An Empirical Study of OpenAI API Discussions on Stack Overflow
作者: Xiang Chen, Jibin Wang, Chaoyang Gao, Xiaolin Ju, Zhanqi Cui
分类: cs.SE, cs.AI
发布日期: 2025-05-07
💡 一句话要点
首次实证研究Stack Overflow上OpenAI API讨论,揭示开发者面临的挑战与应对策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: OpenAI API 大型语言模型 Stack Overflow 实证研究 开发者挑战
📋 核心要点
- 现有研究缺乏对开发者使用OpenAI API时面临挑战的系统性分析,阻碍了API的有效应用和问题解决。
- 本研究通过分析Stack Overflow上的大量OpenAI API讨论,识别开发者遇到的各类问题,并进行分类和主题建模。
- 研究揭示了prompt工程、成本管理、非确定性输出等关键挑战,并为开发者、供应商和研究人员提供了改进建议。
📝 摘要(中文)
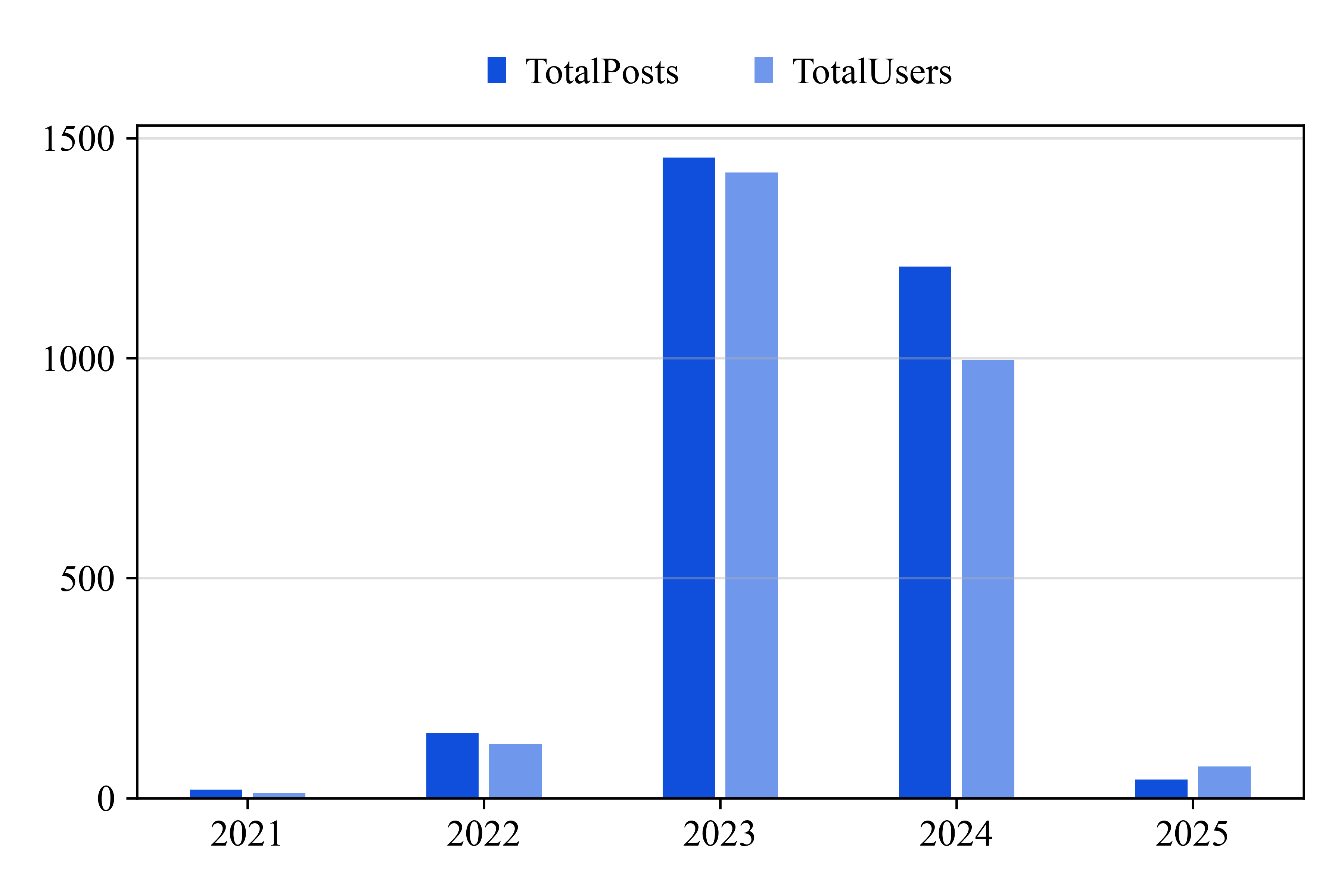
OpenAI的GPT系列代表的大型语言模型(LLMs)的快速发展,对自然语言处理、软件开发、教育、医疗、金融和科学研究等多个领域产生了重大影响。然而,OpenAI API引入了与传统API不同的独特挑战,例如prompt工程的复杂性、基于token的成本管理、非确定性输出以及作为黑盒运行。据我们所知,之前的实证研究尚未探索开发者在使用OpenAI API时遇到的挑战。为了填补这一空白,我们通过分析来自热门问答论坛Stack Overflow的2874个OpenAI API相关讨论,进行了首次全面的实证研究。我们首先检查了这些帖子的受欢迎程度和难度。在将它们手动分类为九个OpenAI API相关类别后,我们通过主题建模分析确定了与每个类别相关的具体挑战。基于我们的实证研究结果,我们最终为开发者、LLM供应商和研究人员提出了可操作的建议。
🔬 方法详解
问题定义:论文旨在解决开发者在使用OpenAI API时遇到的各种挑战,这些挑战与传统API不同,包括prompt工程的复杂性、token成本管理、输出的不确定性以及API的黑盒特性。现有方法缺乏对这些挑战的系统性研究,导致开发者难以有效利用OpenAI API,并难以解决使用过程中遇到的问题。
