What's Pulling the Strings? Evaluating Integrity and Attribution in AI Training and Inference through Concept Shift
作者: Jiamin Chang, Haoyang Li, Hammond Pearce, Ruoxi Sun, Bo Li, Minhui Xue
分类: cs.CR, cs.AI, cs.LG
发布日期: 2025-04-28 (更新: 2025-07-16)
备注: Accepted to The ACM Conference on Computer and Communications Security (CCS) 2025
💡 一句话要点
ConceptLens:通过概念漂移评估AI训练和推理中的完整性和归因问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 概念漂移 AI安全 数据投毒 偏见检测 多模态学习 可信AI 模型评估
📋 核心要点
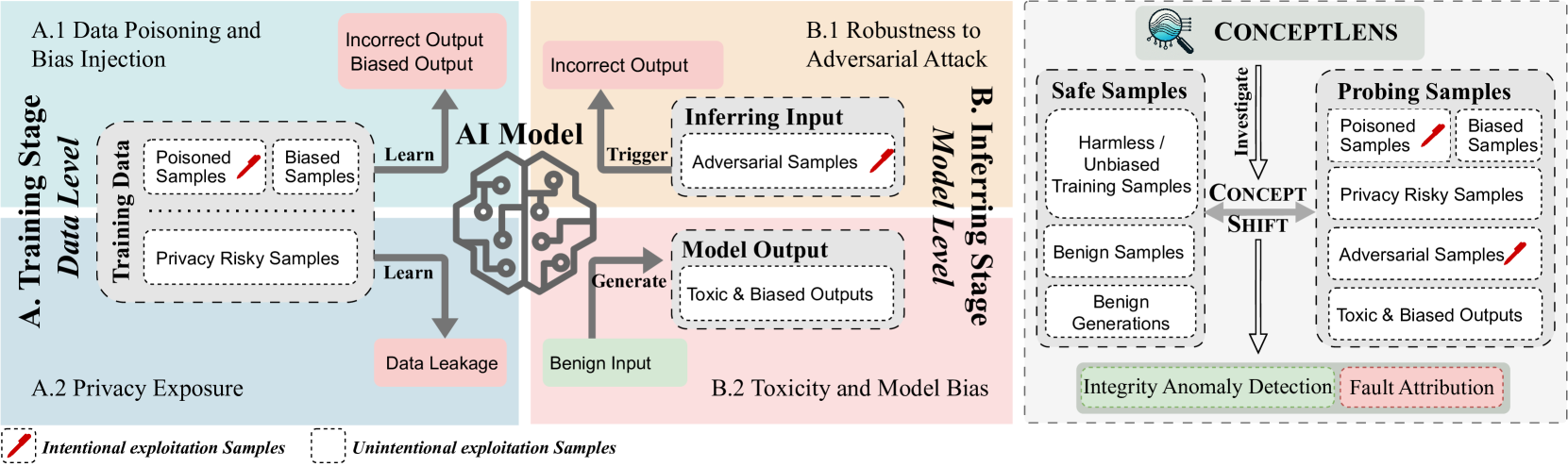
- 现有AI系统面临完整性、隐私、鲁棒性和偏见等可信度挑战,缺乏有效评估和归因这些威胁的通用框架。
- ConceptLens利用预训练多模态模型分析探测样本中的概念漂移,从而识别完整性威胁的根本原因。
- ConceptLens在检测数据投毒攻击、识别偏见注入漏洞、揭示隐私风险和模型弱点等方面表现出色。
📝 摘要(中文)
人工智能的日益普及引发了对可信度的担忧,包括完整性、隐私、鲁棒性和偏见。为了评估和归因这些威胁,我们提出了ConceptLens,这是一个通用框架,它利用预训练的多模态模型,通过分析探测样本中的概念漂移来识别完整性威胁的根本原因。ConceptLens在原始数据投毒攻击中表现出强大的检测性能,并揭示了偏见注入的漏洞,例如通过恶意概念漂移生成隐蔽广告。它识别未经修改但高风险样本中的隐私风险,在训练前对其进行过滤,并深入了解由不完整或不平衡的训练数据引起的模型弱点。此外,在模型层面,它可以归因目标模型过度依赖的概念,识别误导性概念,并解释破坏关键概念如何对模型产生负面影响。