Towards Artificial General or Personalized Intelligence? A Survey on Foundation Models for Personalized Federated Intelligence
作者: Yu Qiao, Huy Q. Le, Avi Deb Raha, Phuong-Nam Tran, Apurba Adhikary, Mengchun Zhang, Loc X. Nguyen, Eui-Nam Huh, Dusit Niyato, Choong Seon Hong
分类: cs.AI, cs.CV, cs.NE
发布日期: 2025-05-11
备注: On going work
💡 一句话要点
提出个性化联邦智能,融合联邦学习与大模型,实现高效隐私保护的边缘个性化部署。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化联邦智能 联邦学习 基础模型 边缘智能 隐私保护
📋 核心要点
- 现有大型语言模型虽然强大,但在个性化定制、隐私保护和计算资源需求方面面临挑战,难以满足边缘设备的个性化需求。
- 论文提出个性化联邦智能(PFI)的概念,结合联邦学习的隐私保护特性和基础模型的零样本泛化能力,实现边缘设备的个性化部署。
- 论文综述了联邦学习和基础模型的最新进展,探讨了利用基础模型增强联邦系统的潜力,并展望了PFI的未来研究方向和挑战。
📝 摘要(中文)
大型语言模型(LLMs)的兴起,如ChatGPT、DeepSeek和Grok-3,重塑了人工智能的格局。作为构建在LLMs之上的基础模型(FMs)的突出例子,这些模型在生成类人内容方面表现出卓越的能力,使我们更接近实现通用人工智能(AGI)。然而,它们的大规模性质、对隐私问题的敏感性以及巨大的计算需求,给最终用户的个性化定制带来了重大挑战。为了弥合这一差距,本文提出了人工个性化智能(API)的愿景,重点在于调整这些强大的模型,以满足用户的特定需求和偏好,同时保持隐私和效率。具体而言,本文提出了个性化联邦智能(PFI),它将联邦学习(FL)的隐私保护优势与FMs的零样本泛化能力相结合,从而实现在边缘进行个性化、高效和隐私保护的部署。我们首先回顾了FL和FMs的最新进展,并讨论了利用FMs来增强联邦系统的潜力。然后,我们介绍了实现PFI背后的关键动机,并探讨了该领域中充满希望的机会,包括高效PFI、可信PFI以及由检索增强生成(RAG)支持的PFI。最后,我们概述了在边缘部署由FM驱动的FL系统以提高个性化、计算效率和隐私保证的关键挑战和未来研究方向。总的来说,本调查旨在为API的开发奠定基础,作为对AGI的补充,特别关注PFI作为一种关键的使能技术。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)虽然在通用任务上表现出色,但难以直接应用于边缘设备,主要痛点在于:1)模型规模庞大,计算资源需求高;2)数据隐私敏感,直接部署存在泄露风险;3)缺乏个性化定制,难以满足不同用户的特定需求。因此,如何在边缘设备上实现高效、隐私保护且个性化的智能服务成为一个亟待解决的问题。
