A Survey on GUI Agents with Foundation Models Enhanced by Reinforcement Learning
作者: Jiahao Li, Kaer Huang
分类: cs.AI
发布日期: 2025-04-29 (更新: 2025-05-13)
💡 一句话要点
综述:基于强化学习增强的具身智能GUI Agent
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI Agent 强化学习 多模态大语言模型 人机交互 自动化测试
📋 核心要点
- 现有GUI Agent在复杂环境中泛化性和鲁棒性不足,难以适应真实世界的变化。
- 论文核心在于综述基于强化学习增强的GUI Agent,关注感知、规划、行动模块的演进。
- 通过总结训练方法,强调从Prompt工程到动态策略学习的进展,提升Agent的性能。
📝 摘要(中文)
本文对图形用户界面(GUI)Agent的最新进展进行了结构化综述,重点关注通过强化学习(RL)增强的架构。GUI Agent由多模态大型语言模型(MLLM)驱动,已成为实现与数字系统智能交互的一种有前景的范例。首先,我们将GUI Agent任务形式化为马尔可夫决策过程,并讨论了典型的执行环境和评估指标。然后,我们回顾了基于(M)LLM的GUI Agent的模块化架构,涵盖感知、规划和行动模块,并通过代表性工作追溯了它们的演变。此外,我们将GUI Agent的训练方法分为基于Prompt、基于监督微调(SFT)和基于RL的方法,强调了从简单的Prompt工程到通过RL进行动态策略学习的进展。我们的总结说明了多模态感知、决策推理和自适应行动生成方面的最新创新如何显著提高GUI Agent在复杂真实环境中的泛化性和鲁棒性。最后,我们确定了构建更强大和可靠的GUI Agent的关键挑战和未来方向。
🔬 方法详解
问题定义:论文旨在解决GUI Agent在复杂真实环境中泛化性和鲁棒性不足的问题。现有的GUI Agent通常依赖于简单的prompt工程或监督微调,难以适应真实世界中GUI的复杂性和变化性,导致性能下降。
核心思路:论文的核心思路是通过强化学习(RL)来增强GUI Agent的决策能力,使其能够通过与环境的交互学习到更优的策略。通过将GUI Agent任务形式化为马尔可夫决策过程(MDP),利用RL算法来优化Agent的感知、规划和行动模块。
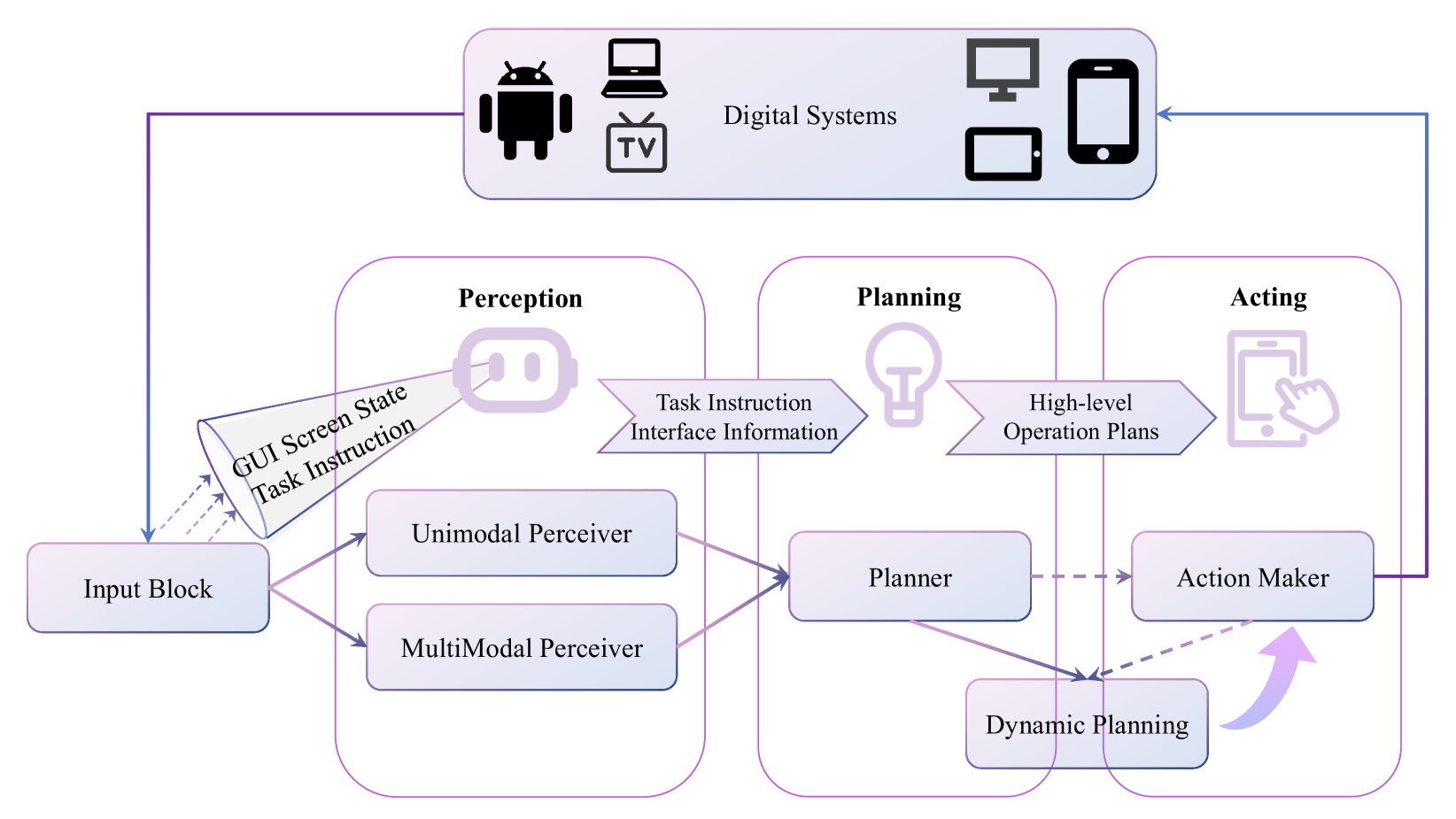
技术框架:GUI Agent的整体架构通常包含三个主要模块:感知模块(Perception)、规划模块(Planning)和行动模块(Acting)。感知模块负责从GUI界面中提取信息,规划模块负责制定行动计划,行动模块负责执行行动。这些模块通常由多模态大型语言模型(MLLM)驱动,并可以通过强化学习进行优化。
关键创新:论文的关键创新在于对基于强化学习增强的GUI Agent进行了全面的综述,并总结了不同训练方法的优缺点。通过分析不同模块的演进和关键技术,为未来的研究方向提供了指导。
关键设计:论文重点关注了强化学习在GUI Agent训练中的应用,包括奖励函数的设计、状态表示的选择、以及RL算法的选择。例如,奖励函数可以设计为基于任务完成情况的稀疏奖励,或者基于中间步骤的密集奖励。状态表示可以包括GUI的视觉信息、文本信息和Agent的历史动作等。RL算法可以选择基于值函数的算法(如Q-learning)或基于策略梯度的算法(如REINFORCE)。