核心思路:论文的核心思路是通过分析Stack Overflow上的大量OpenAI API相关讨论,挖掘开发者实际遇到的问题和挑战。通过对这些讨论进行分类、主题建模等分析,识别出不同类别API使用中存在的共性问题,并为开发者、API供应商和研究人员提供改进建议。
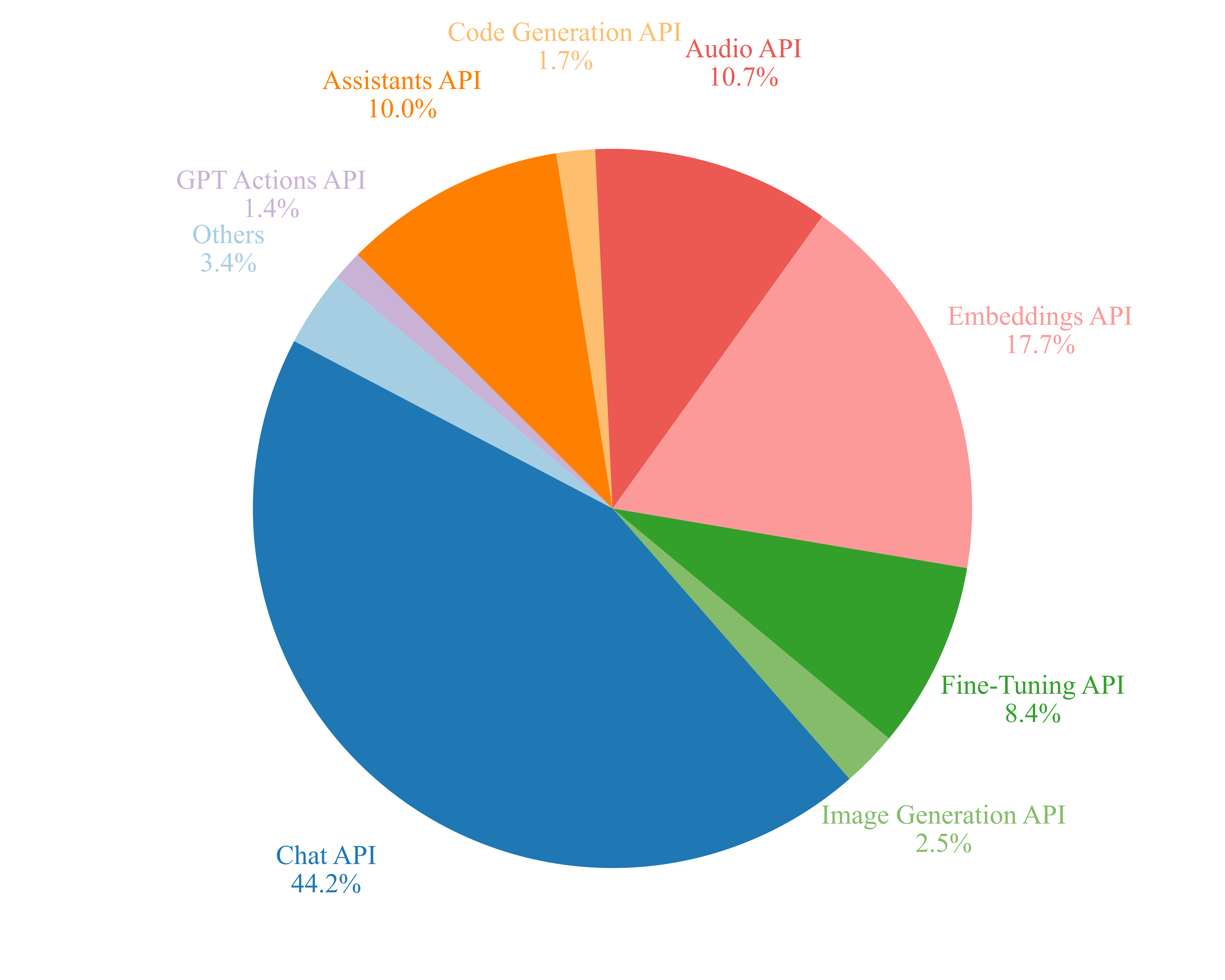
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据收集:从Stack Overflow收集OpenAI API相关的讨论帖子。2) 数据清洗与预处理:对收集到的帖子进行清洗,去除噪声数据。3) 人工分类:将帖子手动分类为九个OpenAI API相关类别。4) 主题建模:对每个类别下的帖子进行主题建模,识别出该类别下开发者遇到的主要挑战。5) 结果分析与建议:基于主题建模的结果,分析开发者面临的挑战,并为开发者、API供应商和研究人员提出改进建议。
关键创新:该研究的关键创新在于首次对开发者在使用OpenAI API时遇到的挑战进行了全面的实证研究。通过分析Stack Overflow上的真实数据,揭示了prompt工程、成本管理、非确定性输出等关键挑战,并为解决这些挑战提供了有价值的见解。此前,针对OpenAI API使用挑战的研究较少,该研究填补了这一空白。
关键设计:论文的关键设计包括:1) 选择了Stack Overflow作为数据来源,因为它是开发者常用的问答社区,包含了大量真实的使用案例和问题。2) 采用了人工分类和主题建模相结合的方法,既保证了分类的准确性,又能够有效地挖掘出隐藏在文本中的主题和挑战。3) 针对不同类型的用户(开发者、API供应商、研究人员)提出了不同的改进建议,具有较强的实用性。
🖼️ 关键图片

📊 实验亮点
研究分析了2874个Stack Overflow上的OpenAI API相关讨论,识别出九个主要类别的问题。主题建模结果揭示了prompt工程、token成本管理、非确定性输出等是开发者面临的主要挑战。研究还发现,不同类别的API使用中存在不同的挑战,例如,文本生成API更关注prompt工程,而图像生成API更关注输出质量。
🎯 应用场景
该研究成果可应用于改进OpenAI API的文档和示例代码,帮助开发者更好地理解和使用API。同时,API供应商可以根据研究结果优化API的设计和功能,降低开发者的使用门槛。此外,该研究也为后续研究提供了基础,可以进一步探索OpenAI API在不同领域的应用和挑战。
📄 摘要(原文)
The rapid advancement of large language models (LLMs), represented by OpenAI's GPT series, has significantly impacted various domains such as natural language processing, software development, education, healthcare, finance, and scientific research. However, OpenAI APIs introduce unique challenges that differ from traditional APIs, such as the complexities of prompt engineering, token-based cost management, non-deterministic outputs, and operation as black boxes. To the best of our knowledge, the challenges developers encounter when using OpenAI APIs have not been explored in previous empirical studies. To fill this gap, we conduct the first comprehensive empirical study by analyzing 2,874 OpenAI API-related discussions from the popular Q&A forum Stack Overflow. We first examine the popularity and difficulty of these posts. After manually categorizing them into nine OpenAI API-related categories, we identify specific challenges associated with each category through topic modeling analysis. Based on our empirical findings, we finally propose actionable implications for developers, LLM vendors, and researchers.