核心思路:论文的核心思路是将联邦学习(FL)的隐私保护优势与基础模型(FMs)的零样本泛化能力相结合,提出个性化联邦智能(PFI)的概念。通过联邦学习,可以在不共享原始数据的情况下训练模型,保护用户隐私;通过基础模型,可以利用其强大的泛化能力,减少对大量个性化数据的依赖,实现快速的个性化定制。
技术框架:PFI的整体框架可以概括为以下几个阶段:1)基础模型预训练:使用大规模通用数据集预训练一个基础模型;2)联邦学习个性化:将预训练的基础模型作为初始模型,利用联邦学习框架,在边缘设备上进行个性化训练,每个设备使用本地数据进行微调;3)模型聚合与更新:服务器端收集边缘设备的模型更新,进行聚合,并将更新后的模型分发给边缘设备;4)推理与部署:边缘设备使用个性化后的模型进行推理,提供个性化的智能服务。
关键创新:论文的关键创新在于提出了PFI的概念,并探讨了如何将联邦学习和基础模型相结合,以实现边缘设备的个性化智能。此外,论文还提出了高效PFI、可信PFI以及由检索增强生成(RAG)支持的PFI等潜在方向,为未来的研究提供了思路。
关键设计:论文并未提供具体的参数设置或网络结构等技术细节,而是侧重于概念的提出和框架的构建。未来的研究可以关注以下关键设计:1)高效的联邦学习算法:如何减少通信开销和计算复杂度,提高联邦学习的效率;2)个性化模型聚合策略:如何根据不同设备的贡献度进行模型聚合,提高个性化模型的性能;3)隐私保护机制:如何进一步增强隐私保护,防止模型泄露用户敏感信息;4)检索增强生成(RAG):如何利用RAG技术,从外部知识库中检索相关信息,增强模型的生成能力。
🖼️ 关键图片
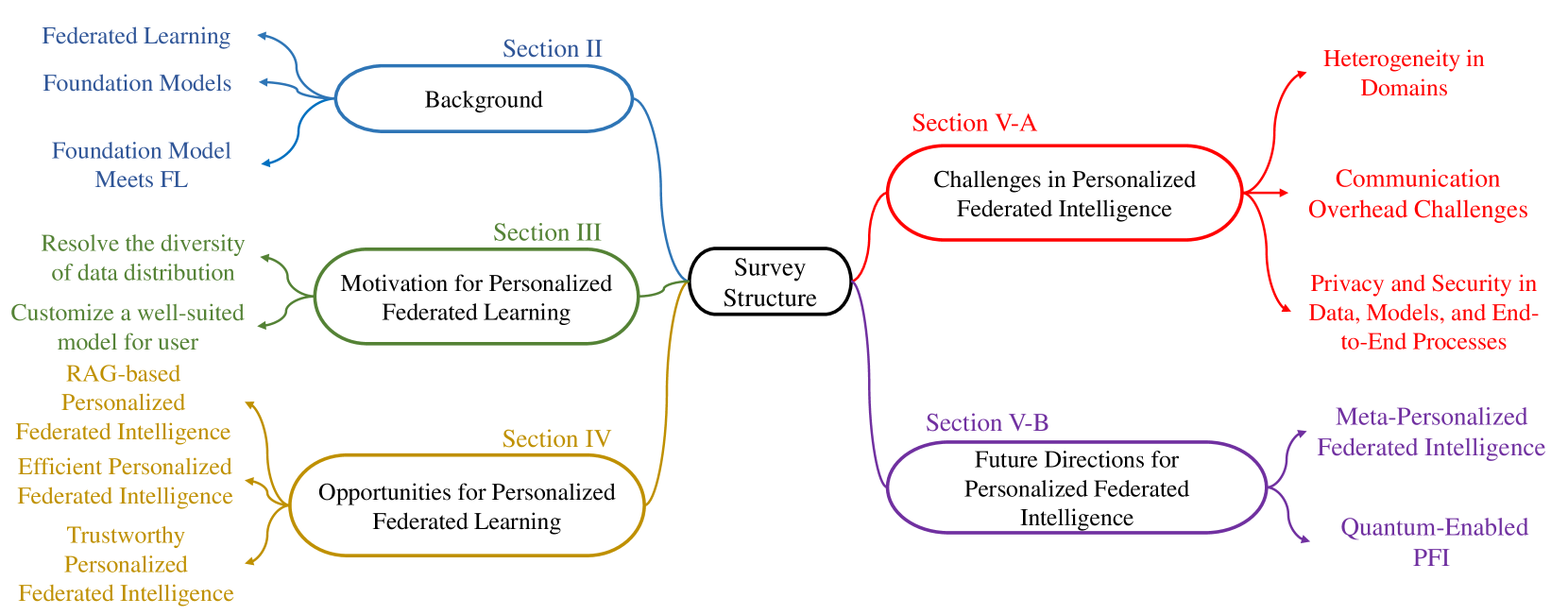
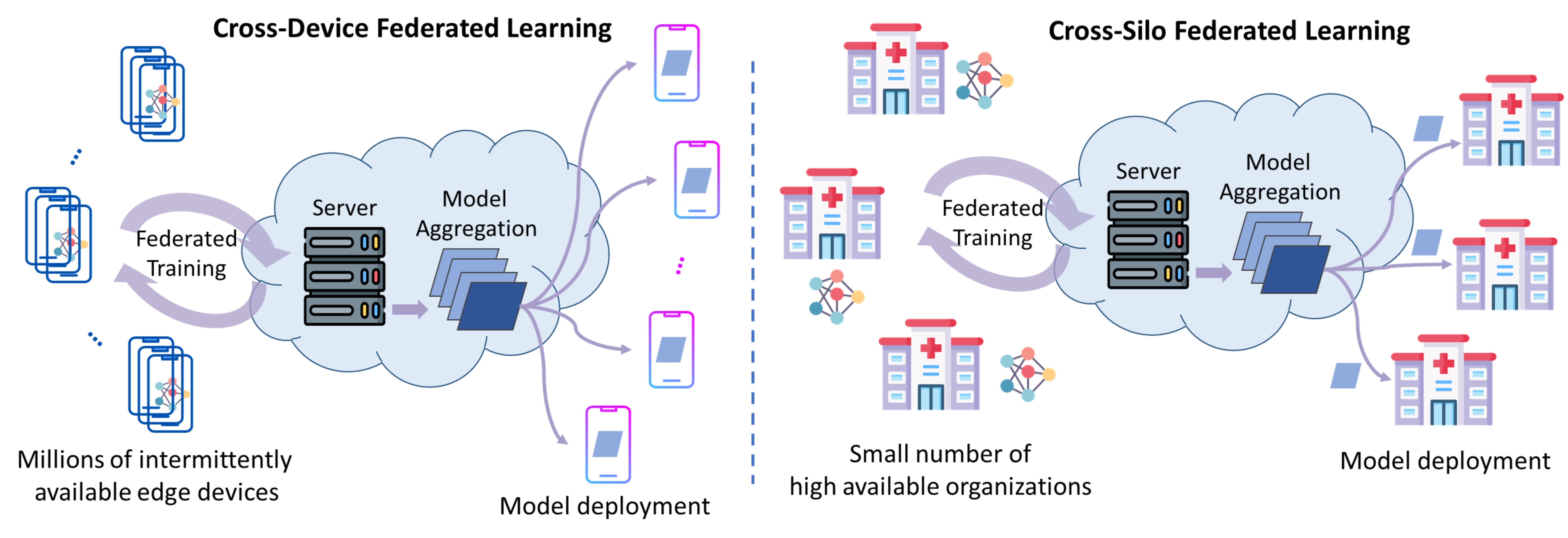
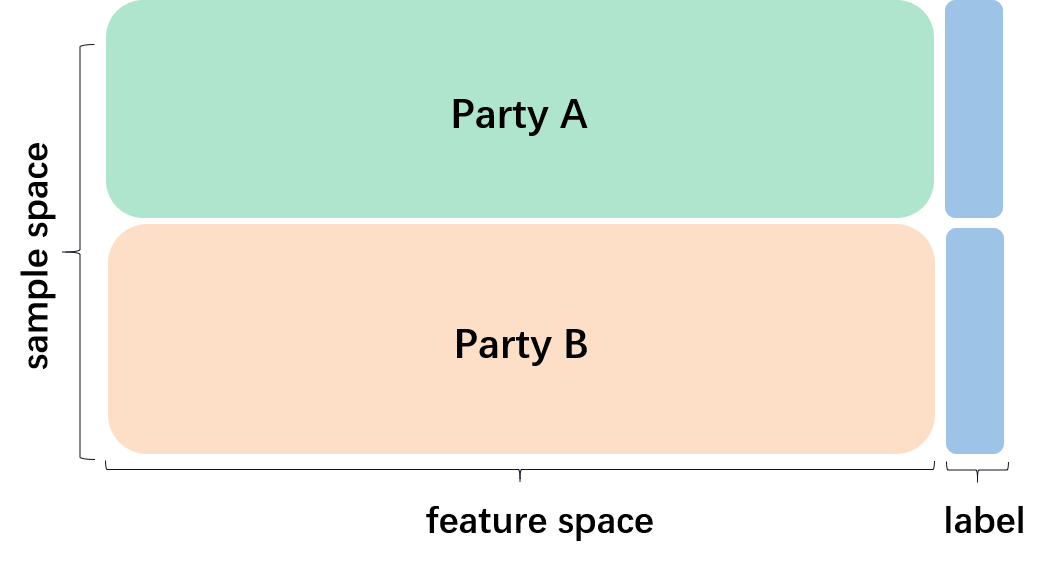
📊 实验亮点
该论文是一篇综述性文章,主要贡献在于提出了个性化联邦智能(PFI)的概念,并探讨了其在边缘智能中的应用前景。论文并未提供具体的实验结果,而是侧重于对现有技术的分析和未来方向的展望。未来的研究可以关注PFI的具体实现和性能评估。
🎯 应用场景
PFI在多个领域具有广泛的应用前景,例如:个性化推荐系统、智能医疗诊断、智能家居控制、自动驾驶等。通过PFI,可以在保护用户隐私的前提下,为用户提供更加个性化、高效和智能的服务。未来,PFI有望成为边缘智能的重要组成部分,推动人工智能在各个领域的应用。
📄 摘要(原文)
The rise of large language models (LLMs), such as ChatGPT, DeepSeek, and Grok-3, has reshaped the artificial intelligence landscape. As prominent examples of foundational models (FMs) built on LLMs, these models exhibit remarkable capabilities in generating human-like content, bringing us closer to achieving artificial general intelligence (AGI). However, their large-scale nature, sensitivity to privacy concerns, and substantial computational demands present significant challenges to personalized customization for end users. To bridge this gap, this paper presents the vision of artificial personalized intelligence (API), focusing on adapting these powerful models to meet the specific needs and preferences of users while maintaining privacy and efficiency. Specifically, this paper proposes personalized federated intelligence (PFI), which integrates the privacy-preserving advantages of federated learning (FL) with the zero-shot generalization capabilities of FMs, enabling personalized, efficient, and privacy-protective deployment at the edge. We first review recent advances in both FL and FMs, and discuss the potential of leveraging FMs to enhance federated systems. We then present the key motivations behind realizing PFI and explore promising opportunities in this space, including efficient PFI, trustworthy PFI, and PFI empowered by retrieval-augmented generation (RAG). Finally, we outline key challenges and future research directions for deploying FM-powered FL systems at the edge with improved personalization, computational efficiency, and privacy guarantees. Overall, this survey aims to lay the groundwork for the development of API as a complement to AGI, with a particular focus on PFI as a key enabling technique.