Rainbow Delay Compensation: A Multi-Agent Reinforcement Learning Framework for Mitigating Delayed Observation
作者: Songchen Fu, Siang Chen, Shaojing Zhao, Letian Bai, Ta Li, Yonghong Yan
分类: cs.MA, cs.AI
发布日期: 2025-05-06 (更新: 2025-11-12)
备注: The code has been open-sourced in the RDC-pymarl project under https://github.com/linkjoker1006
🔗 代码/项目: GITHUB
💡 一句话要点
提出Rainbow Delay Compensation框架,解决多智能体系统中观测延迟问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 观测延迟 延迟补偿 部分可观测马尔可夫决策过程 去中心化控制
📋 核心要点
- 现实多智能体系统存在观测延迟,导致智能体无法基于真实状态决策,现有方法难以有效处理。
- 论文提出Rainbow Delay Compensation (RDC)框架,通过补偿延迟信息,使智能体能够更好地估计真实环境状态。
- 实验表明,RDC框架在存在延迟的MPE和SMAC环境中,显著提升了多智能体系统的性能,接近无延迟情况下的理想性能。
📝 摘要(中文)
在真实世界的多智能体系统(MASs)中,观测延迟普遍存在,阻碍了智能体基于环境真实状态做出决策。单个智能体的局部观测通常包含来自其他智能体或环境中动态实体的多个组件。这些具有不同延迟特性的离散观测组件给多智能体强化学习(MARL)带来了重大挑战。本文首先通过扩展标准的Dec-POMDP,提出了去中心化随机个体延迟部分可观测马尔可夫决策过程(DSID-POMDP)。然后,我们提出了Rainbow Delay Compensation (RDC),这是一个用于解决随机个体延迟的MARL训练框架,以及其组成模块的推荐实现。我们使用标准的MARL基准,包括MPE和SMAC,实现了DSID-POMDP的观测生成模式。实验表明,基线MARL方法在固定和非固定延迟下性能严重下降。RDC增强方法缓解了这个问题,在某些延迟场景中显著实现了理想的无延迟性能,同时保持了泛化性。我们的工作为多智能体延迟观测问题提供了一个新的视角,并提供了一个有效的解决方案框架。源代码可在https://github.com/linkjoker1006/RDC-pymarl获得。
🔬 方法详解
问题定义:论文旨在解决多智能体强化学习中,由于各个智能体观测到的信息存在随机且独立的延迟,导致传统MARL算法性能显著下降的问题。现有方法通常假设观测是即时的,或者采用简单的平均延迟处理,无法有效应对复杂的随机个体延迟情况。这种延迟会严重影响智能体对环境状态的估计,进而影响决策。
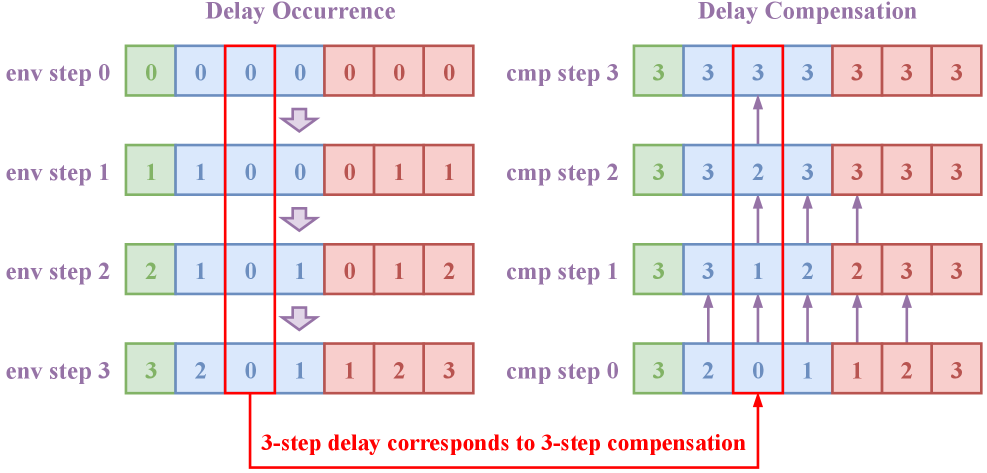
核心思路:RDC的核心思路是通过补偿延迟观测,使智能体能够更准确地估计当前环境的真实状态。具体来说,RDC框架利用历史观测信息,结合智能体的策略和环境动态模型,预测当前时刻的潜在状态,从而弥补延迟带来的信息缺失。这种补偿机制允许智能体在不完全和延迟信息下做出更明智的决策。
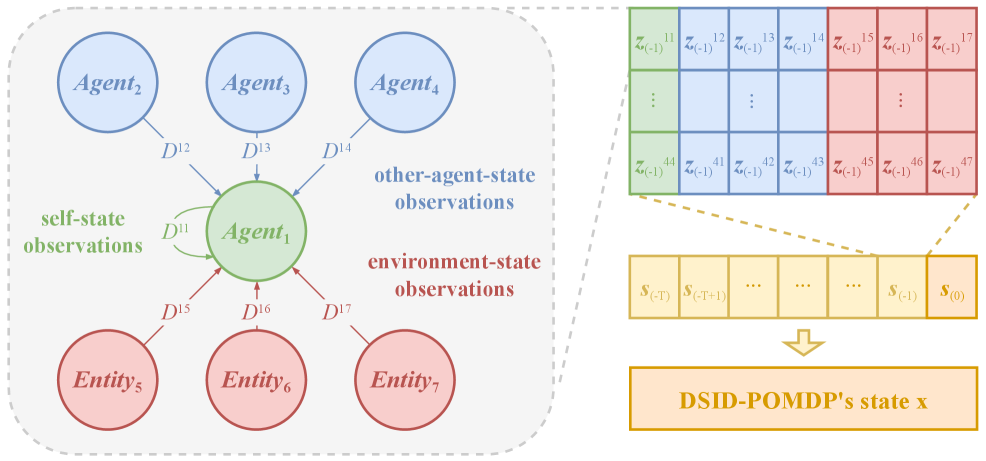
技术框架:RDC框架主要包含以下几个模块:1) 延迟观测生成模块:模拟DSID-POMDP环境,生成具有随机个体延迟的观测数据。2) 延迟补偿模块:利用历史观测和智能体策略,估计当前环境状态。3) 强化学习训练模块:使用补偿后的状态信息训练智能体策略。整体流程是,首先通过延迟观测生成模块模拟真实环境中的延迟情况,然后利用延迟补偿模块对观测进行处理,最后将补偿后的信息输入到强化学习算法中进行训练。
关键创新:RDC的关键创新在于其延迟补偿机制,它能够有效地利用历史信息来估计当前状态,从而缓解延迟带来的负面影响。与现有方法相比,RDC能够处理更复杂的随机个体延迟情况,并且具有更好的泛化能力。此外,论文提出的DSID-POMDP为研究多智能体延迟观测问题提供了一个新的理论框架。
