S-GRPO: Early Exit via Reinforcement Learning in Reasoning Models
作者: Muzhi Dai, Chenxu Yang, Qingyi Si
分类: cs.AI, cs.LG
发布日期: 2025-05-12 (更新: 2025-05-17)
💡 一句话要点
提出S-GRPO,通过强化学习实现推理模型的早期退出,提升效率和准确率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 推理模型 早期退出 思维链 序列长度 奖励策略 模型优化
📋 核心要点
- 现有推理模型在思维链生成中存在过度思考的冗余问题,降低了效率。
- S-GRPO通过强化学习,使模型能够评估中间推理步骤的充分性,从而实现早期退出。
- 实验表明,S-GRPO在减少序列长度的同时,提高了包括Qwen3在内的多个模型的准确率。
📝 摘要(中文)
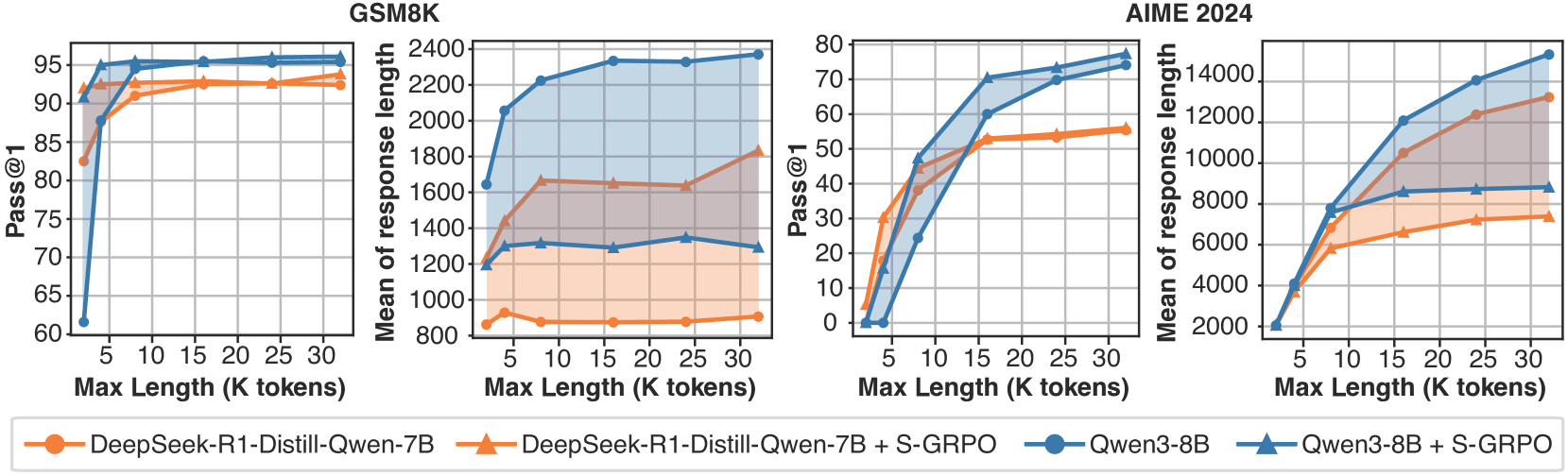
随着测试时扩展成为大型语言模型社区的研究热点,先进的后训练方法越来越重视扩展思维链(CoT)生成长度,从而增强推理能力,以接近Deepseek R1等推理模型。然而,最近的研究表明,推理模型(甚至Qwen3)在CoT生成中始终表现出过度的思维冗余。这种过度思考问题源于传统结果奖励强化学习的固有局限性,该方法系统地忽略了对中间推理过程的调节。本文提出了一种新的强化学习范式——串行-组衰减奖励策略优化(S-GRPO),使模型能够隐式地评估中间推理步骤的充分性,从而促进CoT生成中的早期退出。与并行采样多个可能推理路径的GRPO不同,S-GRPO仅采样一个推理路径,并从中串行选择多个时间位置来退出思考并直接生成答案。对于串行组中的正确答案,奖励会根据推理路径上从前到后的退出位置逐渐减少。这种设计鼓励模型产生更准确和简洁的想法,同时也激励在适当的时候提前终止思考。经验评估表明,S-GRPO与最先进的推理模型(包括Qwen3和Deepseek-distill)兼容。在GSM8K、AIME 2024、AMC 2023、MATH-500和GPQA Diamond等各种基准测试中,S-GRPO在显著减少序列长度(35.4% - 61.1%)的同时,还提高了准确率(绝对值0.72% - 6.08%)。
🔬 方法详解
问题定义:论文旨在解决推理模型在思维链(CoT)生成过程中存在的过度思考和冗余问题。现有方法,特别是基于结果奖励的强化学习,无法有效调节中间推理过程,导致模型产生不必要的思考步骤,降低效率。
核心思路:S-GRPO的核心思路是通过设计一种新的奖励机制,激励模型在推理过程中尽早退出,并在保证准确率的前提下,减少不必要的计算。模型通过评估中间推理步骤的充分性,决定何时停止思考并生成答案。
技术框架:S-GRPO的技术框架主要包含以下几个阶段:1) 使用推理模型生成一条推理路径;2) 从该路径中串行选择多个时间位置作为可能的退出点;3) 模型在每个退出点尝试生成答案;4) 根据答案的正确性和退出位置,给予模型不同的奖励。与GRPO不同,S-GRPO采用串行采样,每次只采样一条推理路径,降低了计算复杂度。
关键创新:S-GRPO的关键创新在于其串行-组衰减奖励策略。与传统的并行采样方法不同,S-GRPO采用串行采样,降低了计算成本。此外,奖励函数的设计也至关重要,对于在较早位置正确退出的模型,给予更高的奖励,从而鼓励模型尽早停止思考。
关键设计:S-GRPO的关键设计包括:1) 串行采样策略,每次只采样一条推理路径;2) 衰减奖励函数,根据退出位置和答案正确性给予不同的奖励,越早正确退出奖励越高;3) 损失函数的设计,需要平衡准确率和序列长度之间的关系。具体的参数设置和网络结构的选择取决于所使用的基础推理模型。
🖼️ 关键图片


📊 实验亮点
S-GRPO在多个基准测试中取得了显著的性能提升。在GSM8K、AIME 2024、AMC 2023、MATH-500和GPQA Diamond等数据集上,S-GRPO在显著减少序列长度(35.4% - 61.1%)的同时,还提高了准确率(绝对值0.72% - 6.08%)。这些结果表明,S-GRPO能够有效地减少推理过程中的冗余计算,并提高模型的推理能力。
🎯 应用场景
