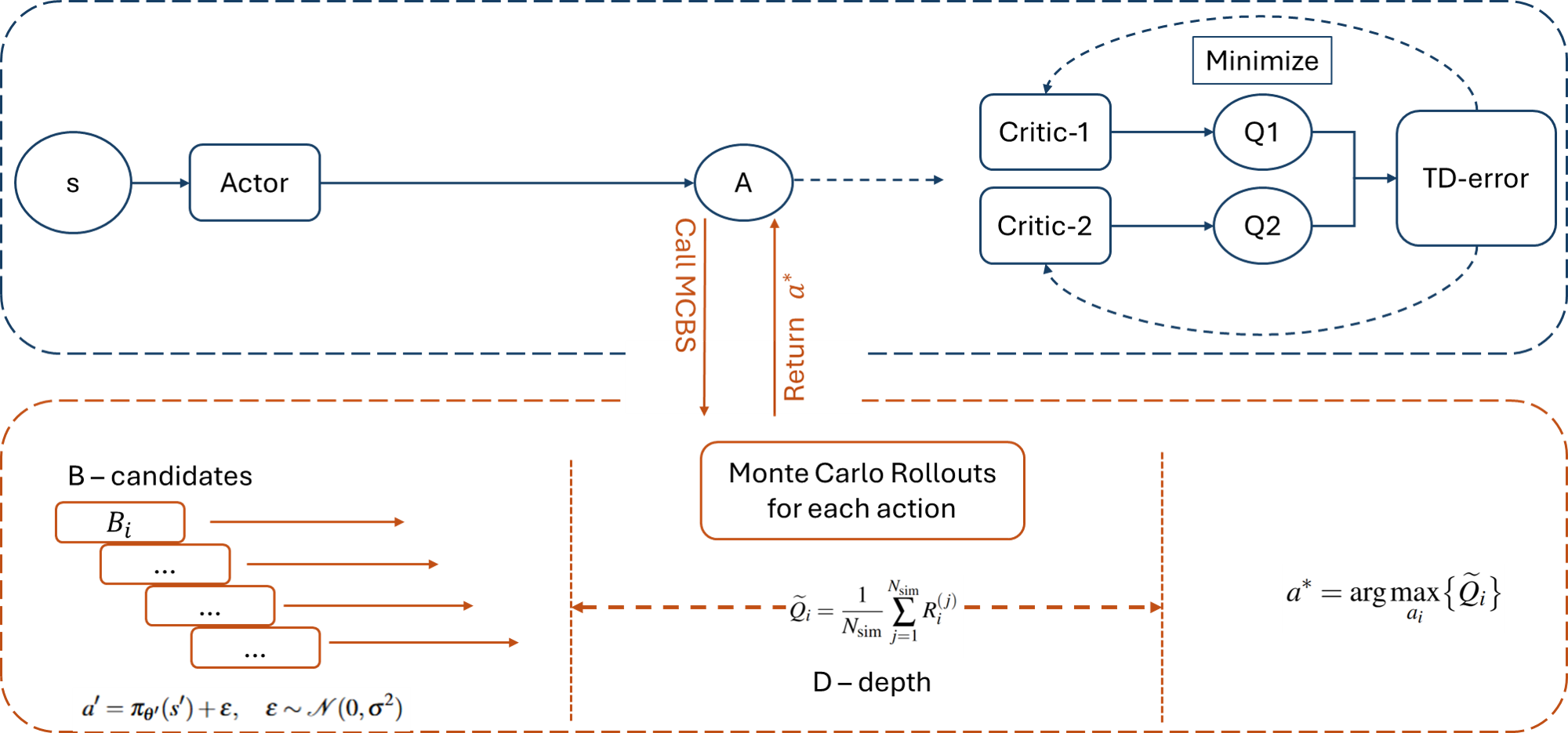
核心思路:论文的核心思路是利用蒙特卡洛束搜索(MCBS)来指导动作选择。MCBS在Actor网络输出的动作附近,通过束搜索生成多个候选动作,并使用蒙特卡洛rollout对这些候选动作进行短期评估,选择预期回报最高的动作。这样可以在一定程度上模拟“前瞻”过程,使智能体做出更明智的决策。
技术框架:MCBS-TD3算法的整体框架仍然是Actor-Critic结构,但Actor网络的动作选择部分被MCBS模块取代。具体流程如下:1) Actor网络输出一个初始动作;2) MCBS模块以该动作为中心,生成多个候选动作(束搜索);3) 对每个候选动作进行短时程的蒙特卡洛rollout,估计其未来回报;4) 选择具有最高估计回报的动作作为最终执行的动作;5) 使用TD3算法更新Actor和Critic网络。
关键创新:MCBS的关键创新在于将束搜索和蒙特卡洛rollout结合起来,用于指导连续动作空间的探索。与传统的噪声探索相比,MCBS能够更有效地探索有希望的动作区域,并利用短期预测来评估动作的优劣。这使得智能体能够更快地学习到更优的策略。
关键设计:MCBS的关键设计包括:1) 束宽度(beam width):决定了候选动作的数量,束宽度越大,探索范围越广,但计算成本也越高;2) Rollout深度(rollout depth):决定了蒙特卡洛rollout的步数,rollout深度越大,对动作的评估越准确,但计算成本也越高;3) 候选动作的生成方式:论文采用在Actor网络输出的动作附近添加高斯噪声的方式生成候选动作。这些参数需要根据具体任务进行调整,以平衡探索效率和计算成本。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MCBS-TD3在HalfCheetah-v4、Walker2d-v5和Swimmer-v5等连续控制基准上,显著优于标准TD3、SAC、PPO和A2C等基线方法。例如,在某些环境中,MCBS-TD3达到90%的最大可实现奖励所需的时间步数仅为TD3的一半。这表明MCBS能够显著提高样本效率和策略收敛速度。
🎯 应用场景
该研究成果可应用于各种需要连续控制的机器人任务,例如机器人运动规划、自动驾驶、无人机控制等。通过提高样本效率和策略收敛速度,可以降低训练成本,并使智能体能够更快地适应新的环境和任务。此外,MCBS的思路也可以推广到其他强化学习算法中,提升其探索能力。
📄 摘要(原文)
Actor-critic methods, like Twin Delayed Deep Deterministic Policy Gradient (TD3), depend on basic noise-based exploration, which can result in less than optimal policy convergence. In this study, we introduce Monte Carlo Beam Search (MCBS), a new hybrid method that combines beam search and Monte Carlo rollouts with TD3 to improve exploration and action selection. MCBS produces several candidate actions around the policy's output and assesses them through short-horizon rollouts, enabling the agent to make better-informed choices. We test MCBS across various continuous-control benchmarks, including HalfCheetah-v4, Walker2d-v5, and Swimmer-v5, showing enhanced sample efficiency and performance compared to standard TD3 and other baseline methods like SAC, PPO, and A2C. Our findings emphasize MCBS's capability to enhance policy learning through structured look-ahead search while ensuring computational efficiency. Additionally, we offer a detailed analysis of crucial hyperparameters, such as beam width and rollout depth, and explore adaptive strategies to optimize MCBS for complex control tasks. Our method shows a higher convergence rate across different environments compared to TD3, SAC, PPO, and A2C. For instance, we achieved 90% of the maximum achievable reward within around 200 thousand timesteps compared to 400 thousand timesteps for the second-best method.