🖼️ 关键图片

📊 实验亮点
论文总结了GUI Agent训练方法,强调了从Prompt工程到动态策略学习的进展,并分析了多模态感知、决策推理和自适应行动生成方面的最新创新如何显著提高GUI Agent在复杂真实环境中的泛化性和鲁棒性。具体性能数据和提升幅度在论文中未明确给出,属于综述性质。
🎯 应用场景
该研究成果可应用于自动化测试、智能助手、无障碍辅助等领域。例如,可以开发能够自动完成复杂任务的GUI Agent,提高工作效率;也可以为残疾人士提供更便捷的计算机操作方式。未来,随着技术的不断发展,GUI Agent有望在更多领域发挥重要作用。
📄 摘要(原文)
Graphical User Interface (GUI) agents, driven by Multi-modal Large Language Models (MLLMs), have emerged as a promising paradigm for enabling intelligent interaction with digital systems. This paper provides a structured survey of recent advances in GUI agents, focusing on architectures enhanced by Reinforcement Learning (RL). We first formalize GUI agent tasks as Markov Decision Processes and discuss typical execution environments and evaluation metrics. We then review the modular architecture of (M)LLM-based GUI agents, covering Perception, Planning, and Acting modules, and trace their evolution through representative works. Furthermore, we categorize GUI agent training methodologies into Prompt-based, Supervised Fine-Tuning (SFT)-based, and RL-based approaches, highlighting the progression from simple prompt engineering to dynamic policy learning via RL. Our summary illustrates how recent innovations in multimodal perception, decision reasoning, and adaptive action generation have significantly improved the generalization and robustness of GUI agents in complex real-world environments. We conclude by identifying key challenges and future directions for building more capable and reliable GUI agents.