S-GRPO具有广泛的应用前景,可以应用于各种需要复杂推理的场景,例如数学问题求解、知识图谱推理、自然语言理解等。通过减少推理过程中的冗余计算,S-GRPO可以显著提高推理效率,降低计算成本,并有望部署在资源受限的设备上。此外,S-GRPO还可以作为一种通用的后训练方法,用于提升现有推理模型的性能。
📄 摘要(原文)
As Test-Time Scaling emerges as an active research focus in the large language model community, advanced post-training methods increasingly emphasize extending chain-of-thought (CoT) generation length, thereby enhancing reasoning capabilities to approach Deepseek R1-like reasoning models. However, recent studies reveal that reasoning models (even Qwen3) consistently exhibit excessive thought redundancy in CoT generation. This overthinking issue arises from the inherent limitations of conventional outcome-reward reinforcement learning, which systematically overlooks the regulation of intermediate reasoning processes. This paper introduces Serial-Group Decaying-Reward Policy Optimization (S-GRPO), a novel reinforcement learning paradigm that enables models to implicitly evaluate the sufficiency of intermediate reasoning steps, thereby facilitating early exit in CoT generation. Unlike GRPO, which samples multiple possible reasoning paths in parallel (parallel group), S-GRPO only samples one reasoning path and serially selects multiple temporal positions from the path to exit thinking and directly generate answers (serial group). For correct answers within a serial group, rewards gradually decrease based on the exit positions along the reasoning path from front to back. This design encourages the model to produce more accurate and concise thoughts, while also incentivizing early thinking termination when appropriate. Empirical evaluations demonstrate that S-GRPO is compatible with state-of-the-art reasoning models, including Qwen3 and Deepseek-distill. Across diverse benchmarks such as GSM8K, AIME 2024, AMC 2023, MATH-500, and GPQA Diamond, S-GRPO achieves a substantial reduction in sequence length (35.4% - 61.1%) while simultaneously improving accuracy (absolute 0.72% - 6.08%).