Understanding and supporting how developers prompt for LLM-powered code editing in practice
作者: Daye Nam, Ahmed Omran, Ambar Murillo, Saksham Thakur, Abner Araujo, Marcel Blistein, Alexander Frömmgen, Vincent Hellendoorn, Satish Chandra
分类: cs.SE, cs.AI, cs.HC
发布日期: 2025-04-28 (更新: 2025-12-19)
💡 一句话要点
通过分析开发者提示行为,提出AutoPrompter以提升LLM代码编辑的准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM代码编辑 提示工程 代码上下文 自动化提示 软件工程 IDE插件 开发者工具
📋 核心要点
- 现有研究对LLM代码编辑工具的开发者使用情况理解不足,尤其是在开发者遇到困难时的具体表现。
- 论文提出AutoPrompter,通过分析代码上下文自动补全开发者提示中的缺失信息,从而改进LLM代码编辑的准确性。
- 实验结果表明,AutoPrompter能够显著提升代码编辑的正确性,在测试集上实现了27%的提升。
📝 摘要(中文)
大型语言模型(LLMs)正在迅速改变软件工程,嵌入在IDE中的编码助手变得越来越普遍。虽然研究主要集中在改进工具和理解开发者的看法,但理解开发者如何在日常工作流程中实际使用这些工具,以及他们在哪里遇到困难,仍然存在一个关键的差距。本文通过对开发者与LLM驱动的代码编辑功能(Transform Code)的交互进行多阶段调查,解决了这一差距的一部分。首先,我们分析了该功能的使用遥测日志,发现频繁的重新提示可能是开发者在使用Transform Code时遇到困难的指标。其次,我们对不令人满意的请求进行了定性分析,确定了开发者提示中经常缺失的五个关键信息类别。最后,基于这些发现,我们提出并评估了一个工具AutoPrompter,用于通过从周围代码上下文中推断缺失的信息来自动改进提示,从而在我们的测试集中实现了27%的编辑正确性提升。
🔬 方法详解
问题定义:论文旨在解决开发者在使用LLM驱动的代码编辑工具时,由于提示信息不足或不准确,导致编辑结果不符合预期的问题。现有方法主要集中在改进LLM本身或提供更通用的代码补全建议,而忽略了开发者实际的提示行为和需求,导致开发者需要频繁地重新提示,效率低下。
核心思路:论文的核心思路是通过分析开发者在使用LLM代码编辑工具时的提示行为,识别出提示中常见的缺失信息,并利用代码上下文自动补全这些信息,从而提高LLM生成代码的准确性和效率。这种方法的核心在于理解开发者的意图,并将其转化为更清晰、更完整的提示。
技术框架:论文的技术框架主要包括三个阶段:1) 遥测数据分析:分析Transform Code功能的使用日志,识别频繁重新提示的模式;2) 定性分析:对不令人满意的请求进行人工分析,总结出提示中常见的五类缺失信息;3) AutoPrompter设计与评估:基于前两个阶段的发现,设计AutoPrompter工具,并进行实验评估。AutoPrompter的核心模块是上下文分析器,用于从周围代码中提取相关信息,并将其添加到原始提示中。
关键创新:论文的关键创新在于提出了AutoPrompter,一个能够自动补全LLM代码编辑提示的工具。与现有方法相比,AutoPrompter不是直接改进LLM本身,而是通过改善输入提示的质量来提高输出结果的准确性。这种方法更贴近开发者的实际使用场景,也更容易集成到现有的IDE中。
关键设计:AutoPrompter的关键设计包括:1) 上下文分析器的设计,需要准确地从代码上下文中提取相关信息,例如变量类型、函数签名等;2) 提示补全策略的设计,需要确定如何将提取的信息添加到原始提示中,以最大程度地提高LLM的理解能力;3) 实验评估的设计,需要选择合适的测试集和评估指标,以客观地评估AutoPrompter的性能。
🖼️ 关键图片


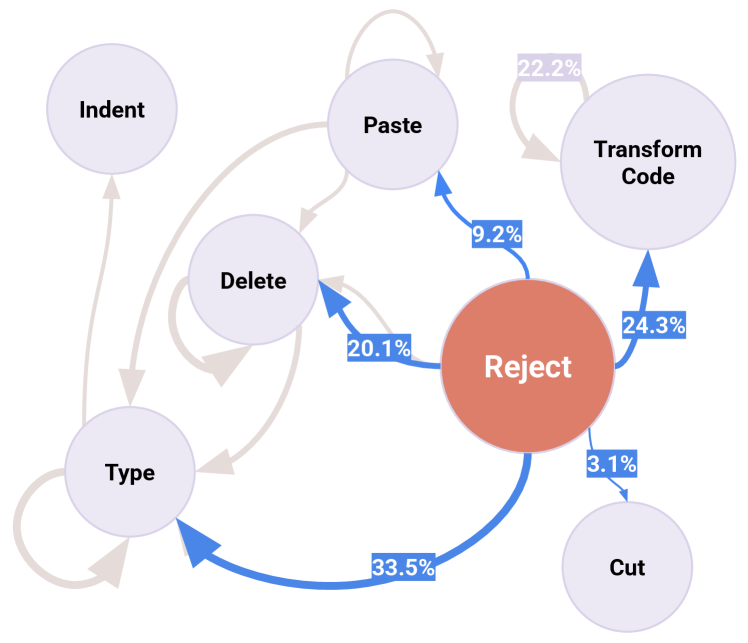
📊 实验亮点
实验结果表明,AutoPrompter能够显著提升代码编辑的正确性,在测试集上实现了27%的提升。这一结果表明,通过改善输入提示的质量,可以有效地提高LLM在代码编辑任务中的性能。此外,论文还对开发者提示中常见的缺失信息进行了分类,为后续研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于各种基于LLM的代码编辑工具,例如IDE插件、代码审查工具等。通过自动补全提示信息,可以显著提高开发者的编码效率和代码质量,降低开发成本。未来,该技术还可以扩展到其他自然语言编程任务,例如代码生成、代码翻译等。
📄 摘要(原文)
Large Language Models (LLMs) are rapidly transforming software engineering, with coding assistants embedded in an IDE becoming increasingly prevalent. While research has focused on improving the tools and understanding developer perceptions, a critical gap exists in understanding how developers actually use these tools in their daily workflows, and, crucially, where they struggle. This paper addresses part of this gap through a multi-phased investigation of developer interactions with an LLM-powered code editing feature, Transform Code, in an IDE widely used at Google. First, we analyze telemetry logs of the feature usage, revealing that frequent re-prompting can be an indicator of developer struggles with using Transform Code. Second, we conduct a qualitative analysis of unsatisfactory requests, identifying five key categories of information often missing from developer prompts. Finally, based on these findings, we propose and evaluate a tool, AutoPrompter, for automatically improving prompts by inferring missing information from the surrounding code context, leading to a 27% improvement in edit correctness on our test set.