Evaluating LLM Metrics Through Real-World Capabilities
作者: Justin K Miller, Wenjia Tang
分类: cs.AI
发布日期: 2025-05-13
备注: 14 pages main text, 5 pages references, 20 pages appendix; includes 3 figures and 4 tables
💡 一句话要点
评估LLM在真实世界能力:弥合基准测试与实际应用差距,Gemini表现突出
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型评估 真实世界应用 用户中心评估 基准测试分析 LLM能力 实用性指标 Gemini 性能比较
📋 核心要点
- 现有LLM基准测试侧重于代码生成或事实回忆,未能充分覆盖用户在写作辅助、摘要、引文格式化和风格反馈等方面的广泛需求。
- 该研究通过分析大规模用户数据,识别了LLM在真实世界中常用的六个核心能力,并以此为基础评估现有基准测试的覆盖范围。
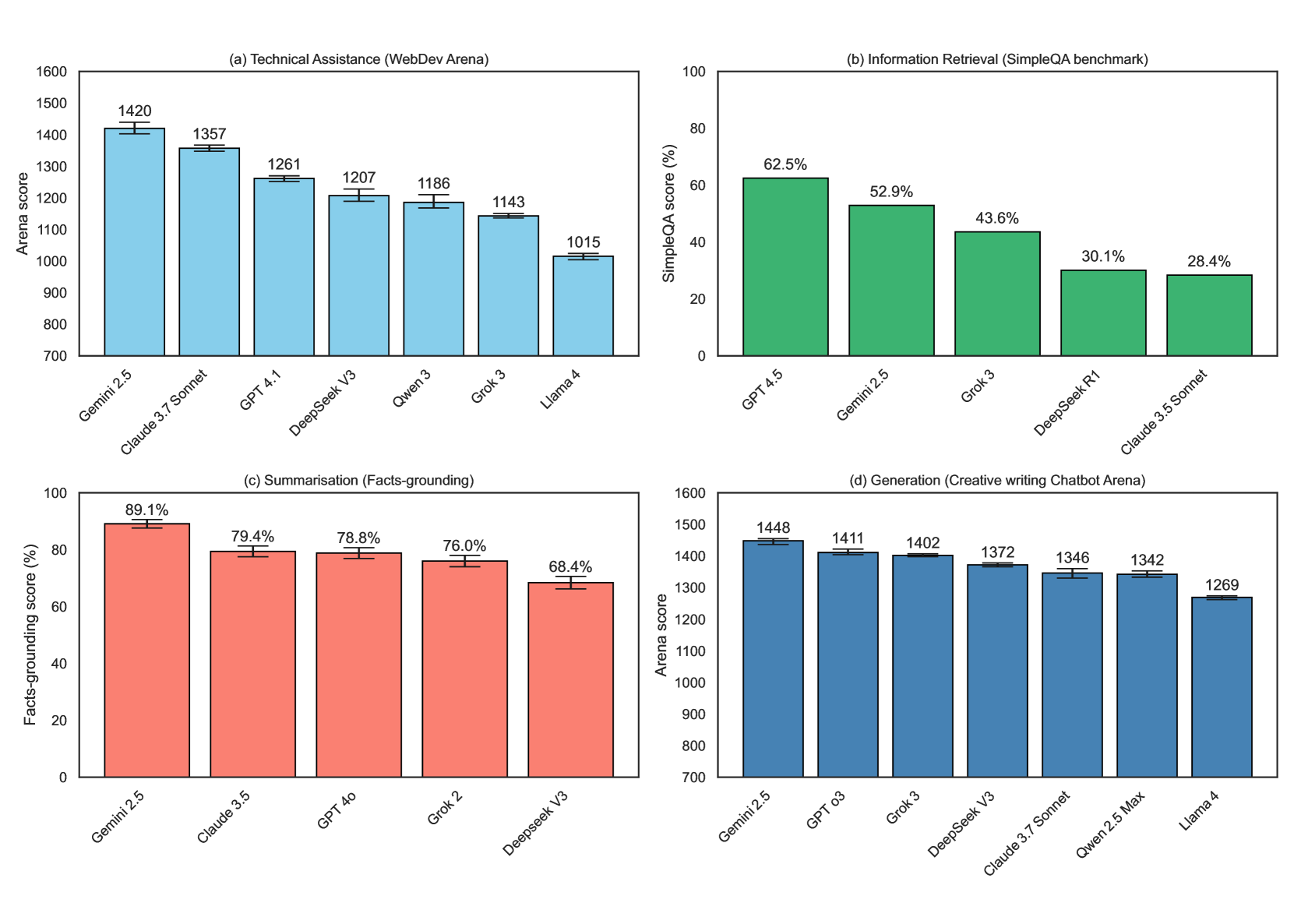
- 实验结果表明,谷歌Gemini在实用性指标上优于其他领先模型,验证了该研究提出的评估方法能够更准确地反映LLM的实际应用能力。
📝 摘要(中文)
随着生成式AI日益融入日常工作流程,评估其性能的方式应侧重于真实世界的应用,而非抽象的智能概念。本文着眼于实际效用,评估模型在日常任务中对用户的支持程度。通过分析大规模调查数据和使用日志,确定了人们常用大型语言模型(LLM)的六个核心能力:摘要、技术协助、工作审查、数据结构化、生成和信息检索。评估了现有基准测试对这些能力的覆盖程度,揭示了覆盖范围、效率测量和可解释性方面的显著差距。基于此分析,使用以人为本的标准来识别当前基准测试在多大程度上反映了基于五个实际标准的常见用法:连贯性、准确性、清晰性、相关性和效率。针对六种能力中的四种,确定了最符合真实世界任务的基准,并使用它们来比较领先的模型。研究发现,谷歌Gemini在这些以实用性为中心的指标上优于其他模型,包括OpenAI的GPT、xAI的Grok、Meta的LLaMA、Anthropic的Claude、DeepSeek和阿里巴巴的Qwen。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)评估基准通常侧重于通用智能的抽象概念,例如代码生成或事实回忆。然而,用户在日常工作流程中使用LLM的需求更加多样化,包括写作辅助、摘要、引文格式化和风格反馈等。现有基准测试未能充分覆盖这些真实世界的应用场景,导致评估结果与实际效用之间存在差距。
