OMGM: Orchestrate Multiple Granularities and Modalities for Efficient Multimodal Retrieval
作者: Wei Yang, Jingjing Fu, Rui Wang, Jinyu Wang, Lei Song, Jiang Bian
分类: cs.IR, cs.AI, cs.CV
发布日期: 2025-05-10 (更新: 2025-09-12)
备注: Accepted to ACL 2025 Main Conference
💡 一句话要点
提出OMGM,通过多粒度和多模态协同,高效解决视觉-语言检索增强生成任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 检索增强生成 知识库视觉问答 多粒度学习 跨模态融合
📋 核心要点
- KB-VQA任务依赖外部知识,现有方法在多模态和多粒度知识的协同利用上存在不足。
- OMGM系统采用由粗到细的多步骤检索策略,协调不同粒度和模态的信息,提升检索效率。
- 实验结果表明,OMGM在InfoSeek和Encyclopedic-VQA数据集上取得了SOTA检索性能和极具竞争力的问答结果。
📝 摘要(中文)
视觉-语言检索增强生成(RAG)已成为解决知识库视觉问答(KB-VQA)的有效方法,该方法需要图像中呈现的视觉内容之外的外部知识。视觉-语言RAG系统的有效性取决于多模态检索,由于查询和知识库中存在不同的模态和知识粒度,这本身就具有挑战性。现有方法尚未充分挖掘这些元素之间潜在的相互作用。我们提出了一个多模态RAG系统,该系统具有由粗到细的多步骤检索,协调多个粒度和模态以提高效率。我们的系统首先进行广泛的初始搜索,对齐跨模态检索的知识粒度,然后进行多模态融合重排序,以捕获细微的多模态信息以进行顶级实体选择。然后,文本重排序器会过滤掉最相关的细粒度部分以进行增强生成。在InfoSeek和Encyclopedic-VQA基准上的大量实验表明,我们的方法实现了最先进的检索性能和极具竞争力的回答结果,突显了其在推进KB-VQA系统方面的有效性。
🔬 方法详解
问题定义:论文旨在解决知识库视觉问答(KB-VQA)中,由于查询和知识库存在不同的模态和知识粒度,导致多模态检索效率低下的问题。现有方法未能充分利用不同模态和粒度信息之间的相互作用,导致检索结果不准确,影响最终的问答效果。
核心思路:论文的核心思路是采用由粗到细的多步骤检索策略,首先进行粗粒度的跨模态检索,快速缩小搜索范围,然后通过多模态融合重排序,精细化选择相关实体,最后通过文本重排序,提取最相关的细粒度文本片段。这种分层检索的方式能够有效协调不同模态和粒度的信息,提高检索效率和准确性。
技术框架:OMGM系统包含三个主要阶段:1) 粗粒度跨模态检索:利用图像和文本信息进行初步检索,缩小候选知识范围。2) 多模态融合重排序:融合视觉和语言信息,对候选知识进行重排序,选择最相关的实体。3) 细粒度文本重排序:对选定的实体进行文本片段级别的重排序,提取最相关的文本片段用于增强生成。
关键创新:OMGM的关键创新在于其多粒度、多模态协同的检索框架。与现有方法相比,OMGM不是简单地将不同模态的信息进行融合,而是通过分层检索的方式,逐步缩小搜索范围,并充分利用不同粒度的信息。这种方法能够更有效地处理复杂的多模态检索任务,提高检索效率和准确性。
关键设计:在粗粒度跨模态检索阶段,可以使用预训练的视觉-语言模型(如CLIP)进行特征提取和相似度计算。在多模态融合重排序阶段,可以使用注意力机制或图神经网络来融合视觉和语言信息。在细粒度文本重排序阶段,可以使用BERT等预训练语言模型进行文本相似度计算。具体的损失函数和网络结构需要根据具体的数据集和任务进行调整。
