Patterns and Mechanisms of Contrastive Activation Engineering
作者: Yixiong Hao, Ayush Panda, Stepan Shabalin, Sheikh Abdur Raheem Ali
分类: cs.AI, cs.HC
发布日期: 2025-05-06
备注: Published at the ICLR 2025 Bi-Align, HAIC, and Building Trust workshops
💡 一句话要点
对比激活工程(CAE)调控大语言模型,但存在分布外失效、易受攻击等问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对比激活工程 大语言模型 模型调控 对抗攻击 分布外泛化
📋 核心要点
- 大型语言模型行为控制困难,微调成本高昂,对比激活工程(CAE)提供了一种低成本的推理时调控方法。
- CAE通过修改LLM内部表示来引导输出,无需训练,但其有效性和鲁棒性需要深入研究。
- 论文分析了CAE在不同场景下的性能,揭示了其局限性,并为有效部署提供了指导。
📝 摘要(中文)
大型语言模型(LLM)的行为控制因其复杂性和不透明性而极具挑战。微调等技术虽然可以修改模型行为,但通常需要大量的计算资源。最近的研究引入了一种对比激活工程(CAE)技术,它通过有针对性地修改LLM的内部表示来引导LLM的输出。CAE在推理时应用,零成本,有可能为灵活的、特定于任务的LLM行为调整引入一种新的范例。我们分析了CAE在分布内和分布外环境中的性能,评估了其缺点,并开始制定有效部署的综合指南。我们发现:1. CAE仅在应用于分布内上下文时才可靠有效。2. 增加用于生成steering vectors的样本数量,在大约80个样本时收益递减。3. Steering vectors容易受到对抗性输入的影响,这些输入会逆转被引导的行为。4. Steering vectors会损害整体模型困惑度。5. 较大的模型更能抵抗steering引起的性能下降。
🔬 方法详解
问题定义:现有的大型语言模型行为控制方法,如微调,需要大量的计算资源。对比激活工程(CAE)旨在提供一种更轻量级的推理时干预方法,但其有效性、鲁棒性和适用范围尚不明确。论文关注CAE在不同分布数据上的表现,以及其潜在的缺陷和局限性。
核心思路:CAE的核心思想是通过修改LLM内部的激活向量来引导模型的输出。具体来说,通过构建steering vector,并在推理时将其添加到特定层的激活向量中,从而影响模型的行为。这种方法无需重新训练模型,可以在推理时动态调整模型的行为。
技术框架:CAE的整体流程如下:1. 收集一组用于生成steering vector的样本。2. 使用这些样本通过LLM,提取特定层的激活向量。3. 对这些激活向量进行处理(例如,求平均),得到steering vector。4. 在推理时,将steering vector添加到相应层的激活向量中,从而影响模型的输出。论文主要关注steering vector的生成和应用,以及其对模型性能的影响。
关键创新:论文的关键创新在于对CAE的系统性分析和评估。现有研究主要关注CAE在特定任务上的应用,而论文则深入研究了CAE的内在机制和局限性。通过实验,论文揭示了CAE在分布外数据上的失效问题、对对抗性输入的敏感性,以及对模型困惑度的影响。
关键设计:论文的关键设计包括:1. 使用不同数量的样本生成steering vector,以研究样本数量对CAE性能的影响。2. 设计对抗性输入,以评估steering vector的鲁棒性。3. 评估CAE对模型困惑度的影响,以衡量其对模型整体性能的损害。4. 在不同大小的模型上进行实验,以研究模型大小对CAE效果的影响。
