PlanetServe: A Decentralized, Scalable, and Privacy-Preserving Overlay for Democratizing Large Language Model Serving
作者: Fei Fang, Yifan Hua, Shengze Wang, Ruilin Zhou, Yi Liu, Chen Qian, Xiaoxue Zhang
分类: cs.DC, cs.AI
发布日期: 2025-04-27 (更新: 2025-12-11)
💡 一句话要点
PlanetServe:提出GenTorrent,实现去中心化、可扩展且保护隐私的大语言模型服务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型服务 去中心化网络 隐私保护 覆盖网络 可扩展性
📋 核心要点
- 现有LLM服务面临可扩展性瓶颈,尤其对于资源有限的组织和个人,部署和测试LLM创新面临挑战。
- GenTorrent利用去中心化节点构建LLM服务覆盖网络,旨在提高吞吐量和可用性,实现资源高效利用。
- 原型实验表明,GenTorrent相比基线设计延迟降低超过50%,且安全特性引入的开销极小。
📝 摘要(中文)
随着开源和高性价比的大语言模型(LLM)在研究和开发方面取得了显著进展,服务可扩展性仍然是一个关键挑战,特别是对于希望部署和测试其LLM创新成果的小型组织和个人而言。受对等网络利用去中心化覆盖节点来提高吞吐量和可用性的启发,我们提出了GenTorrent,一种LLM服务覆盖网络,利用来自去中心化贡献者的计算资源。我们确定了实现这种去中心化基础设施所固有的四个关键研究问题:1) 覆盖网络组织;2) LLM通信隐私;3) 用于资源效率的覆盖转发;以及 4) 服务质量验证。这项工作首次系统地研究了去中心化LLM服务背景下的这些基本问题。在去中心化节点集上实现的prototype的评估结果表明,与没有覆盖转发的基线设计相比,GenTorrent实现了超过50%的延迟降低。此外,安全特性对服务延迟和吞吐量的影响很小。我们相信这项工作为普及和扩展未来的AI服务能力开辟了一个新的方向。
🔬 方法详解
问题定义:论文旨在解决大规模语言模型(LLM)服务在去中心化场景下的可扩展性、隐私性和资源效率问题。现有中心化LLM服务架构成本高昂,小型组织和个人难以负担。同时,直接在对等网络上部署LLM服务面临隐私泄露和服务质量难以保证的挑战。
核心思路:论文的核心思路是构建一个去中心化的LLM服务覆盖网络(GenTorrent),通过利用分布式节点的计算资源来提高整体服务能力。该网络通过覆盖转发机制优化资源利用率,并采用隐私保护技术来防止LLM通信内容泄露。同时,设计了服务质量验证机制,确保服务可靠性。
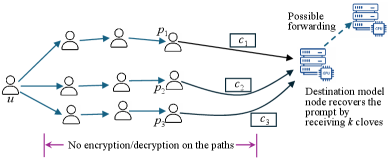
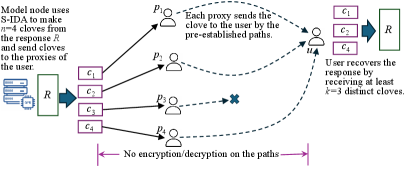
技术框架:GenTorrent的技术框架包含以下几个主要模块:1) 覆盖网络组织:负责构建和维护去中心化的覆盖网络,选择合适的节点参与服务。2) LLM通信隐私:采用加密技术保护LLM请求和响应的内容,防止中间节点窃取信息。3) 覆盖转发:优化请求在覆盖网络中的转发路径,减少延迟和资源消耗。4) 服务质量验证:验证节点提供的服务质量,防止恶意节点提供错误或低质量的响应。整个流程为:客户端发起请求,请求通过覆盖网络转发到合适的LLM服务节点,服务节点处理请求并将结果通过覆盖网络返回给客户端。
关键创新:该论文的关键创新在于首次系统性地研究了去中心化LLM服务中的覆盖网络组织、通信隐私、覆盖转发和服务质量验证等问题,并提出了相应的解决方案。与现有中心化LLM服务相比,GenTorrent具有更高的可扩展性和更低的成本。与直接在对等网络上部署LLM服务相比,GenTorrent提供了更好的隐私保护和服务质量保证。
关键设计:论文中关于覆盖转发的关键设计包括:选择合适的路由算法,例如基于延迟或带宽的路由算法,以优化请求的转发路径。关于隐私保护的关键设计包括:使用同态加密或差分隐私等技术来保护LLM请求和响应的内容。关于服务质量验证的关键设计包括:定期对节点进行服务质量测试,例如通过发送预定义的请求并验证响应的正确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与没有覆盖转发的基线设计相比,GenTorrent实现了超过50%的延迟降低。同时,论文指出安全特性对服务延迟和吞吐量的影响很小,表明该方案在保证隐私的同时,能够维持较高的服务性能。这些结果验证了GenTorrent在去中心化LLM服务方面的有效性。
🎯 应用场景
该研究成果可应用于构建低成本、高可用的去中心化LLM服务平台,赋能小型组织和个人进行LLM创新。例如,可以用于构建去中心化的AI助手、个性化教育平台、以及隐私保护的医疗诊断系统。未来,该技术有望推动AI服务的普及化和民主化。
📄 摘要(原文)
While significant progress has been made in research and development on open-source and cost-efficient large-language models (LLMs), serving scalability remains a critical challenge, particularly for small organizations and individuals seeking to deploy and test their LLM innovations. Inspired by peer-to-peer networks that leverage decentralized overlay nodes to increase throughput and availability, we propose GenTorrent, an LLM serving overlay that harnesses computing resources from decentralized contributors. We identify four key research problems inherent to enabling such a decentralized infrastructure: 1) overlay network organization; 2) LLM communication privacy; 3) overlay forwarding for resource efficiency; and 4) verification of serving quality. This work presents the first systematic study of these fundamental problems in the context of decentralized LLM serving. Evaluation results from a prototype implemented on a set of decentralized nodes demonstrate that GenTorrent achieves a latency reduction of over 50% compared to the baseline design without overlay forwarding. Furthermore, the security features introduce minimal overhead to serving latency and throughput. We believe this work pioneers a new direction for democratizing and scaling future AI serving capabilities.