🖼️ 关键图片


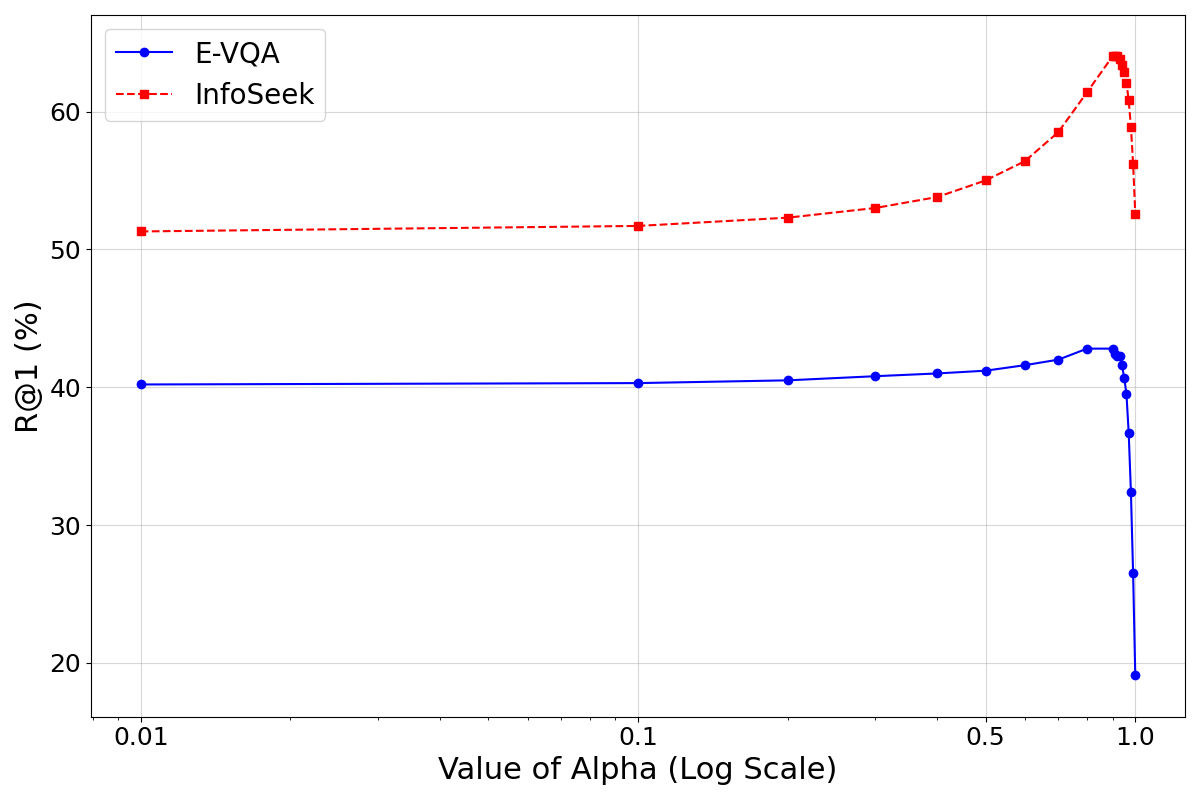
📊 实验亮点
OMGM在InfoSeek和Encyclopedic-VQA数据集上进行了实验,取得了SOTA的检索性能和极具竞争力的问答结果。具体来说,在检索任务上,OMGM的性能显著优于现有的基线方法。实验结果表明,OMGM能够有效地提高KB-VQA系统的性能。
🎯 应用场景
该研究成果可广泛应用于需要结合视觉信息和外部知识的问答系统、智能搜索、内容推荐等领域。例如,在电商领域,可以根据用户上传的商品图片,结合商品知识库,快速找到相关的商品信息和用户评价。在医疗领域,可以根据医学影像,结合医学知识库,辅助医生进行诊断和治疗。
📄 摘要(原文)
Vision-language retrieval-augmented generation (RAG) has become an effective approach for tackling Knowledge-Based Visual Question Answering (KB-VQA), which requires external knowledge beyond the visual content presented in images. The effectiveness of Vision-language RAG systems hinges on multimodal retrieval, which is inherently challenging due to the diverse modalities and knowledge granularities in both queries and knowledge bases. Existing methods have not fully tapped into the potential interplay between these elements. We propose a multimodal RAG system featuring a coarse-to-fine, multi-step retrieval that harmonizes multiple granularities and modalities to enhance efficacy. Our system begins with a broad initial search aligning knowledge granularity for cross-modal retrieval, followed by a multimodal fusion reranking to capture the nuanced multimodal information for top entity selection. A text reranker then filters out the most relevant fine-grained section for augmented generation. Extensive experiments on the InfoSeek and Encyclopedic-VQA benchmarks show our method achieves state-of-the-art retrieval performance and highly competitive answering results, underscoring its effectiveness in advancing KB-VQA systems.