Pediatric Asthma Detection with Googles HeAR Model: An AI-Driven Respiratory Sound Classifier
作者: Abul Ehtesham, Saket Kumar, Aditi Singh, Tala Talaei Khoei
分类: cs.SD, cs.AI
发布日期: 2025-04-28
💡 一句话要点
利用谷歌HeAR模型,AI驱动的呼吸音分类器用于儿童哮喘早期检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 儿童哮喘检测 呼吸音分类 健康声学表征 预训练模型 深度学习
📋 核心要点
- 儿童哮喘的早期检测至关重要,但现有方法在处理低资源音频数据和泛化性方面存在挑战。
- 本研究利用在海量健康音频数据上预训练的谷歌HeAR模型,提取儿童呼吸音的有效表征。
- 实验结果表明,该方法在哮喘检测中取得了超过91%的准确率,具有很高的临床应用潜力。
📝 摘要(中文)
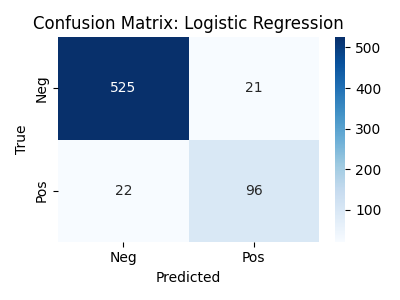
本研究提出了一种基于AI的诊断流程,利用谷歌的健康声学表征(HeAR)模型,从儿童呼吸音中检测哮喘的早期迹象。研究使用了SPRSound数据集,这是首个开放获取的儿童(1个月至18岁)带标注呼吸音数据集。该数据集被分割成2秒的音频片段,并标注为喘息、啰音、干啰音、哮鸣音或正常。每个片段通过HeAR模型嵌入到512维的向量空间中。HeAR是一个在3亿健康相关音频片段(包括1亿咳嗽声)上预训练的基础模型。研究在这些嵌入向量上训练了多种分类器,包括SVM、随机森林和MLP,以区分哮喘相关和正常的声音。该系统实现了超过91%的准确率,并在精确率-召回率指标上表现出色。除了分类,还使用PCA可视化了学习到的嵌入,通过波形回放分析了错误分类,并提供了ROC曲线和混淆矩阵的分析。该方法表明,在基础音频模型的支持下,短时、低资源的儿科录音能够实现快速、无创的哮喘筛查,尤其适用于偏远或医疗服务不足地区的数字诊断。
🔬 方法详解
问题定义:本研究旨在解决儿童哮喘的早期检测问题。现有方法可能依赖于复杂的设备或需要专业医生的评估,且在处理噪声环境下的低质量音频数据时表现不佳。此外,缺乏大规模带标注的儿科呼吸音数据集也限制了模型的训练和泛化能力。
核心思路:核心思路是利用预训练的健康声学表征模型(HeAR)从呼吸音中提取高质量的特征,从而克服数据稀缺和噪声干扰的问题。HeAR模型在大规模健康相关音频数据上进行了预训练,能够学习到通用的音频特征表示,从而提高模型在小样本数据集上的泛化能力。
技术框架:整体流程包括:1) 数据预处理:将SPRSound数据集中的呼吸音片段分割成2秒的音频段,并进行标注;2) 特征提取:使用HeAR模型将每个音频段嵌入到512维的向量空间中;3) 分类器训练:在提取的特征上训练SVM、随机森林和MLP等分类器;4) 模型评估:使用准确率、精确率、召回率、ROC曲线和混淆矩阵等指标评估模型的性能。
关键创新:关键创新在于将预训练的健康声学表征模型应用于儿童哮喘检测。与传统的特征工程方法相比,HeAR模型能够自动学习到更具判别性的特征表示,从而提高分类性能。此外,该研究使用了SPRSound数据集,为儿科呼吸音研究提供了宝贵的数据资源。
关键设计:HeAR模型是一个基于Transformer的自监督学习模型,在大规模健康相关音频数据上进行了预训练。研究中使用了HeAR模型提取的512维嵌入向量作为分类器的输入特征。分类器采用了默认的参数设置,并通过交叉验证选择最优模型。损失函数根据分类任务选择,例如交叉熵损失函数。
🖼️ 关键图片


📊 实验亮点
该研究利用HeAR模型在SPRSound数据集上实现了超过91%的哮喘检测准确率。与传统的特征工程方法相比,该方法能够自动学习到更具判别性的特征表示,从而提高了分类性能。此外,研究还对错误分类进行了分析,并提供了ROC曲线和混淆矩阵等可视化结果,为模型的改进提供了依据。
🎯 应用场景
该研究成果可应用于开发移动健康应用或远程医疗平台,实现儿童哮喘的早期筛查和诊断。特别是在医疗资源匮乏的偏远地区,该方法可以为基层医疗机构提供一种低成本、非侵入性的哮喘检测手段,从而改善儿童的呼吸健康状况。未来,该技术还可以扩展到其他呼吸系统疾病的诊断。
📄 摘要(原文)
Early detection of asthma in children is crucial to prevent long-term respiratory complications and reduce emergency interventions. This work presents an AI-powered diagnostic pipeline that leverages Googles Health Acoustic Representations (HeAR) model to detect early signs of asthma from pediatric respiratory sounds. The SPRSound dataset, the first open-access collection of annotated respiratory sounds in children aged 1 month to 18 years, is used to extract 2-second audio segments labeled as wheeze, crackle, rhonchi, stridor, or normal. Each segment is embedded into a 512-dimensional representation using HeAR, a foundation model pretrained on 300 million health-related audio clips, including 100 million cough sounds. Multiple classifiers, including SVM, Random Forest, and MLP, are trained on these embeddings to distinguish between asthma-indicative and normal sounds. The system achieves over 91\% accuracy, with strong performance on precision-recall metrics for positive cases. In addition to classification, learned embeddings are visualized using PCA, misclassifications are analyzed through waveform playback, and ROC and confusion matrix insights are provided. This method demonstrates that short, low-resource pediatric recordings, when powered by foundation audio models, can enable fast, noninvasive asthma screening. The approach is especially promising for digital diagnostics in remote or underserved healthcare settings.