关键设计:RDC框架的具体实现可以根据不同的强化学习算法进行调整。论文推荐使用Rainbow算法作为基础的强化学习算法,并结合LSTM网络来处理历史观测信息。延迟补偿模块可以使用卡尔曼滤波或者其他状态估计方法。损失函数的设计需要考虑延迟补偿的准确性和策略的优化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在MPE和SMAC等标准MARL基准测试中,RDC框架能够显著提升多智能体系统的性能,尤其是在存在较大延迟的情况下。在某些延迟场景下,RDC甚至能够达到接近无延迟情况下的理想性能。与基线MARL方法相比,RDC在固定和非固定延迟下均表现出更强的鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于各种存在观测延迟的多智能体系统,例如:自动驾驶车辆编队、机器人协同作业、分布式传感器网络、金融交易系统等。通过RDC框架,可以提高这些系统在复杂环境下的鲁棒性和性能,使其能够更好地应对实际应用中的挑战,具有重要的实际应用价值和潜力。
📄 摘要(原文)
In real-world multi-agent systems (MASs), observation delays are ubiquitous, preventing agents from making decisions based on the environment's true state. An individual agent's local observation typically comprises multiple components from other agents or dynamic entities within the environment. These discrete observation components with varying delay characteristics pose significant challenges for multi-agent reinforcement learning (MARL). In this paper, we first formulate the decentralized stochastic individual delay partially observable Markov decision process (DSID-POMDP) by extending the standard Dec-POMDP. We then propose the Rainbow Delay Compensation (RDC), a MARL training framework for addressing stochastic individual delays, along with recommended implementations for its constituent modules. We implement the DSID-POMDP's observation generation pattern using standard MARL benchmarks, including MPE and SMAC. Experiments demonstrate that baseline MARL methods suffer severe performance degradation under fixed and unfixed delays. The RDC-enhanced approach mitigates this issue, remarkably achieving ideal delay-free performance in certain delay scenarios while maintaining generalizability. Our work provides a novel perspective on multi-agent delayed observation problems and offers an effective solution framework. The source code is available at https://github.com/linkjoker1006/RDC-pymarl.