此外,它还揭示了生成内容中的社会学偏见,揭示了不同社会学背景下的差异。值得注意的是,ConceptLens揭示了如何无意中且容易地利用安全的训练和推理数据,从而可能破坏安全对齐。我们的研究为培养对人工智能系统的信任提供了可操作的见解,从而加速了采用并推动了更大的创新。
🔬 方法详解
问题定义:论文旨在解决AI模型训练和推理过程中存在的完整性、隐私、鲁棒性和偏见等问题。现有方法在评估和归因这些威胁时缺乏通用性和有效性,难以深入分析潜在的根本原因。例如,数据投毒攻击、偏见注入以及隐私泄露等问题难以被有效检测和溯源。
核心思路:论文的核心思路是利用预训练的多模态模型来分析“概念漂移”。通过向模型输入特定的探测样本,观察模型在不同概念上的表现差异,从而识别潜在的威胁来源。概念漂移是指模型在处理相似输入时,由于受到恶意影响(例如数据投毒)或固有偏见,对某些概念的理解和判断发生偏差的现象。
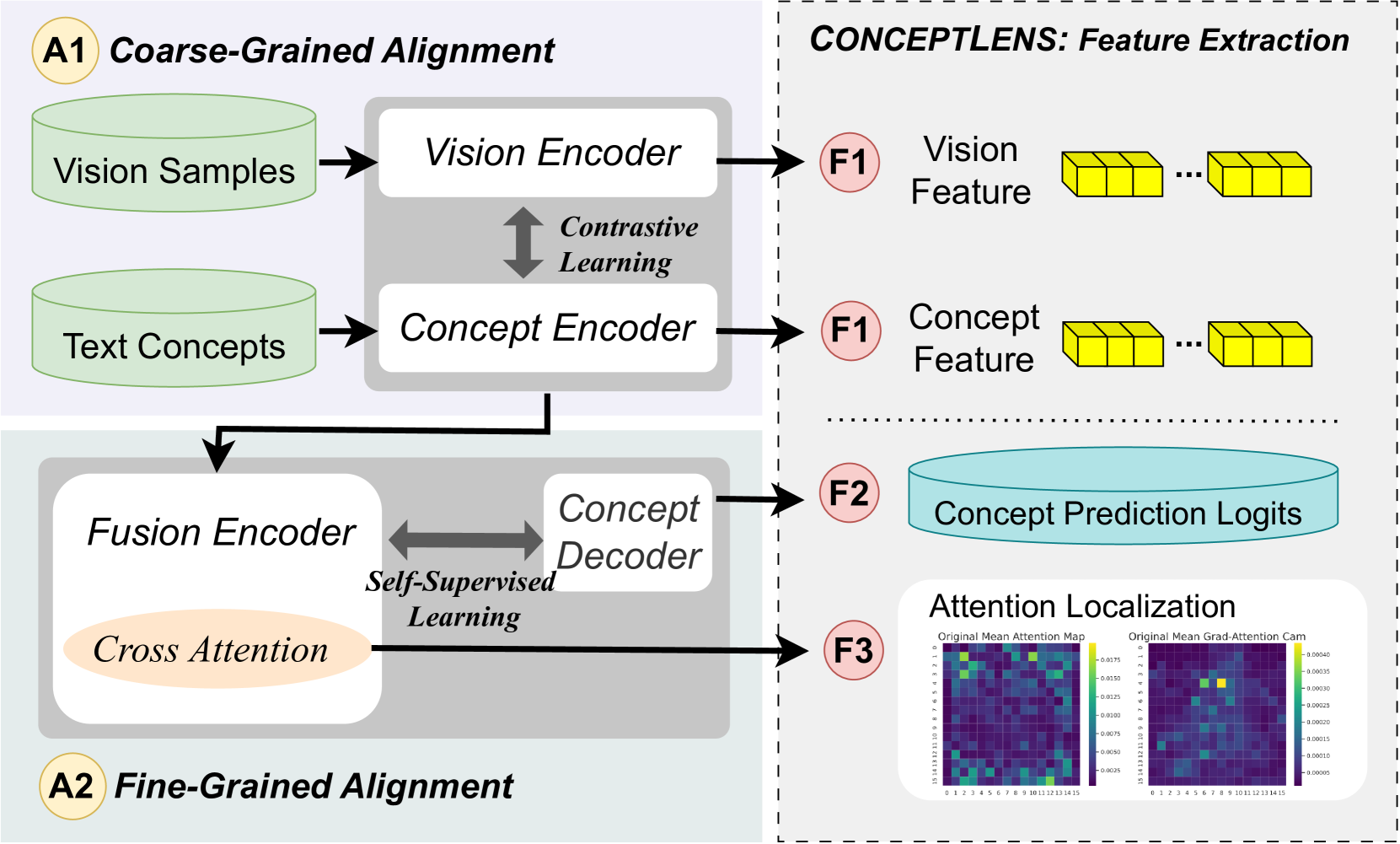
技术框架:ConceptLens框架主要包含以下几个阶段:1) 探测样本生成:生成包含特定概念的探测样本,用于触发模型潜在的弱点或漏洞。2) 多模态模型分析:利用预训练的多模态模型(例如CLIP)提取探测样本的特征表示,并分析模型在不同概念上的响应。3) 概念漂移检测:通过比较模型在正常样本和受影响样本上的概念表示差异,检测是否存在概念漂移。4) 威胁归因:根据概念漂移的模式和特征,将威胁归因于特定的原因,例如数据投毒、偏见注入或隐私泄露。
关键创新:ConceptLens的关键创新在于其通用性和可解释性。它不依赖于特定的模型或任务,可以应用于各种AI系统,并提供对威胁根本原因的深入分析。与传统的黑盒测试方法不同,ConceptLens通过分析概念层面的变化,揭示了模型内部的脆弱性和潜在风险。此外,该方法能够识别和量化模型对特定概念的依赖程度,从而为模型改进和安全加固提供指导。