🖼️ 关键图片

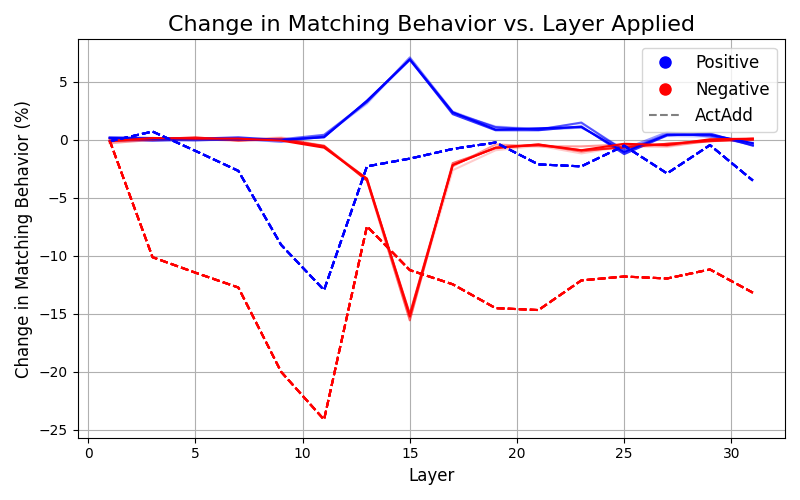
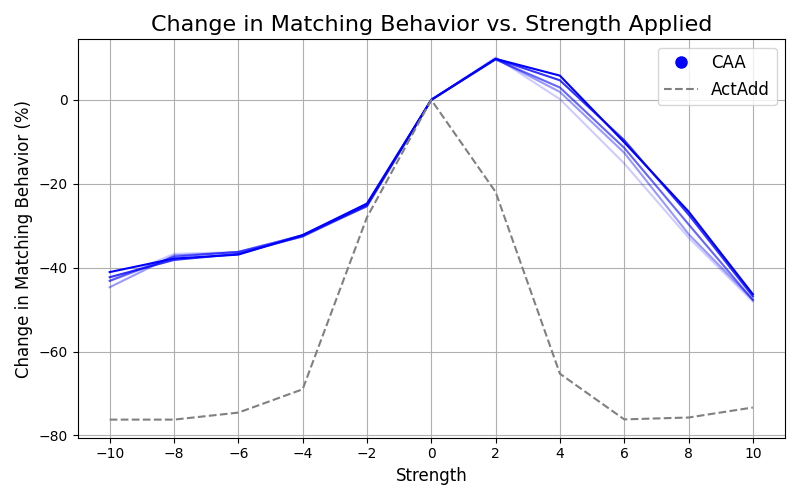
📊 实验亮点
实验结果表明,CAE仅在分布内数据上有效,且增加样本数量的收益递减,大约80个样本后效果不再明显。Steering vectors容易受到对抗性输入攻击,并会损害模型的困惑度。较大的模型更能抵抗steering引起的性能下降。这些发现为CAE的实际应用提供了重要的参考。
🎯 应用场景
对比激活工程(CAE)可应用于需要快速调整LLM行为的场景,例如对话系统中的风格控制、内容生成中的主题引导等。该研究有助于更好地理解和应用CAE,并为开发更鲁棒、更有效的LLM调控方法提供指导。未来的研究可以探索如何提高CAE在分布外数据上的性能,以及如何防御对抗性攻击。
📄 摘要(原文)
Controlling the behavior of Large Language Models (LLMs) remains a significant challenge due to their inherent complexity and opacity. While techniques like fine-tuning can modify model behavior, they typically require extensive computational resources. Recent work has introduced a class of contrastive activation engineering (CAE) techniques as promising approaches for steering LLM outputs through targeted modifications to their internal representations. Applied at inference-time with zero cost, CAE has the potential to introduce a new paradigm of flexible, task-specific LLM behavior tuning. We analyze the performance of CAE in in-distribution, out-of-distribution settings, evaluate drawbacks, and begin to develop comprehensive guidelines for its effective deployment. We find that 1. CAE is only reliably effective when applied to in-distribution contexts. 2. Increasing the number of samples used to generate steering vectors has diminishing returns at around 80 samples. 3. Steering vectors are susceptible to adversarial inputs that reverses the behavior that is steered for. 4. Steering vectors harm the overall model perplexity. 5. Larger models are more resistant to steering-induced degradation.