核心思路:该研究的核心思路是通过分析大规模的用户调查数据和使用日志,识别出用户在真实世界中使用LLM的六个核心能力。然后,基于这些核心能力,评估现有基准测试的覆盖范围和有效性,并选择或设计更符合实际应用场景的评估指标。这种以用户为中心的方法旨在弥合基准测试与实际应用之间的差距,从而更准确地评估LLM的实用性。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集与分析:收集大规模的用户调查数据和使用日志,分析用户使用LLM的模式和需求。2) 核心能力识别:基于数据分析结果,识别出用户在真实世界中使用LLM的六个核心能力,包括摘要、技术协助、工作审查、数据结构化、生成和信息检索。3) 基准测试评估:评估现有基准测试对这些核心能力的覆盖范围和有效性,识别差距和不足。4) 指标选择与模型比较:选择或设计更符合实际应用场景的评估指标,并使用这些指标来比较不同LLM的性能。
关键创新:该研究的关键创新在于其以用户为中心的评估方法。与传统的侧重于通用智能的评估方法不同,该研究从用户的实际需求出发,识别出LLM在真实世界中的核心能力,并以此为基础评估模型的性能。这种方法能够更准确地反映LLM的实用性,并为模型的改进提供更有针对性的指导。
关键设计:该研究的关键设计包括:1) 六个核心能力的定义:对摘要、技术协助、工作审查、数据结构化、生成和信息检索这六个核心能力进行了明确的定义,并给出了具体的评估标准。2) 以人为本的评估标准:使用了连贯性、准确性、清晰性、相关性和效率这五个以人为本的标准来评估基准测试的有效性。3) 模型选择与比较:选择了包括Google Gemini、OpenAI的GPT、xAI的Grok、Meta的LLaMA、Anthropic的Claude、DeepSeek和阿里巴巴的Qwen在内的多个领先模型进行比较。
🖼️ 关键图片
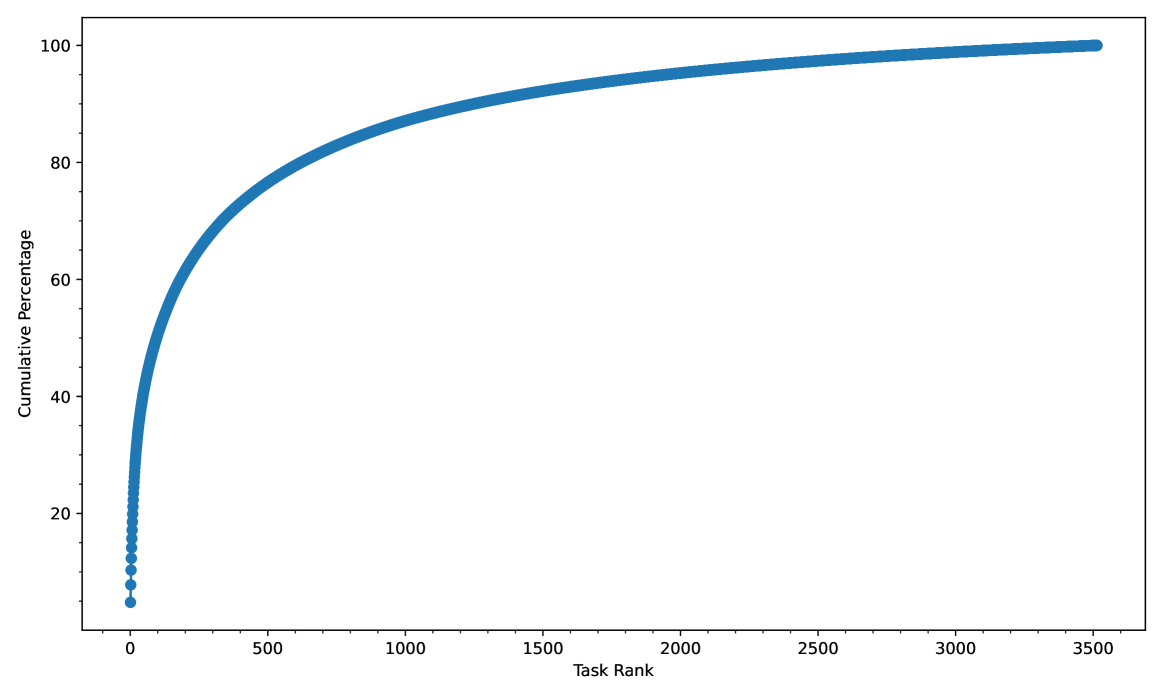

📊 实验亮点
实验结果表明,谷歌Gemini在以实用性为中心的指标上优于其他领先模型,包括OpenAI的GPT、xAI的Grok、Meta的LLaMA、Anthropic的Claude、DeepSeek和阿里巴巴的Qwen。这表明Gemini在真实世界的应用场景中具有更强的性能和实用性。具体的性能提升幅度未知,需要在论文中查找更详细的数据。
🎯 应用场景
该研究成果可应用于指导LLM的开发和评估,使其更符合用户的实际需求。通过更准确地评估LLM在真实世界中的能力,可以帮助开发者改进模型的设计,提高其在各种实际应用场景中的性能。此外,该研究提出的评估方法也可以用于指导用户选择最适合其需求的LLM,从而提高工作效率和质量。
📄 摘要(原文)
As generative AI becomes increasingly embedded in everyday workflows, it is important to evaluate its performance in ways that reflect real-world usage rather than abstract notions of intelligence. Unlike many existing benchmarks that assess general intelligence, our approach focuses on real-world utility, evaluating how well models support users in everyday tasks. While current benchmarks emphasize code generation or factual recall, users rely on AI for a much broader range of activities-from writing assistance and summarization to citation formatting and stylistic feedback. In this paper, we analyze large-scale survey data and usage logs to identify six core capabilities that represent how people commonly use Large Language Models (LLMs): Summarization, Technical Assistance, Reviewing Work, Data Structuring, Generation, and Information Retrieval. We then assess the extent to which existing benchmarks cover these capabilities, revealing significant gaps in coverage, efficiency measurement, and interpretability. Drawing on this analysis, we use human-centered criteria to identify gaps in how well current benchmarks reflect common usage that is grounded in five practical criteria: coherence, accuracy, clarity, relevance, and efficiency. For four of the six capabilities, we identify the benchmarks that best align with real-world tasks and use them to compare leading models. We find that Google Gemini outperforms other models-including OpenAI's GPT, xAI's Grok, Meta's LLaMA, Anthropic's Claude, DeepSeek, and Qwen from Alibaba-on these utility-focused metrics.