关键设计:ConceptLens的关键设计包括:1) 多模态特征提取:利用预训练的CLIP模型提取图像和文本特征,实现跨模态的概念表示。2) 概念漂移度量:设计合适的度量指标来量化模型在不同概念上的表示差异,例如余弦相似度或KL散度。3) 威胁归因算法:开发基于规则或机器学习的算法,根据概念漂移的模式和特征,将威胁归因于特定的原因。4) 敏感性分析:分析模型对不同概念的敏感性,识别容易被利用的脆弱概念。
🖼️ 关键图片
📊 实验亮点
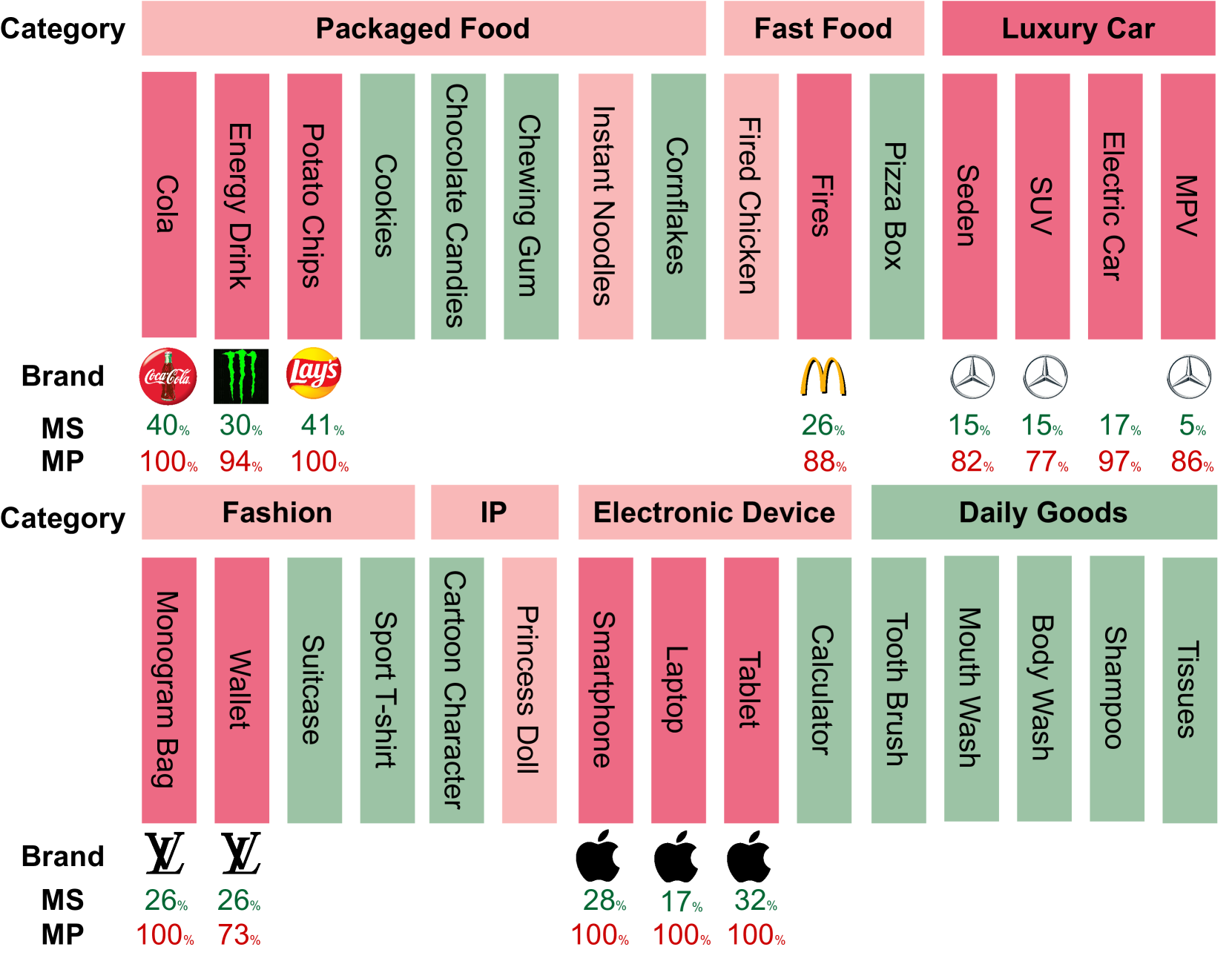
ConceptLens在数据投毒攻击检测方面表现出强大的性能,能够有效识别恶意概念漂移。实验表明,ConceptLens能够揭示模型对特定概念的过度依赖,并识别误导性概念。此外,ConceptLens还能够发现生成内容中的社会学偏见,揭示不同社会学背景下的差异。这些结果表明,即使是看似安全的训练和推理数据也可能被轻易利用,从而威胁AI系统的安全性。
🎯 应用场景
ConceptLens可广泛应用于AI系统的安全评估、风险管理和可信度提升。例如,在自动驾驶领域,可以用于检测数据投毒攻击,确保感知系统的安全性;在金融风控领域,可以用于识别偏见注入,避免歧视性决策;在医疗诊断领域,可以用于评估模型的鲁棒性,防止误诊。该研究有助于构建更安全、可靠和公平的AI系统。
📄 摘要(原文)
The growing adoption of artificial intelligence (AI) has amplified concerns about trustworthiness, including integrity, privacy, robustness, and bias. To assess and attribute these threats, we propose ConceptLens, a generic framework that leverages pre-trained multimodal models to identify the root causes of integrity threats by analyzing Concept Shift in probing samples. ConceptLens demonstrates strong detection performance for vanilla data poisoning attacks and uncovers vulnerabilities to bias injection, such as the generation of covert advertisements through malicious concept shifts. It identifies privacy risks in unaltered but high-risk samples, filters them before training, and provides insights into model weaknesses arising from incomplete or imbalanced training data. Additionally, at the model level, it attributes concepts that the target model is overly dependent on, identifies misleading concepts, and explains how disrupting key concepts negatively impacts the model. Furthermore, it uncovers sociological biases in generative content, revealing disparities across sociological contexts. Strikingly, ConceptLens reveals how safe training and inference data can be unintentionally and easily exploited, potentially undermining safety alignment. Our study informs actionable insights to breed trust in AI systems, thereby speeding adoption and driving greater innovation.